

AliMei Guide: As the main product of Alibaba in the field of idle circulation, Xianyu mainly develops mobile applications to solve the problem of re-circulation of idle goods/assets/time in personal domains, utilizing cross-end technologies (Base Flutter/Weex/Dart technology stack) and computer vision technologies (Base Tensorflow Lite) in cutting-edge practices on mobile terminals.
This article is produced by the Xianyu technical team. In response to the problems of latency and resource consumption in server-side voice recognition, this article proposes a voice recognition solution based on the tensorflowLite framework on the client side. Let’s delve into it together.
Author: Tong Hui, Shang Ye
Abstract
Most existing voice recognition is implemented on the server side, which brings two main problems:
1) Poor network conditions can cause significant latency, leading to a poor user experience.
2) High traffic can consume a large amount of server resources.
To solve these two problems, we chose to implement voice recognition functionality on the client side. This article uses machine learning methods to recognize voice. The framework used is Google’s tensorflowLite framework, which is compact as its name suggests. While ensuring accuracy, the size of the framework is only about 300KB, and the model generated after compression is one-fourth of the tensorflow model. Therefore, the tensorflowLite framework is relatively suitable for use on the client side.
To improve the recognition rate of voice, audio features need to be extracted as input samples for the machine learning framework. The feature extraction algorithm used in this article is the Mel-frequency cepstral algorithm based on the auditory mechanism of the human ear.
Due to the time-consuming nature of voice recognition on the client side, many optimizations need to be made in engineering, as follows:
1) Instruction set acceleration: Introduce the ARM instruction set, optimize multiple instruction sets, and accelerate calculations.
2) Multithreading acceleration: Use multithreading for concurrent processing of time-consuming calculations.
3) Model acceleration: Choose models that support NEON optimization and pre-load models to reduce preprocessing time.
4) Algorithm acceleration: I) Lower the audio sampling rate. II) Select the human voice frequency band (20Hz~20kHz) and eliminate non-human voice frequency bands. III) Reasonable windowing and slicing to prevent over-calculation. IV) Silence detection to reduce unnecessary time segments.
1. Overview
1.1 Voice Recognition Application Scenarios
The voice recognition method proposed in this article has the following general usage scenarios:
1) Audio and video quality analysis: Determine whether there is human voice, silence during calls, screeching sounds, background noise, etc.
2) Recognize specific sounds: Identify whether it is a specific person’s voice, used for voice unlocking, remote identity authentication, etc.
3) Emotion recognition: Used to determine the speaker’s emotions and state. The combination of voiceprint with content and emotional information can effectively prevent voiceprint forgery and personal coercion.
4) Gender identification: Can identify whether the voice is male or female.
1.2 Voice Recognition Process
Voice recognition is divided into two parts: training and prediction. Training refers to generating the prediction model, while prediction is using the model to produce prediction results.
First, let’s introduce the training process, which is divided into the following three parts:
1) Based on the Mel-frequency cepstral algorithm, extract sound features and convert them into spectrogram images.
2) Use human voice spectrograms as positive samples, and non-human sounds such as animal noises and background noise as negative samples for training by the neural network model.
3) Based on the files generated from training, create a prediction model that can run on the device.
In summary, the training process of voice recognition is divided into three parts: extracting sound features, model training, and generating the model on the device. Finally, for voice recognition: first extract sound features, then load the training model to obtain prediction results.
1.3 Artificial Intelligence Framework
In November 2017, Google announced the launch of TensorFlow Lite at the I/O conference, which is a lightweight solution for TensorFlow for mobile and embedded devices. It can run on multiple platforms, from rack servers to small IoT devices. However, with the widespread use of machine learning models in recent years, there has been a demand for deploying them on mobile and embedded devices. TensorFlow Lite allows for low-latency inference of machine learning models on the device side.
The tensorflowLite framework used in this article is an artificial intelligence learning system developed by Google, named after its operating principle. Tensor (张量) refers to N-dimensional arrays, while Flow (流) refers to computations based on data flow graphs. TensorFlow represents the process of tensors flowing from one end of the flow graph to the other for computation. TensorFlow is a system for transmitting complex data structures to artificial intelligence neural networks for analysis and processing.
