
Source: Intelligent Accounting Alliance
This article is approximately 2200 words long and is recommended for a reading time of 9 minutes. This article will guide you through five aspects of getting started with machine learning: What is machine learning? What is the workflow? What machine learning algorithms are available? Model evaluation learning, and Azure machine learning model building experiments.
1. What is Machine Learning
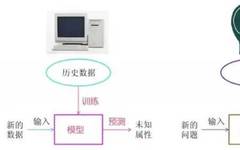
Machine learning is the process of automatically analyzing data to obtain a model, which is then used to predict unknown data.
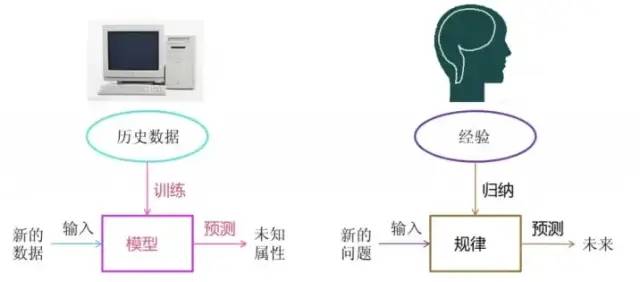
2. Machine Learning Workflow
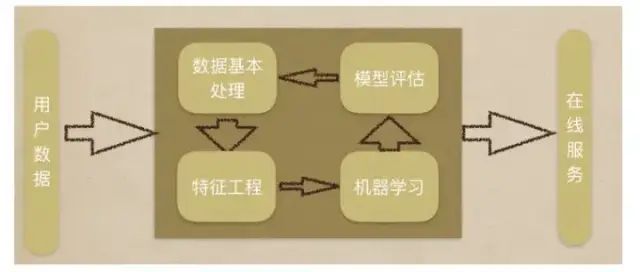
-
Data Acquisition -
Basic Data Processing -
Feature Engineering -
Machine Learning (Model Training) -
Model Evaluation
If the results meet the requirements, go live with the service. If not, repeat the above steps.
2.1 Introduction to the Acquired Dataset
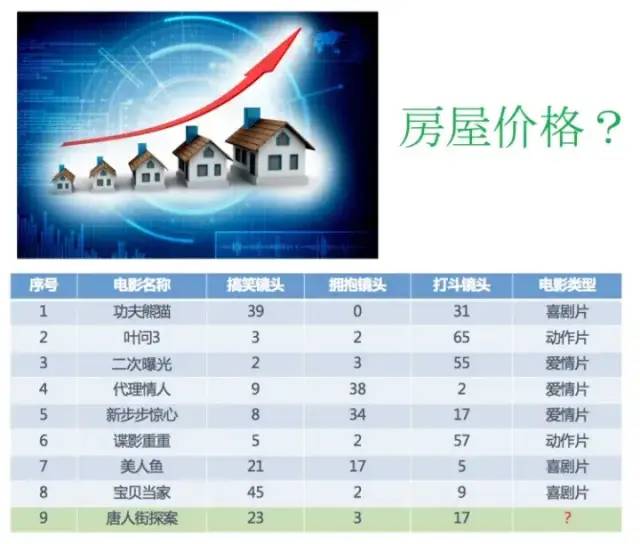
Data Overview
In a dataset generally:
-
A row of data is referred to as a sample; -
A column of data is referred to as a feature; -
Some data has target values (label values), while others do not (for example, the movie genre in the table above is the target value of this dataset).
Types of data composition:
-
Data Type 1: Feature values + target values (target values can be continuous or discrete); -
Data Type 2: Only feature values, no target values.
Data Splitting
Machine learning datasets are generally divided into two parts:
-
Training Data: Used for training and building the model; -
Testing Data: Used to evaluate the effectiveness of the model during validation.
Splitting ratio:
-
Training Set: 70% 80% 75% -
Testing Set: 30% 20% 25%
2.2 Basic Data Processing
That is, processing data for missing values, removing outliers, etc.
2.3 Feature Engineering
2.3.1 What is Feature Engineering
Feature engineering is the process of using specialized knowledge and techniques to process data so that features can perform better in machine learning algorithms.
Significance: It directly affects the effectiveness of machine learning.
