


In the face of increasing data volumes, complex business logic, and the pursuit of higher performance and reliability, database systems face numerous challenges. One of the current issues to be addressed is the effective handling of large-scale data while ensuring data security and privacy. With the continuous evolution of artificial intelligence technology, the application of LLM has become a hot topic in the database field. LLM technology can not only optimize the performance and reliability of database systems but also provide more intelligent solutions for database queries and process optimization.
At the upcoming AICon Global Artificial Intelligence Development and Application Conference, we are fortunate to invite Li Li, the head of PingCAP AI Lab, to share his insights. He will discuss the aforementioned challenges and share the application prospects and solutions of LLM technology in the database field. Before the conference, InfoQ had the privilege of interviewing Li Li, and the following is the interview dialogue – for more exciting shares, please follow the conference.
Li Li: One of the most pressing challenges currently facing the database field is ++ how to handle and analyze the ever-growing volume of data while maintaining efficient performance and reliability ++. This challenge is primarily reflected in the following aspects:
First, the continuous growth of data scale is a significant challenge. With the rapid development of fields such as the Internet of Things, social media, and enterprise applications, the volume of data is growing exponentially. This not only requires databases to effectively store and manage massive amounts of data but also necessitates optimizing storage structures, indexing mechanisms, and query processing to maintain efficient performance.
Second, the demand for real-time data processing is increasing. Modern business scenarios, such as real-time analytics and online transaction processing, require database systems to ensure extremely low latency while processing large amounts of data. This places higher demands on the design and optimization of databases.
Third, data security and privacy protection is also a major challenge. With the frequent occurrence of data breaches, how to protect data security through encryption, access control, and other measures to prevent unauthorized access or leaks has become an important aspect of database system design.
Additionally, we also face challenges in handling diverse data types and complex data relationships. Modern databases must not only handle structured data but also effectively manage semi-structured and unstructured data. At the same time, the relationships between data have become more complex, which poses new requirements for database models and query languages.
Finally, high availability and disaster recovery capabilities are also increasingly important concerns for enterprises. Any data loss or service interruption can lead to significant business losses, so ensuring the high availability and rapid recovery capabilities of databases is crucial.
These challenges directly impact the performance and reliability of database systems. For instance, if there is a lack of effective indexing and query optimization techniques when handling large-scale data, it will lead to slow query speeds, severely affecting user experience. Similarly, if security measures are inadequate, data may face risks of leakage or damage, thereby affecting the overall reliability of the system.
Li Li: LLM technology has a wide range of applications in the database field, significantly contributing to enhancing user experience and optimizing internal operations.
Firstly, in terms of user perception, LLM technology can greatly simplify user interaction with databases. For example, document-based ChatBots, such as TiDB Bot, can support user queries on platforms like Slack or Cloud. This ChatBot can understand the user’s query intentions and provide suggestions regarding database configuration, log management, slow query optimization, and more. This not only improves user operational convenience but also helps users manage databases more effectively.
Moreover, LLM technology can also assist users in generating SQL queries directly through natural language (NL2SQL). This means that even users unfamiliar with SQL syntax can obtain data by describing their query needs. Furthermore, we can extend this technology to convert raw data into business insights (NL2Insight), which not only involves generating SQL but also providing deeper data analysis and business insights.
In diagnostics and fault recovery, LLM technology also shows great potential. By integrating into ChatBot-based systems, LLM can utilize logs, slow queries, performance metrics, and other information to provide deeper domain judgments and business problem analysis. This helps reduce the Mean Time to Repair (MTTR), allowing even non-professional users to quickly diagnose and resolve issues.
In terms of internal use, which users do not directly perceive, LLM technology also plays an important role. For instance, in automated testing, LLM can be used to generate test cases for database systems, improving test coverage and efficiency. In code reviews, LLM can help analyze code quality and style consistency, enhancing development efficiency. Additionally, LLM can also automate the generation of performance analysis reports, fault reports, etc., helping technical teams quickly obtain key information and manage internal knowledge bases, improving information sharing and retrieval efficiency.
Li Li: In LLM applications, we can distinguish three technical levels: Wrapper, Flow, and Agent. Each level represents different complexities and application scenarios of interaction with LLM.
-
LLM Wrapper:
This is the most basic application level, involving a single interaction with LLM. At this level, the user’s request is sent directly to the model, which returns a response. The capability of this method is limited by the model’s reasoning ability itself. It is suitable for the early stages of business when enterprises are looking for product-market fit (PMF) and can be quickly developed and iterated.
-
Flow (DAG):
At the Flow level, business logic is constructed through a Directed Acyclic Graph (DAG), enabling multiple interactions with LLM. Each interaction focuses on solving a specific problem, such as intent determination, content rewriting, providing answers or critiques, etc. This approach effectively overcomes the limitations of single interactions, supporting the construction of more complex applications. It is suitable for scenarios where there is a clear understanding of how to use LLM to solve business problems and requires handling more complex logic and improving accuracy.