The following image shows the architectural design of tensorflowLite:
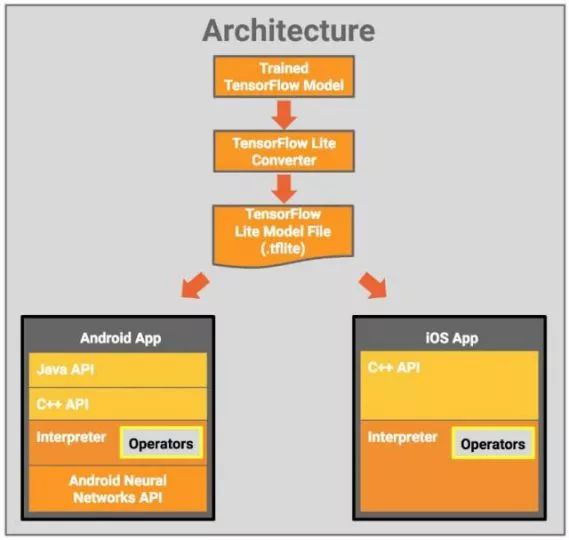
Figure 1.1 TensorFlow Lite Architecture
2. Mel-frequency Cepstral Algorithm
2.1 Overview
The algorithm for sound recognition in this chapter—the Mel-frequency cepstral algorithm—is divided into several steps, which will be detailed in subsequent sections.
1) Input the sound file and parse it into raw sound data (time-domain signal).
2) Use short-time Fourier transform to window and frame the time-domain signal into a frequency-domain signal.
3) Through Mel-frequency transformation, convert the frequency into a linear relationship perceivable by the human ear.
4) Use Mel-cepstral analysis to separate the DC signal component and the sinusoidal signal component using DCT transformation.
5) Extract sound spectrum feature vectors and convert the vectors into images.
Windowing and framing are done to satisfy the short-term stationary characteristics of speech in the time domain, while Mel-frequency transformation converts the human ear’s frequency perception into a linear relationship. The key to cepstral analysis is understanding Fourier transformation; any signal can be decomposed into a DC component and a sum of several sinusoidal signals through Fourier transformation.
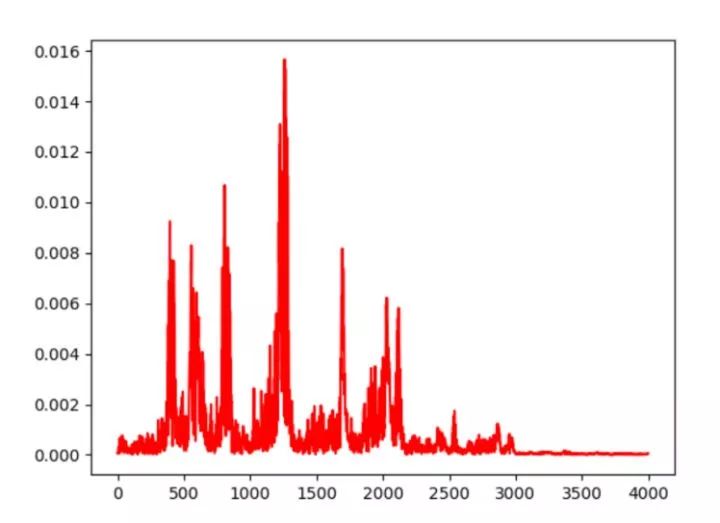
Figure 2.1 Time-domain Signal of Sound
Figure 2.1 shows the time-domain signal of sound, which makes it difficult to visually discern frequency variations. Figure 2.2 shows the frequency-domain signal, reflecting information about sound volume and frequency. Figure 2.3 shows the sound features after Mel-cepstral processing, which can extract sound.
