
In this article, you will learn through hands-on experience why image-to-image search is a powerful tool that can help you find similar images in a vector database.
Table of Contents
-
Image-to-Image Search
-
Introduction to CLIP and Pinecone
-
Building the Image-to-Image Search Tool
-
Testing Time: The Lord of the Rings
-
What if I have a million images?
1. Image-to-Image Search
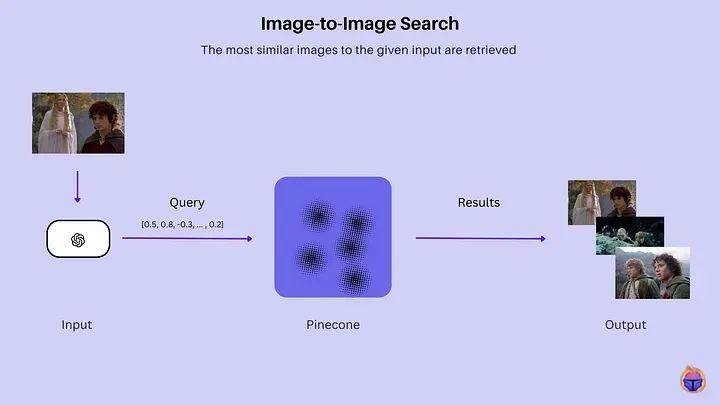
What does image-to-image search mean?
In traditional image search engines, you typically use a text query to find images, and the search engine returns results based on keywords associated with those images. In contrast, in image-to-image search, you use an image as the starting point for your query, and the system retrieves images that are visually similar to the query image.
Imagine you have a painting, like a beautiful sunset image. Now, you want to find other paintings that look exactly the same, but you can’t describe it in words. Instead, you show the computer your painting, and it browses all the paintings it knows to find those that are very similar, even if they have different names or descriptions. That is image-to-image search in a nutshell.
What can I do with this search tool?
The image-to-image search engine opens up a range of exciting possibilities:
-
Find specific data – Search for images containing specific objects you want to train your model to recognize.
-
Error analysis – When the model misclassifies an object, search for visually similar images where it also failed.
-
Model debugging – Show other images containing attributes or defects that lead to undesirable model behavior.
2. Introduction to CLIP and Pinecone
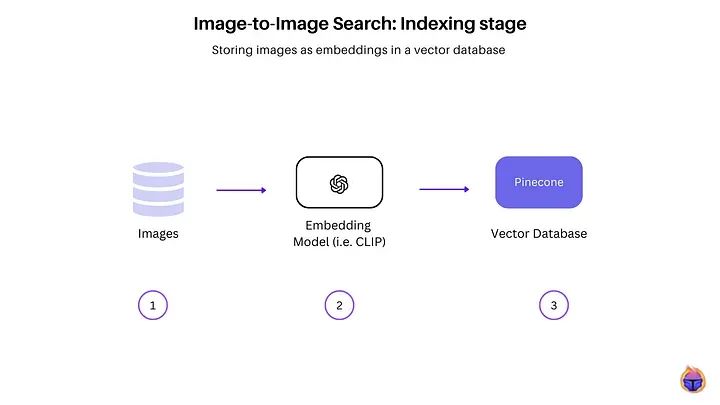 Indexing phase in image-to-image search
Indexing phase in image-to-image search
The above image shows the steps for indexing an image dataset in a vector database.
-
Step 1: Collect an image dataset (which can be raw/unlabeled images).
-
Step 2: Use CLIP [1], an embedding model, to extract a high-dimensional vector representation of the images, capturing their semantic and perceptual features.
-
Step 3: Encode these images into an embedding space, where the image embeddings are indexed in a vector database like Pinecone.