2.3.2 Why Feature Engineering is Needed
Andrew Ng, a leading figure in the field of machine learning, said, “Coming up with features is difficult, time-consuming, requires expert knowledge. ‘Applied machine learning’ is basically feature engineering.”
Note: It is widely believed in the industry that data and features determine the upper limit of machine learning, while models and algorithms only approach this limit.
2.3.3 Contents of Feature Engineering
-
Feature Extraction -
Feature Preprocessing -
Feature Dimensionality Reduction
2.3.4 Specific Explanations of Concepts
-
Feature Extraction
Converting any data (such as text or images) into numerical features that can be used for machine learning.
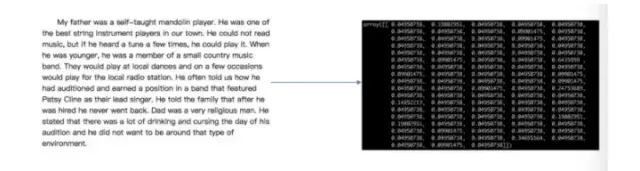
-
Feature Preprocessing
The process of transforming feature data into more suitable feature data for algorithm models through some transformation functions.
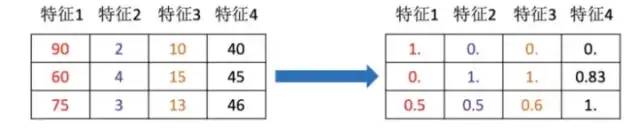
-
Feature Dimensionality Reduction
Refers to the process of reducing the number of random variables (features) under certain constraints to obtain a set of “uncorrelated” main variables.

2.4 Machine Learning
Select appropriate algorithms to train the model.
2.5 Model Evaluation
Evaluate the trained model.
3. Classification of Machine Learning Algorithms
Based on the composition of the dataset, machine learning algorithms can be classified into:
-
Supervised Learning -
Unsupervised Learning -
Semi-supervised Learning -
Reinforcement Learning
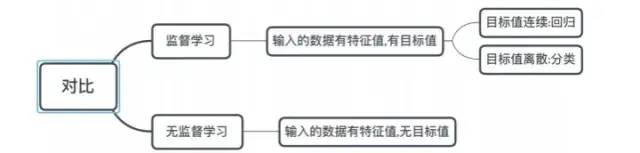
3.1 Supervised Learning
Definition: The input data consists of input feature values and target values. The output of the function can be a continuous value (referred to as regression) or a finite number of discrete values (referred to as classification).
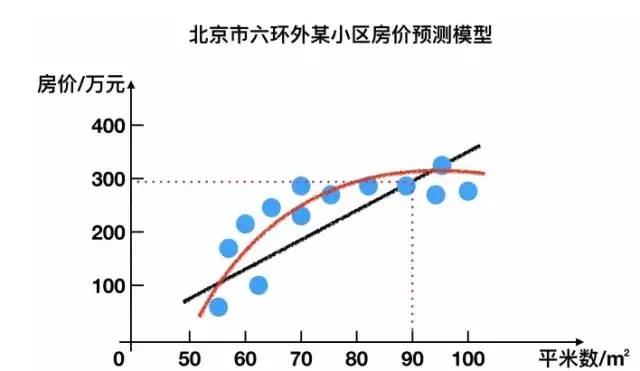
3.1.1 Regression Problems
For example: predicting house prices by fitting a continuous curve based on the sample set.