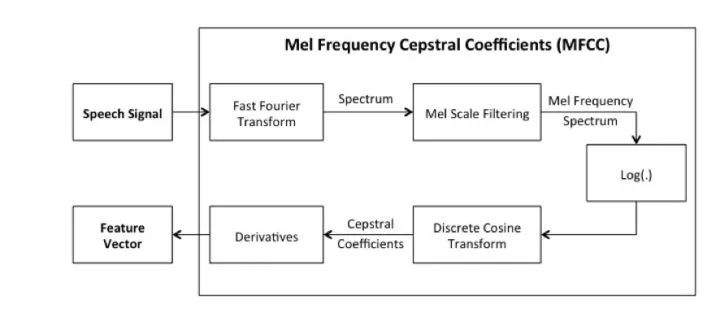
Figure 2.2 Frequency-domain Signal of Sound
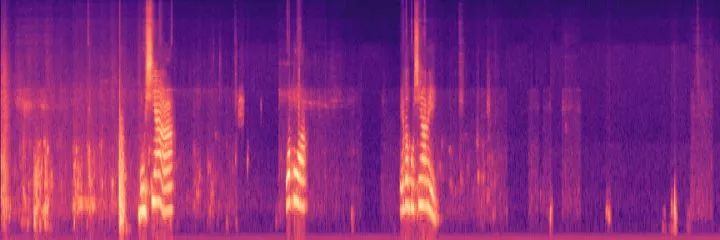
Figure 2.3 Cepstral Features of Sound
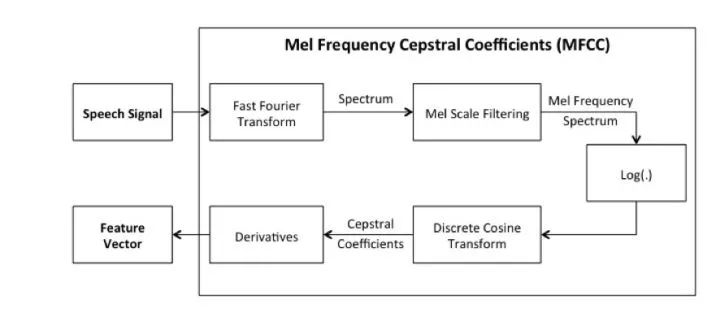
Figure 2.4 Process Flow of Mel Cepstral Algorithm
2.2 Short-time Fourier Transform
Sound signals are one-dimensional time-domain signals, making it difficult to visually discern frequency variations. If transformed into the frequency domain using Fourier transformation, the frequency distribution of the signal can be observed, but temporal information is lost, preventing one from seeing how frequency distribution changes over time. To solve this problem, many time-frequency analysis methods have emerged, including short-time Fourier transform, wavelet transform, and Wigner distribution.
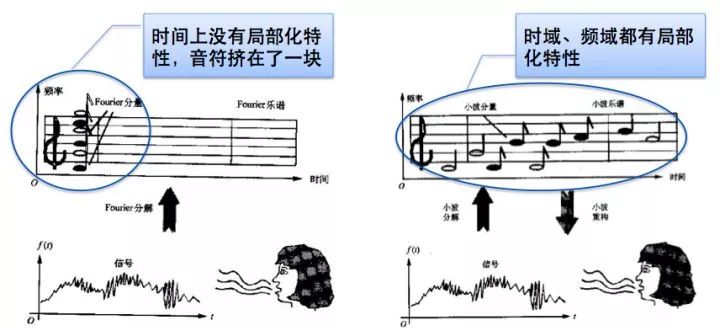
Figure 2.5 FFT and STFT Transformation Diagram
Through Fourier transformation, the frequency spectrum of the signal can be obtained. The application of the signal’s frequency spectrum is very broad; both signal compression and noise reduction can be based on frequency spectrum. However, Fourier transformation has one assumption: the signal is stationary, meaning its statistical properties do not change over time. Sound signals are not stationary; many signals may appear and then disappear over a long period. If all these signals are transformed using Fourier transformation, they cannot reflect the sound changes over time.
The short-time Fourier transform (STFT) adopted in this article is the most classic time-frequency analysis method. The short-time Fourier transform (STFT) is a mathematical transformation related to Fourier transform (FT) used to determine the frequency and phase of sinusoidal waves in local areas of time-varying signals. Its idea is to select a localized window function in time-frequency, assuming the analysis window function h(t) is stationary within a short time interval, allowing f(t)h(t) to be stationary signals within different finite time widths, thereby calculating the power spectrum at different moments. The short-time Fourier transform uses a fixed window function, commonly using window functions like Hanning, Hamming, and Blackman-Harris. In this article, the Hamming window is used, which is a cosine window that can well reflect the energy decay relationship over time at a certain moment.
