Important Insights Delivered Instantly
Important Insights Delivered Instantly
Official Account: You and Your House Author: Yu Yu Lu Ming Editor: Peter
Hello everyone, I am Peter~
There are many doubts about the number of hidden layers and neurons in neural networks. I just saw an article that answers these questions well, and I want to share it with you~
https://zhuanlan.zhihu.com/p/100419971
1. Introduction
The BP neural network is mainly composed of input layer, hidden layer, and output layer, where the number of nodes in the input and output layers is fixed.
Whether for regression or classification tasks, choosing the appropriate number of layers and hidden layer nodes greatly affects the performance of the neural network.
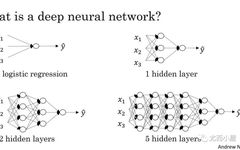
The number of nodes in the input and output layers is easy to determine:
-
The number of neurons in the input layer: equal to the number of input variables in the data to be processed -
The number of neurons in the output layer: equal to the number of outputs associated with each input
The difficulty lies in determining the appropriate number of hidden layers and their neurons.
2. Number of Hidden Layers
Determining the number of hidden layers is a critical question. First, note the following:
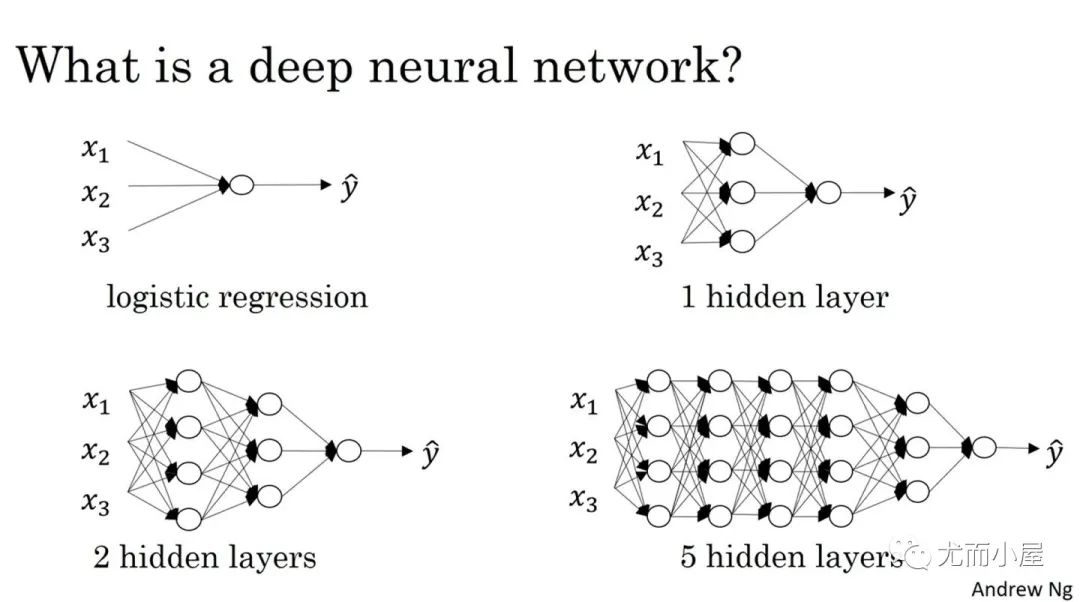
In neural networks, hidden layers are required only when the data is non-linearly separable!
Since a single sufficiently large hidden layer is adequate for approximation of most functions, why would anyone ever use more? One reason hangs on the words “sufficiently large”. Although a single hidden layer is optimal for some functions, there are others for which a single-hidden-layer-solution is very inefficient compared to solutions with more layers.——Neural Smithing: Supervised Learning in Feedforward Artificial Neural Networks, 1999
Therefore, for generally simple datasets, one or two hidden layers are usually sufficient. However, for complex datasets involving time series or computer vision, additional layers may be needed. A single-layer neural network can only represent linearly separable functions, which are very simple problems, such as two classes in a classification problem that can be neatly separated by a line.
Specifically, the universal approximation theorem states that a feedforward network with a linear output layer and at least one hidden layer with any “squashing” activation function (such as the logistic sigmoid activation function) can approximate any Borel measurable function from one finite-dimensional space to another with any desired non-zero amount of error, provided that the network is given enough hidden units.——Deep learning, 2016
In summary, multiple hidden layers can be used to fit non-linear functions.
The number of hidden layers and the effectiveness/use of the neural network can be summarized in the following table:

To summarize briefly——
-
No Hidden Layers: Can only represent linearly separable functions or decisions -
1 Hidden Layer: Can fit any function “containing continuous mappings from one finite space to another” -
2 Hidden Layers: With appropriate activation functions, can represent any decision boundary with arbitrary precision and can fit any smooth mapping with any precision -
More than 2 Hidden Layers: Extra hidden layers can learn complex representations (a kind of automatic feature engineering)
Empirically, greater depth does seem to result in better generalization for a wide variety of tasks. This suggests that using deep architectures does indeed express a useful prior over the space of functions the model learns.——Deep learning, 2016
The deeper the layers, the theoretically greater the ability to fit functions, and the performance should improve. However, in practice, deeper layers may lead to overfitting and increase training difficulty, making it hard for the model to converge.