-
Agent (Loop):
The Agent level is built on Loop + Feedback. Here, LLM can autonomously decide and execute the necessary steps based on human input, evaluate whether there are anomalies after completion, and adjust accordingly. Through this method, LLM can significantly improve the accuracy of results and solve more complex problems. The logic of building Agents is fundamentally different from traditional applications, with the core idea similar to building a team or company where each Agent is a capable workforce. Through the mutual complementarity of numerous Agents, a relatively reasonable decision is ultimately made.
There is no absolute good or bad among these technical directions; the key is to choose the technology level that best fits the current business needs. As business develops and needs change, it may be necessary to migrate from one level to another to adapt to more complex scenarios and improve the overall performance of the system.
A table like this can clearly further illustrate the differences in application levels.
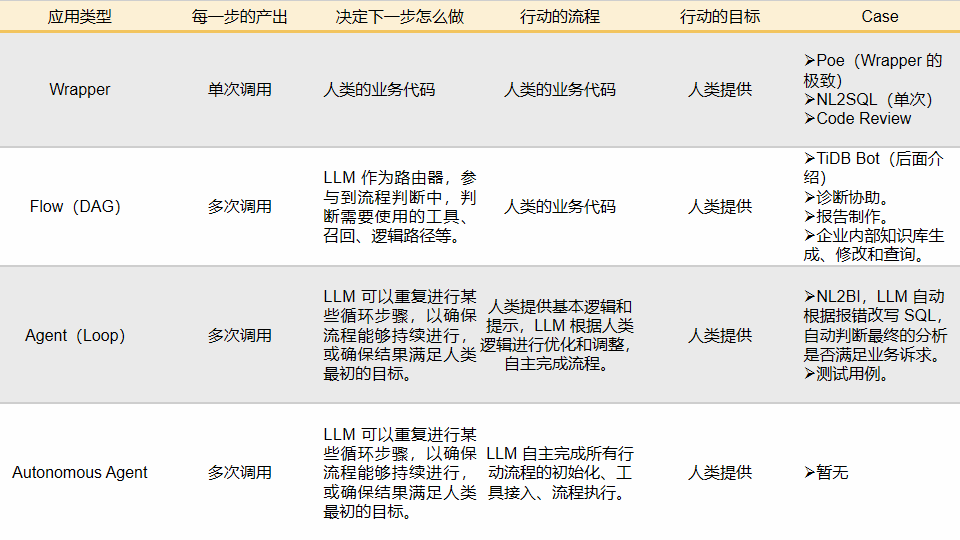
Li Li: Using LLM to solve practical problems typically involves several key steps, each with its unique challenges.
Typical business implementation steps include:
-
Business insight and demand judgment: This is the first step in project initiation, requiring a deep understanding of business needs and pain points.
-
Experimentation and feasibility analysis: At this step, we conduct preliminary experiments to test the applicability and effectiveness of LLM.
-
Application type iteration: Depending on the complexity of the scenario, we may start from the Wrapper and gradually iterate to Flow and Agent.
-
Feedback design and collection: Designing effective feedback mechanisms to collect user feedback is crucial for model optimization.
-
Continuous optimization design and implementation: Continuously optimizing models and business processes based on collected feedback.
In these steps, the main challenges we encounter include:
-
Business understanding: Deeply understanding business needs often requires close cooperation with business parties, which may involve personally participating in business processes.
-
Model capabilities: There may be a gap between the theoretical capabilities of the model and its actual application effects.
-
Maturity of tools: The tools available on the market may not be mature enough, and sometimes we need to contribute to open source or develop independently.
-
Stability of LLM: This includes the stability of responses and processes, which needs to be addressed through carefully designed prompts and process control mechanisms.
-
Response format and quality of LLM: Ensuring that the responses provided by LLM meet business needs and are of high quality requires continuous feedback and optimization.
Response strategies:
-
Deep collaboration: Collaborate closely with business parties to ensure a full understanding of business needs.
-
Continuous experimentation: Through ongoing experiments and feasibility analyses, continuously adjust and optimize the application of LLM.
-
Feedback mechanisms: Design effective feedback mechanisms, such as thumbs up/down and similarity evaluations for ChatBot, and correctness evaluations for SQL, to collect user feedback and optimize models.
-
Enhance tools and processes: Develop or improve tools, optimize business processes, and enhance the application effects and stability of LLM.
Li Li: Copilot is a very specific interaction method in AI applications that seeks a balance between flexibility and ease of use, aiming to reduce the cognitive burden on users while providing effective support.
The core features and applications of Copilot:
Copilot can be viewed as a user’s