Therefore, the STFT formula in this article is based on the original Fourier transformation formula:
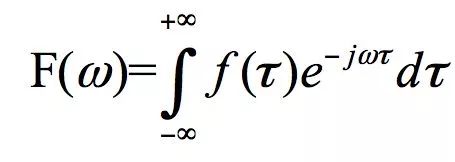
The formula has added a window function, thus the STFT formula transforms into
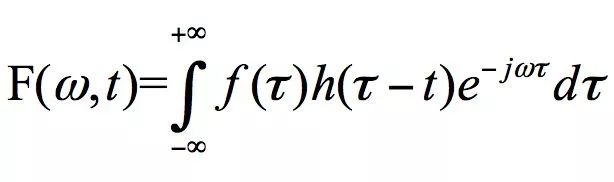
Where,
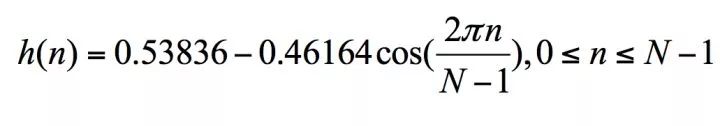
is the Hamming window function.
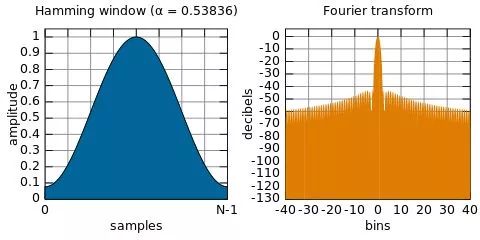
Figure 2.6 STFT Transformation Based on Hamming Window
2.3 Mel-frequency Spectrum
Spectrograms are often large images; to obtain appropriately sized sound features, they are often transformed into Mel-frequency spectra through a Mel-scale filter bank. What is a Mel filter bank? This begins with the Mel scale.
The Mel scale was named by Stevens, Volkmann, and Newman in 1937. We know that the unit of frequency is Hertz (Hz), and the frequency range that the human ear can hear is 20-20000Hz, but the human ear does not perceive the Hz scale linearly. For example, if we adapt to a tone of 1000Hz, if the frequency is increased to 2000Hz, our ears can only perceive a slight increase in frequency, hardly noticing that the frequency has doubled. If the ordinary frequency scale is converted to the Mel frequency scale, the mapping relationship is shown in the following formula:
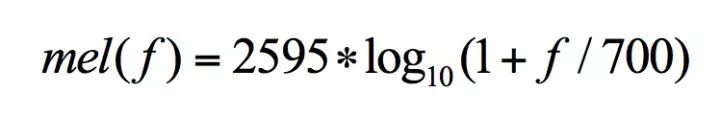
According to the above formula, the human ear’s perception of frequency becomes a linear relationship. In other words, under the Mel scale, if the Mel frequency of two segments of speech differs by a factor of two, the pitch that the human ear can perceive also differs by about a factor of two.
Let us observe the mapping from Hz to Mel frequency (mel); since they have a logarithmic relationship, when the frequency is low, the Mel frequency changes rapidly with Hz; when the frequency is high, the increase in Mel frequency is slow, and the slope of the curve is small. This illustrates that the human ear is more sensitive to low-frequency tones and less sensitive to high-frequency tones, and the Mel-scale filter bank is inspired by this.
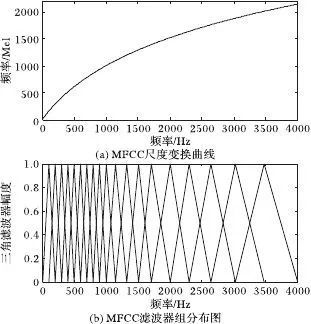
Figure 2.7 Frequency to Mel Frequency Mapping Diagram
As shown in the figure, the filter bank consists of 12 triangular filters, densely packed at low frequencies with high threshold values, while sparse at high frequencies with low threshold values. This corresponds to the objective law that the higher the frequency, the less sensitive the human ear becomes. The filter form shown in the figure is called the Mel filter bank with the same bank area, widely used in the field of human voice (speech recognition, speaker identification).