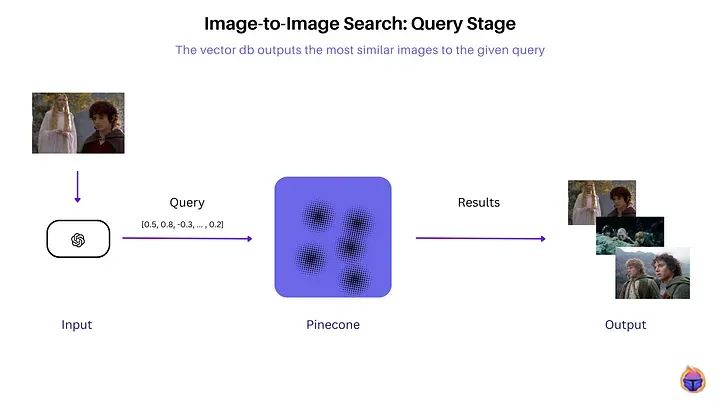
Query phase: Retrieve the most similar images for a given query
During the query, a sample image is passed through the same CLIP encoder to obtain its embedding. A vector similarity search is executed to efficiently find the top k nearest database image vectors. The images with the highest cosine similarity scores to the query embedding are returned as the most similar search results.
3. Building the Image-to-Image Search Engine
3.1 Dataset – The Lord of the Rings
We use Google search to query images related to the keyword “The Lord of the Rings movie scenes.” Based on this code, we create a function to retrieve 100 URLs based on the given query.
import requests, lxml, re, json, urllib.requestfrom bs4 import BeautifulSoup
headers = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.5060.114 Safari/537.36"}
params = { "q": "the lord of the rings film scenes", # search query "tbm": "isch", # image results "hl": "en", # language of the search "gl": "us", # country where search comes from "ijn": "0" # page number}
html = requests.get("https://www.google.com/search", params=params, headers=headers, timeout=30)soup = BeautifulSoup(html.text, "lxml")
def get_images():
""" https://kodlogs.com/34776/json-decoder-jsondecodeerror-expecting-property-name-enclosed-in-double-quotes if you try to json.loads() without json.dumps() it will throw an error: "Expecting property name enclosed in double quotes" """
google_images = []
all_script_tags = soup.select("script")
# # https://regex101.com/r/48UZhY/4 matched_images_data = "".join(re.findall(r"AF_initDataCallback\(([^<]+)\);", str(all_script_tags)))
matched_images_data_fix = json.dumps(matched_images_data)
matched_images_data_json = json.loads(matched_images_data_fix)
# https://regex101.com/r/VPz7f2/1 matched_google_image_data = re.findall(r'"b-GRID_STATE0"(.*)sideChannel:\s?{}}', matched_images_data_json)
# https://regex101.com/r/NnRg27/1 matched_google_images_thumbnails = ", ".join( re.findall(r'\["(https\:\/\/encrypted-tbn0\.gstatic\.com\/images\?.*?)",\d+,\d+\]', str(matched_google_image_data))).split(", ")
thumbnails = [ bytes(bytes(thumbnail, "ascii").decode("unicode-escape"), "ascii").decode("unicode-escape") for thumbnail in matched_google_images_thumbnails ]
# removing previously matched thumbnails for easier full resolution image matches. removed_matched_google_images_thumbnails = re.sub( r'\["(https\:\/\/encrypted-tbn0\.gstatic\.com\/images\?.*?)",\d+,\d+\]', "", str(matched_google_image_data))
# https://regex101.com/r/fXjfb1/4 # https://stackoverflow.com/a/19821774/15164646 matched_google_full_resolution_images = re.findall(r"(?:'|,),\["(https:|http.*?)",\d+,\d+\]", removed_matched_google_images_thumbnails)
full_res_images = [ bytes(bytes(img, "ascii").decode("unicode-escape"), "ascii").decode("unicode-escape") for img in matched_google_full_resolution_images ]
return full_res_images3.2 Using CLIP to Get Embedding Vectors
Extract all embeddings for our image set.