Therefore, my experience is that when using BP neural networks, it is best to refer to existing well-performing models. If there are none, start from one or two layers based on the above table and try not to use too many layers.
In special fields like CV and NLP, one can use special models like CNN, RNN, attention, etc. One should not mindlessly stack multiple layers of neural networks without considering the practical aspects. Trying to transfer and fine-tune existing pre-trained models can yield significant results.
Determining the number of neurons in the hidden layers is just a small part of the problem. It is also necessary to determine how many neurons are in each of these hidden layers. The following will explain this process.
3. Number of Neurons in Hidden Layers
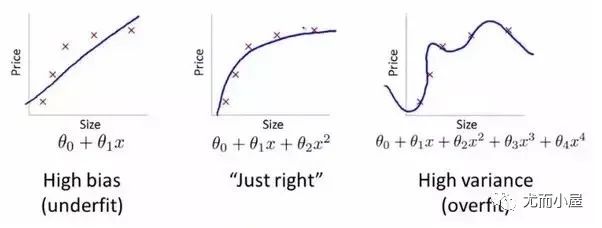
Using too few neurons in the hidden layers will lead to **underfitting**.
Conversely, using too many neurons can also lead to problems. First, having too many neurons in the hidden layers may lead to **overfitting**.
When the neural network has too many nodes (too much information processing capability), the limited amount of information contained in the training set is insufficient to train all the neurons in the hidden layers, leading to overfitting.
Even if the amount of information in the training data is sufficient, having too many neurons in the hidden layers will increase training time, making it difficult to achieve the desired results. Clearly, choosing an appropriate number of hidden layer neurons is crucial.
Generally, using the same number of neurons across all hidden layers is sufficient. For some datasets, having a larger first layer followed by smaller layers will lead to better performance because the first layer can learn many low-level features that can be fed into subsequent layers to extract higher-level features.
It should be noted that adding layers will yield greater performance improvement than adding more neurons in a single hidden layer. Therefore, do not add too many neurons in one hidden layer.
There are many empirical rules for determining the number of neurons.
Experts on Stack Overflow have provided empirical formulas for reference:

Another method for reference is that the number of neurons is typically determined by the following principles:
-
The number of hidden neurons should be between the size of the input layer and the size of the output layer. -
The number of hidden neurons should be 2/3 of the size of the input layer plus 2/3 of the size of the output layer. -
The number of hidden neurons should be less than twice the size of the input layer.
In summary, the optimal number of hidden layer neurons needs to be deterred through continuous experimentation. It is recommended to start with a small value, such as 1 to 5 layers and 1 to 100 neurons. If underfitting occurs, gradually add more layers and neurons; if overfitting occurs, reduce the number of layers and neurons.
Additionally, in practical processes, methods such as Batch Normalization, Dropout, Regularization can be considered to reduce overfitting.
4. References
-
LeCun, Yann, Yoshua Bengio, and Geoffrey Hinton. “Deep learning.” nature521.7553 (2015): 436-444. -
Heaton Research: The Number of Hidden Layers -
Ahmed Gad, Beginners Ask “How Many Hidden Layers/Neurons to Use in Artificial Neural Networks?” -
Jason Brownlee, How to Configure the Number of Layers and Nodes in a Neural Network -
Lavanya Shukla, Designing Your Neural Networks
Download 1: OpenCV-Contrib Extension Module Chinese Tutorial
Reply "OpenCV Extension Module Chinese Tutorial" in the "Beginner's Visual Learning" official account backend to download the first OpenCV extension module tutorial in Chinese, covering installation of extension modules, SFM algorithms, stereo vision, target tracking, biological vision, super-resolution processing, and more than twenty chapters of content.
Download 2: Python Visual Practical Projects 52 Lectures
Reply "Python Visual Practical Projects" in the "Beginner's Visual Learning" official account backend to download 31 visual practical projects, including image segmentation, mask detection, lane line detection, vehicle counting, eyeliner addition, license plate recognition, character recognition, emotion detection, text content extraction, face recognition, etc., to help you quickly learn computer vision.
Download 3: OpenCV Practical Projects 20 Lectures
Reply "OpenCV Practical Projects 20 Lectures" in the "Beginner's Visual Learning" official account backend to download 20 practical projects based on OpenCV, achieving advanced learning of OpenCV.
Discussion Group
You are welcome to join the official account reader group to communicate with peers. Currently, there are WeChat groups for SLAM, 3D vision, sensors, autonomous driving, computational photography, detection, segmentation, recognition, medical imaging, GAN, algorithm competitions, etc. (will be gradually subdivided in the future). Please scan the WeChat ID below to join the group, with the note: "Nickname + School/Company + Research Direction", for example: "Zhang San + Shanghai Jiao Tong University + Visual SLAM". Please follow the format, otherwise, it will not be approved. After successful addition, you will be invited to join relevant WeChat groups based on your research direction. Please do not send advertisements in the group, otherwise, you will be removed. Thank you for your understanding.~