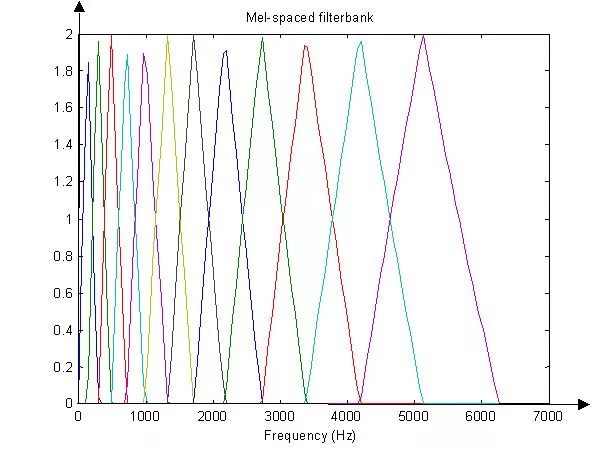
Figure 2.8 Mel Filter Bank Diagram
2.4 Mel-cepstrum
Based on the Mel logarithmic spectrum of section 2.3, the DCT transformation is used to separate the DC signal component and the sinusoidal signal component, resulting in what is known as the Mel-cepstrum.
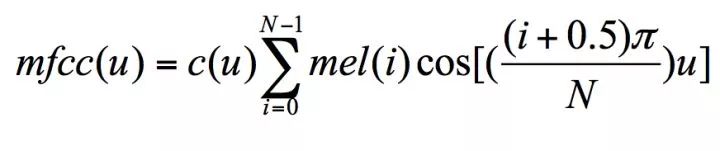
Where,
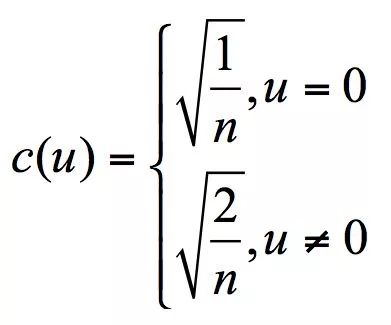
Since the Mel-cepstrum outputs a vector, it cannot be displayed as an image and needs to be converted into an image matrix. The output vector’s range needs to be linearly transformed to fit the image range.
Figure 2.9 Color Scale for Drawing
2.5 Algorithm Speed Optimization
Since the algorithm needs to be implemented on the client side, certain speed improvements are necessary. The optimizations are as follows:
1) Instruction set acceleration: Due to the algorithm’s extensive addition and multiplication matrix operations, the ARM instruction set is introduced to optimize multiple instruction sets, accelerating calculations. The speed can be improved by 4 to 8 times.
2) Algorithm acceleration: I) Select the human voice frequency band (20Hz~20kHz) and eliminate non-human voice frequency bands to reduce redundant calculations. II) Lower the audio sampling rate; since the human ear is insensitive to overly high sampling rates, reducing the sampling rate can decrease unnecessary data calculations. III) Reasonable windowing and slicing to prevent over-calculation. IV) Silence detection to reduce unnecessary time segments.
3) Sampling frequency acceleration: If the audio sampling frequency is too high, down-sampling is chosen, with the highest processing frequency set to 32kHz.
4) Multithreading acceleration: Split the audio into multiple segments and use multithreading for parallel processing. Configure the number of threads based on the machine’s capabilities, defaulting to four threads.

Figure 2.10 Parameters Selected for Algorithm Engineering
3. Voice Recognition Model
3.1 Model Selection
Convolutional Neural Networks (CNNs) are feedforward neural networks where artificial neurons can respond to surrounding units within a certain coverage area, demonstrating excellent performance in large image processing.
In the 1960s, Hubel and Wiesel discovered that the unique network structure used by neurons for local sensitivity and direction selectivity in the cat’s cerebral cortex could effectively reduce the complexity of feedback neural networks, leading to the proposal of convolutional neural networks. Today, CNNs have become a research hotspot in many scientific fields, especially in pattern classification, as this network avoids complex preprocessing of images and can directly input raw images, thus gaining wider application.