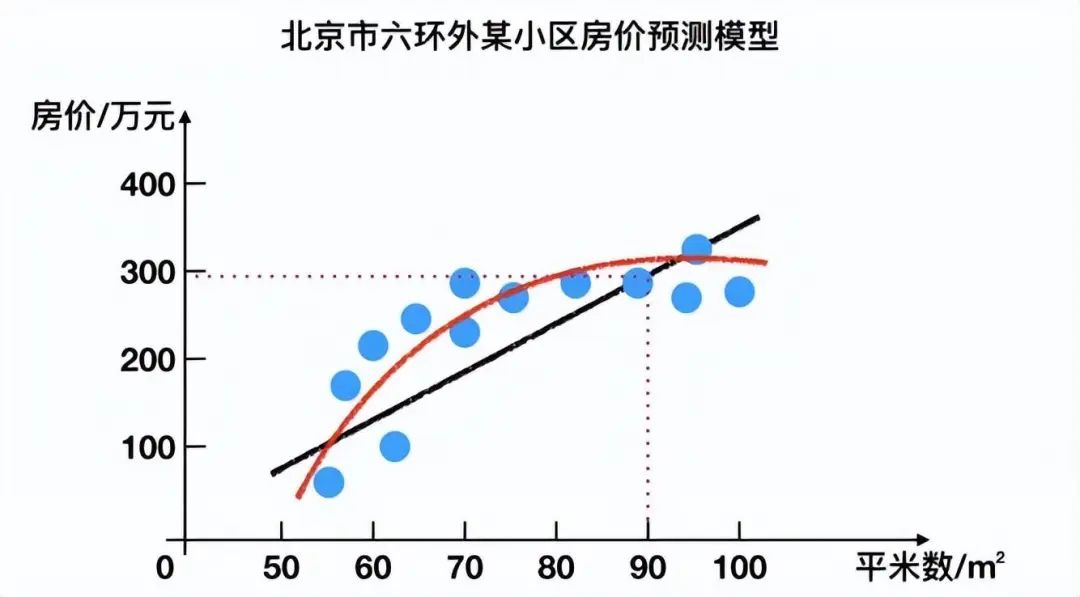
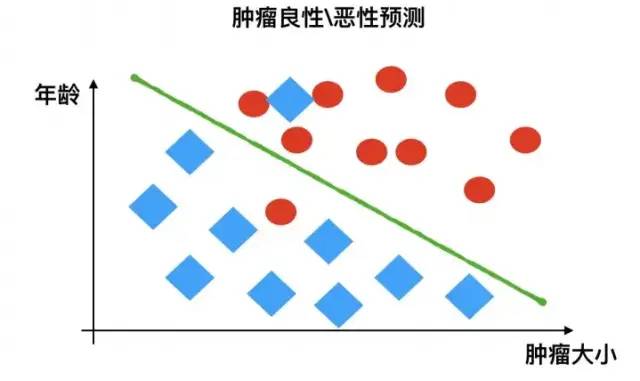
3.1.2 Classification Problems
For example: determining whether a tumor is benign or malignant based on its features, resulting in either “benign” or “malignant,” which are discrete outcomes.
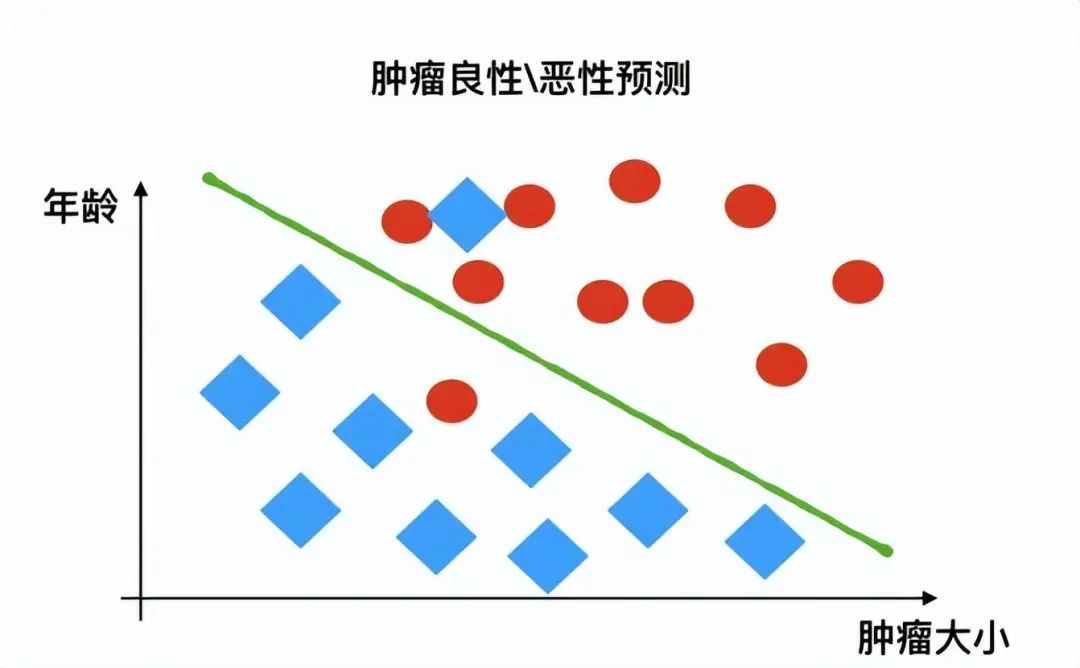
3.2 Unsupervised Learning
Definition: The input data consists of input feature values without target values.
