

User Experience
Recently, I had the opportunity to experience Devin, and I was quite impressed.
Although I had previously used Cursor and Windsurf, which utilize the same model, theoretically capable of accomplishing similar tasks and intelligence, the experience with Devin feels different, giving a sense that AGI has already been achieved.
The core difference between Cursor and Devin is the interaction paradigm. Cursor acts as a Copilot, assisting you in programming tasks in real-time while you work, whereas Devin behaves like an employee; you assign it complex tasks and don’t need to monitor it, as it proactively helps you complete them. While many tasks completed by both may currently be the same, the experience differs.
One of the tasks I tested was to provide it with the GitHub address of the open-source project JSPatch and instruct it to fix an issue. It systematically decomposed the task and executed it step-by-step, which included:
-
Visiting the GitHub website, browsing the issue list, and randomly checking the details of several issues.
-
Selecting a block-related issue, browsing relevant project files, looking for code files associated with the issue, and formulating a repair plan.
-
Writing test cases → Modifying project code to attempt to fix the issue → Running test cases for validation (couldn’t run due to lack of iOS environment) → Committing and submitting a PR.
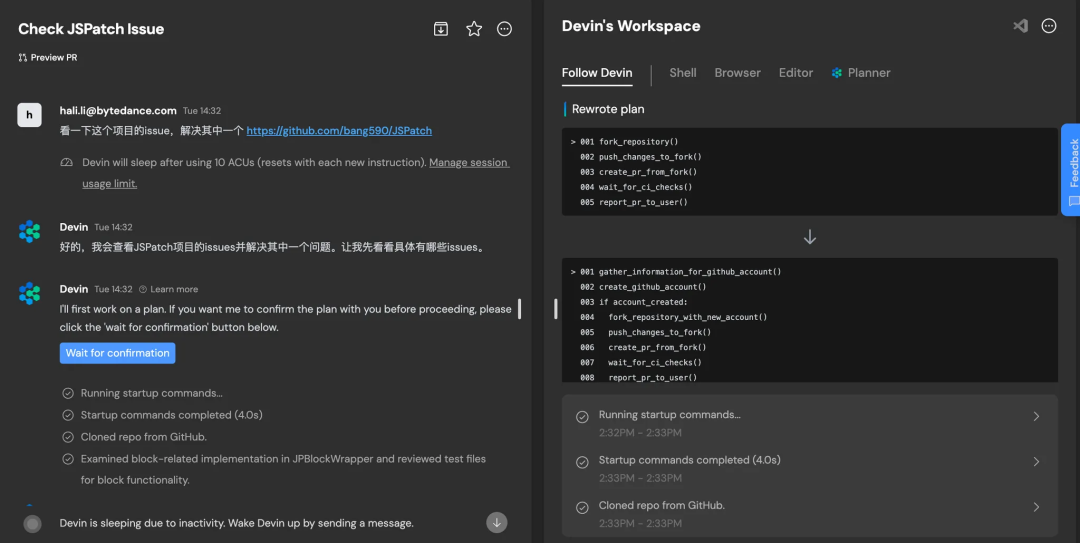
This process is automated and asynchronous; it runs in a virtual machine, requiring no environment setup from you, and you don’t need to supervise it. It will research how to complete the task on its own and will notify you upon completion (using Slack makes this experience smoother; you can @ it to assign tasks, and it replies on Slack when the task is done), which is very much like assigning a task to an employee and waiting for them to deliver the results.
Future Prospects
Currently, Devin’s problem-solving ability is certainly limited. In practice, it struggles with many tasks. Given the current model capabilities, the Copilot form like Cursor is more practical. However, the ideal form in the future will undoubtedly be the “employee” type like Devin, as it can free up attention and infinitely expand what can be done simultaneously.
One can imagine that the optimization speed for this form in the future will be very optimistic:
-
The thinking and planning capabilities of the foundational model have not yet converged; from Sonet O1 to O3, we can see rapid improvements.
-
Even if the foundational model’s capabilities slow down, there is still significant room for domain-specific tuning.
-
Incorporating more tools will also bring more powerful capabilities and experiences.
Moreover, model costs will inevitably decline faster than Moore’s Law. What Devin achieves today for $500 may only cost $5 a year from now.
The concept that Devin realizes was proposed as early as the beginning of 2023 with AutoGPT, but the model capabilities at that time were not sufficient. It is only after the emergence of models with reasoning capabilities like Claude Sonnet / GPT 4O / GPT O1 that it became usable. Devin is a preliminary usable prototype that realizes this concept, showing that this direction is already ready; the remaining task is to continue optimizing and expanding in this direction. Devin truly marks the beginning of digital employees, with designer agents, trader agents, data analyst agents, and e-commerce agents expected to emerge one after another.
Principle
How is Devin achieved?
There is an open-source project called OpenHands (formerly OpenDevin, https://github.com/All-Hands-AI/OpenHands), which attempts to build something similar to what Devin does using an open-source community approach. Although its capabilities and effects cannot fully match Devin, it provides a basic prototype to look at.