K. Fukushima proposed the first implementation network of convolutional neural networks in 1980, called the new recognition machine. Subsequently, more researchers improved this network. Among them, a representative research achievement is the “improved cognitive machine” proposed by Alexander and Taylor, which combines the advantages of various improvement methods and avoids time-consuming error backpropagation.
Generally, the basic structure of CNN includes two layers: the first is the feature extraction layer, where each neuron’s input is connected to the local receptive field of the previous layer to extract the features of that local area. Once the local features are extracted, their positional relationships with other features are also determined. The second is the feature mapping layer, where each computational layer of the network consists of multiple feature maps, each of which is a plane with equal weights for all neurons. The feature mapping structure uses activation functions with small influence function kernels such as sigmoid and ReLU, enabling the feature mapping to have shift invariance. Additionally, since the neurons on the same mapping plane share weights, the number of free parameters in the network is reduced. Each convolutional layer in a convolutional neural network is immediately followed by a computational layer for local averaging and secondary extraction, and this unique two-stage feature extraction structure reduces feature resolution.
CNNs are mainly used to recognize two-dimensional graphics that are invariant to shifts, scales, and other forms of distortion. Since the feature detection layer of CNN learns through training data, explicit feature extraction is avoided, allowing implicit learning from training data. Furthermore, because the neurons on the same feature mapping surface share weights, the network can learn in parallel, which is a significant advantage of convolutional networks over networks where neurons are interconnected. With its unique structure of local weight sharing, convolutional neural networks have distinct advantages in speech recognition and image processing, as their layout is closer to actual biological neural networks, and weight sharing reduces network complexity. This characteristic allows multi-dimensional input vectors, such as images, to be directly input into the network, avoiding the complexity of data reconstruction during feature extraction and classification.
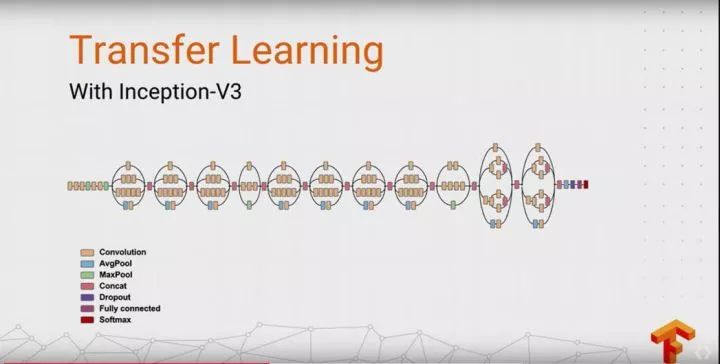
Figure 3.1 Inception-v3 Model
This article selects the Inception-v3 model, which has high accuracy, as the model for voice recognition. One of the most important improvements in v3 is decomposition, which breaks down the 7×7 convolution network into two one-dimensional convolutions (1×7, 7×1), and similarly for 3×3 (1×3, 3×1). The benefits of this are that it accelerates computation, allows for deeper networks, and increases the network’s non-linearity. It is also noteworthy that the network input has changed from 224×224 to 299×299, with more finely designed modules of 35×35/17×17/8×8.
Using the tensorflow session module can achieve training and prediction functions at the code level; for specific usage methods, please refer to the official TensorFlow website.
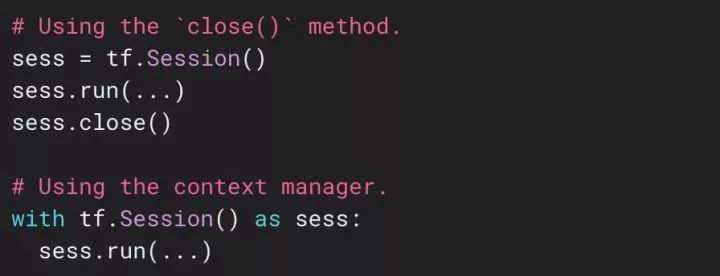
Figure 3.2 TensorFlow Session Usage Diagram
3.2 Model Samples
In supervised machine learning, samples are generally divided into three independent parts: training set, validation set, and test set. The training set is used to estimate the model, the validation set is used to determine the network structure or control parameters for model complexity, and the test set is used to verify the performance of the optimally selected model.