-
The input data is not labeled and has no determined outcome. The categories of the sample data are unknown; -
It is necessary to categorize the sample set based on the similarity between samples.
Example:

Comparison of supervised and unsupervised algorithms:
3.3 Semi-supervised Learning
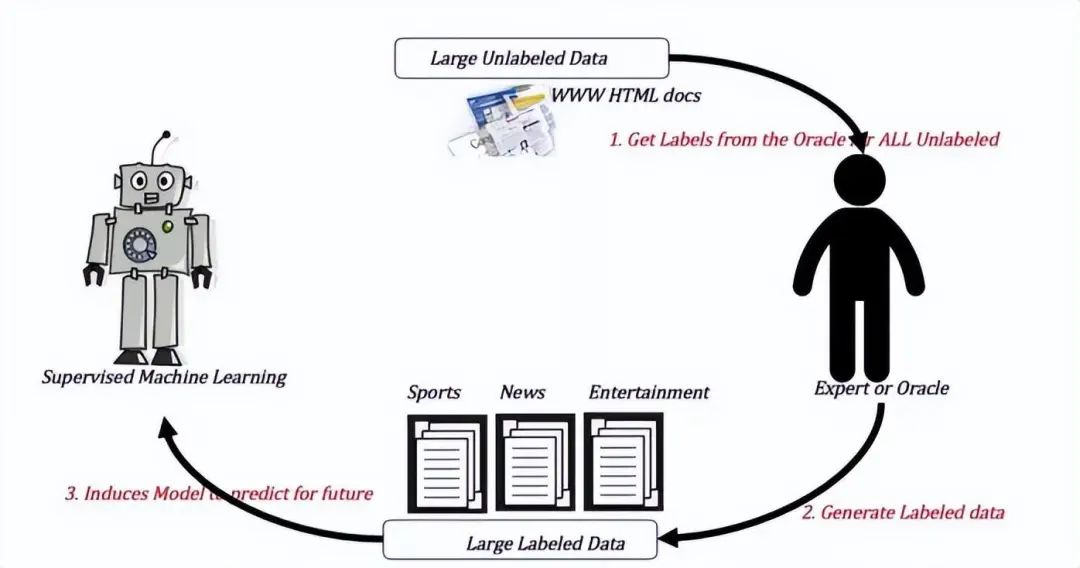
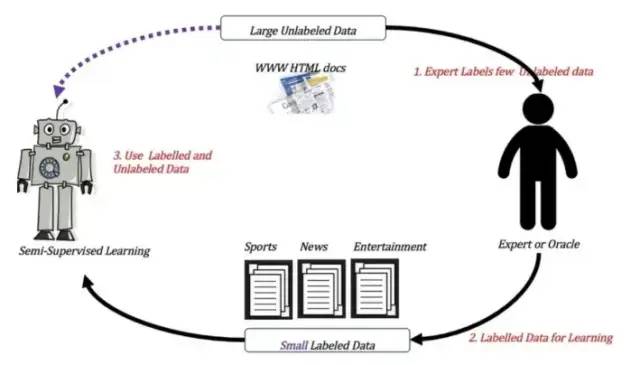
Definition: The training set contains both labeled and unlabeled sample data.
Example:
-
Supervised learning training method:
-
Semi-supervised learning training method
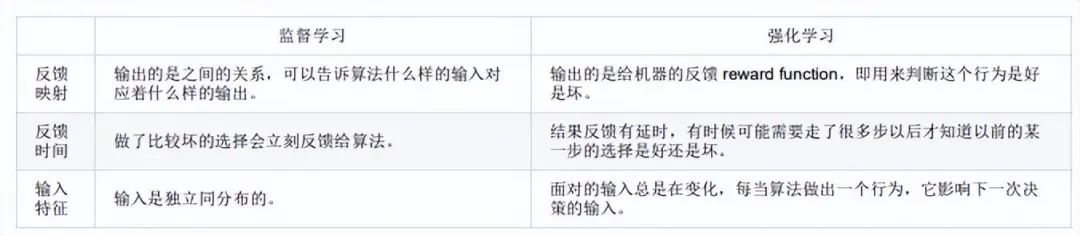
3.4 Reinforcement Learning
Definition: Essentially a decision-making problem, where automatic decisions can be made continuously.