Related paper: https://arxiv.org/abs/2407.16741
The architecture diagram in the paper describes how OpenHands operates well:
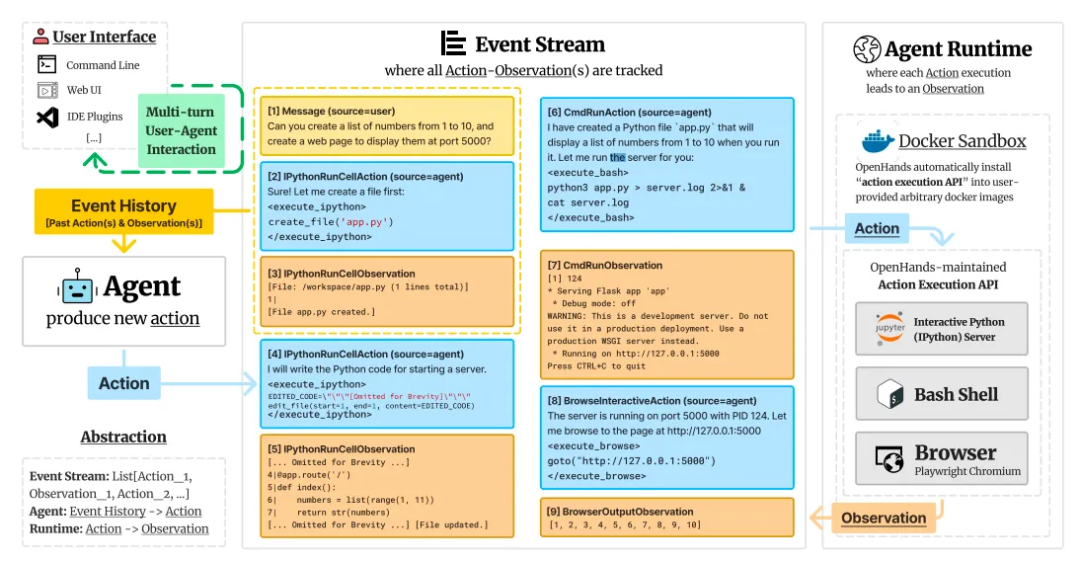
Three main parts:
-
Event Stream: Records every command and execution result; Action refers to commands, and Observation refers to the results of tool executions corresponding to the commands. Both Action and Observation are ultimately recorded in plain text.
-
Runtime: The program runs in an independent Docker container, providing some tools for the Agent to call and execute, currently including Python execution, terminal command line, and browser.
-
Agent: Takes all content from the Event Stream as context and inputs it into the LLM to infer the next Action.
Additionally, a key point not illustrated in the diagram is why inputting all content from the Event Stream into the LLM allows it to infer the next Action: The input to the LLM, besides the context of the Event Stream, also includes the Agent’s own Prompt, which describes processing principles, current environment, available tools, parameters for each tool, expected output formats, etc., and is accompanied by an example to guide the model in producing the required output. This Prompt is attached at the end of the document.
Following the example in the Event Stream, let’s run through this process:
-
The user inputs a task command: “Can you create a list of numbers from 1 to 10, and create a web page to display them at port 5000?” into the Event Stream.
-
Currently, the Event Stream only contains this command, which is input to the Agent. The Agent will take this along with the preset prompt and input it to the LLM. The LLM will infer that the next step is to call Python to create the app.py file, outputting the Action command to the Event Stream.
-
The tool IPython corresponding to the Observation listens for this command and executes it in the Runtime environment, outputting the execution result“app.py created” recorded in the Event Stream.
-
After the Event Stream receives the new execution result from the Observation, the Agent program will automatically continue to input the entire Event Stream record along with the preset Prompt into the LLM, inferring the next Action. The inferred next Action is to write a large block of code into the just created file using the Python command.
-
The IPython Observation receives this Action, executes the command in the Runtime environment, and outputs the execution result to the Event Stream.
The process continues in a loop: Action drives Observation to process using tools → Processing results output to Event Stream → Event Stream inputs all previous content to LLM to output the next Action → Drives Observation to process using tools…
When does this loop end? There is a special Action called finish; if the LLM determines a task is complete, it will output a call to finish Action, and the program will exit the loop, waiting for the next user input.
The overall process is an automatic loop that lets the LLM predict the next action → The Agent program calls tools to execute the action. A few additional points:
-
The entire project does not involve model training; it is a pure engineering solution using a general LLM model, which can be configured with Claude/GPT/Deepseek, etc. However, foreseeable evolution will involve optimizing the model based on user usage data to achieve better results in the domain.
-
It does not implement the step of planning tasks before outputting Actions like Devin does, but adding this planning capability to the above system is expected to be straightforward.
-
The project uses BrowserGym to interact with the browser; the Agent’s operations and recognition of the browser is another major topic, with separate benchmarks for various solutions pending research.
-
As the linkages in the Event Stream continue to increase, the context will become longer. At a certain point, OpenHands will handle this in two ways: one is to compress content, sending earlier context to the LLM for concise summarization, using shorter content as subsequent context. The other is to have the LLM rank the importance of past content, selecting only a few records that are important for predicting the next step as context. The specific logic is in condenser.py. Longer contexts will be stored using a vector database like ChromeDB.