The specific definitions are as follows:
Training set: A dataset of learning samples used to establish a classifier by matching certain parameters. It is primarily used for training the model.
Validation set: Used to adjust the parameters of the classifier based on the learned model, such as selecting the number of hidden units in a neural network. The validation set is also used to determine the network structure or control parameters for model complexity to prevent overfitting.
Test set: Mainly used to test the resolution ability (recognition rate, etc.) of the trained model.
Based on the Mel-cepstral algorithm in Chapter 2, sound recognition sample files can be obtained, using human voice spectrograms as positive samples and animal sounds and background noise as negative samples for training the Inception-v3 model.
This article uses TensorFlow as the training framework, selecting 5000 samples each of human and non-human voices as the test set, and 1000 samples as the validation set.
3.3 Model Training
Once the sample preparation is complete, the Inception-v3 model can be trained. When the training model converges, a usable pb model can be generated on the device. During model selection, compile for armeabi-v7a or higher versions to enable NEON optimization by default, achieving instruction set acceleration. For example, more than half of the calculations in the CNN network are in convolution operations, and using instruction set optimization can accelerate by at least four times.
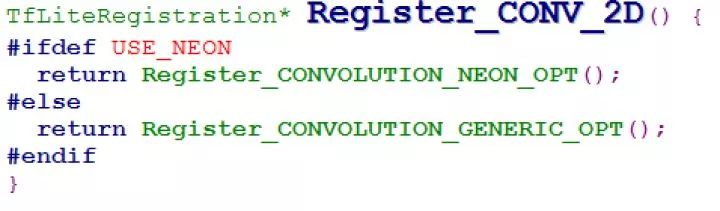 Figure 3.3 Convolution Processing Function
Figure 3.3 Convolution Processing Function
Then, use the toco tool provided by TensorFlow to generate a lite model that can be directly called by the tensorflowLite framework on the client side.
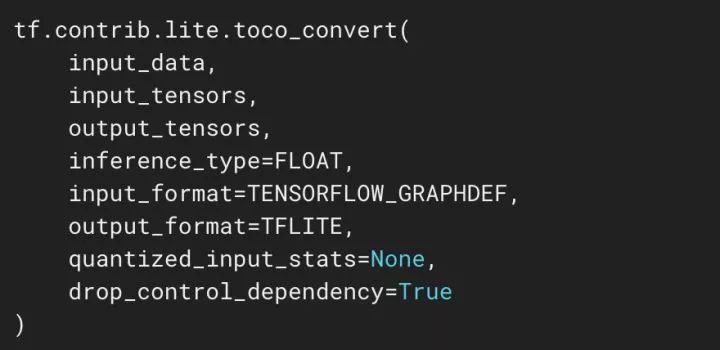
Figure 3.4 Toco Tool Call Interface
3.4 Model Prediction
Use the Mel-cepstral algorithm to extract features from the sound file and generate prediction images. Then, use the trained lite model for prediction; the prediction result is illustrated below:

Figure 3.5 Model Prediction Result
References:
[1] https://www.tensorflow.org/mobile/tflite
[2] Research on Speaker Identification Based on MFCC and IMFCC[D]. Liu Liyan. Harbin Engineering University. 2008
[3] A Method of Text-dependent Speaker Identification Based on MFCC and LPCC[J]. Yu Ming, Yuan Yuqian, Dong Hao, Wang Zhe. Computer Applications. 2006(04)
[4] Text-dependent Speaker Identification in Noisy Environment[C]. Kumar Pawan, Jakhanwal Nitika, Chandra Mahesh. International Conference on Devices and Communications. 2011
[5] https://github.com/weedwind/MFCC
[6] https://baike.baidu.com/item/ARM指令集/907786?fr=aladdin
[7] https://www.tensorflow.org/api_docs/python/tf/Session

You may also like
Click the image below to read

To “buy, buy, buy” globally,
Alibaba engineers developed a set of overseas HR systems.

Core technology of AI designer “Luban” disclosed:
How to design 8000 posters in 1 second?

How to improve anti-money laundering detection by 3 times using technology?
Analysis of Alipay’s fifth-generation risk control engine AlphaRisk model.

Follow “Ali Technology”
Grasp the pulse of cutting-edge technology