def get_all_image_embeddings_from_urls(dataset, processor, model, device, num_images=100): embeddings = []
# Limit the number of images to process dataset = dataset[:num_images] working_urls = []
#for image_url in dataset['image_url']: for image_url in dataset: if check_valid_URL(image_url): try: # Download the image response = requests.get(image_url) image = Image.open(BytesIO(response.content)).convert("RGB") # Get the embedding for the image embedding = get_single_image_embedding(image, processor, model, device) #embedding = get_single_image_embedding(image) embeddings.append(embedding) working_urls.append(image_url) except Exception as e: print(f"Error processing image from {image_url}: {e}") else: print(f"Invalid or inaccessible image URL: {image_url}")
return embeddings, working_urlsLOR_embeddings, valid_urls = get_all_image_embeddings_from_urls(list_image_urls, processor, model, device, num_images=100)Invalid or inaccessible image URL: https://blog.frame.io/wp-content/uploads/2021/12/lotr-forced-perspective-cart-bilbo-gandalf.jpgInvalid or inaccessible image URL: https://www.cineworld.co.uk/static/dam/jcr:9389da12-c1ea-4ef6-9861-d55723e4270e/Screenshot%202020-08-07%20at%2008.48.49.pngInvalid or inaccessible image URL: https://upload.wikimedia.org/wikipedia/en/3/30/Ringwraithpic.JPGOut of 100 URLs, 97 contained valid images.
3.3 Storing Our Embeddings in Pinecone
To store our embeddings in Pinecone [2], we first need to create a Pinecone account. After that, create an index named “image-to-image”.
pinecone.init( api_key = "YOUR-API-KEY", environment="gcp-starter" # find next to API key in console)
my_index_name = "image-to-image"vector_dim = LOR_embeddings[0].shape[1]
if my_index_name not in pinecone.list_indexes(): print("Index not present")
# Connect to the indexmy_index = pinecone.Index(index_name = my_index_name)Create a function to store data in the Pinecone index.
def create_data_to_upsert_from_urls(dataset, embeddings, num_images): metadata = [] image_IDs = [] for index in range(len(dataset)): metadata.append({ 'ID': index, 'image': dataset[index] }) image_IDs.append(str(index)) image_embeddings = [arr.tolist() for arr in embeddings] data_to_upsert = list(zip(image_IDs, image_embeddings, metadata)) return data_to_upsertRun the above function to get:
LOR_data_to_upsert = create_data_to_upsert_from_urls(valid_urls, LOR_embeddings, len(valid_urls))
my_index.upsert(vectors = LOR_data_to_upsert)# {'upserted_count': 97}
my_index.describe_index_stats()# {'dimension': 512,# 'index_fullness': 0.00097,# 'namespaces': {'': {'vector_count': 97}},# 'total_vector_count': 97}3.4 Testing Our Image-to-Image Search Tool
# For a random imagen = random.randint(0,len(valid_urls)-1)print(f"Sample image with index {n} in {valid_urls[n]}")Sample image with index 47 in https://www.intofilm.org/intofilm-production/scaledcropped/870x489https%3A/s3-eu-west-1.amazonaws.com/images.cdn.filmclub.org/film__3930-the-lord-of-the-rings-the-fellowship-of-the-ring--hi_res-a207bd11.jpg/film__3930-the-lord-of-the-rings-the-fellowship-of-the-ring--hi_res-a207bd11.jpg
Sample image for querying (can be found in the above URL)
# 1. Get the image from urlLOR_image_query = get_image(valid_urls[n])# 2. Obtain embeddings (via CLIP) for the given imageLOR_query_embedding = get_single_image_embedding(LOR_image_query, processor, model, device).tolist()# 3. Search on Vector DB index for similar images to "LOR_query_embedding"LOR_results = my_index.query(LOR_query_embedding, top_k=3, include_metadata=True)# 4. See the resultsplot_top_matches_seaborn(LOR_results)
Results showing similarity scores for each match
As shown in the figure, our image-to-image search tool found images similar to the given sample image, with ID 47 having the highest similarity score as expected.
5. What if I have a million images?
As you may have realized, building an image-to-image search tool by querying some images from Google search is fun. But what if you actually have a dataset containing over a million images?
In that case, you might prefer to build a system rather than just a tool. Building a scalable system is not an easy task. Moreover, it involves some costs (such as storage costs, maintenance, and writing the actual code). For such cases, at Tenyks, we have built an optimal image-to-image search engine that can execute multimodal queries in seconds, even if you have a million or more images!