Example: A child wants to walk, but first, he needs to stand up, maintain balance, and then take a step, whether it’s the left leg or the right leg; after taking one step, he needs to take the next step.
The child is the agent, trying to manipulate the environment (the surface he walks on) by taking actions (walking), and transitioning from one state to another (every step he takes). When he completes a subtask (taking a few steps), he receives a reward (getting chocolate), and when he cannot walk, he does not get chocolate.
It mainly includes five elements: agent, action, reward, environment, observation;
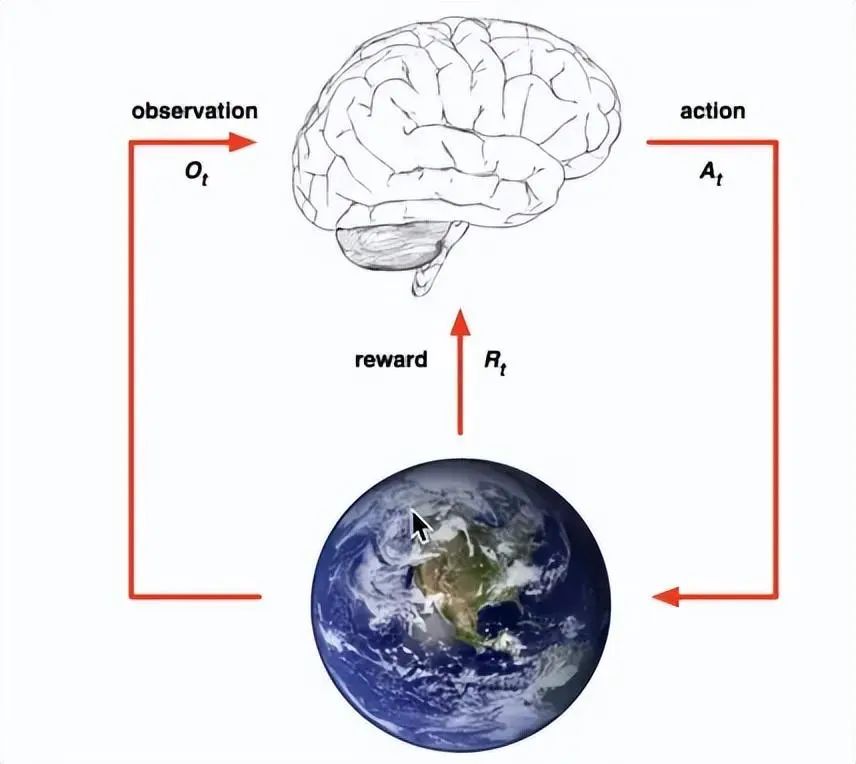
The goal of reinforcement learning is to obtain the maximum cumulative reward.
Comparison of Supervised Learning and Reinforcement Learning:
4. Model Evaluation
4.1 Classification Model Evaluation
Accuracy: The proportion of correctly predicted samples to the total number of samples.
Other evaluation metrics: Precision, Recall, F1-score, AUC metrics, etc.
4.2 Regression Model Evaluation
Root Mean Squared Error (RMSE)
-
RMSE is a commonly used formula to measure the error rate of regression models. However, it can only compare models with errors in the same units.
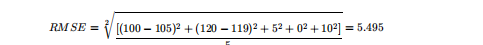
Example:
Assuming the above house price prediction has only five samples, corresponding to:
True values: 100,120,125,230,400
Predicted values: 105,119,120,230,410
Then using RMSE to calculate:
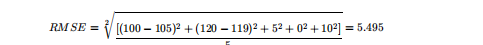
Other evaluation metrics: Relative Squared Error (RSE), Mean Absolute Error (MAE), Relative Absolute Error (RAE)
4.3 Fitting
Model evaluation is used to assess the performance of the trained model, which can be broadly categorized into two types: overfitting and underfitting.
During training, you may encounter the following problem:
Training data performs well with low error, so why is there a problem on the testing set?
When an algorithm exhibits this situation in a dataset, it may be experiencing fitting issues.
4.3.1 Underfitting
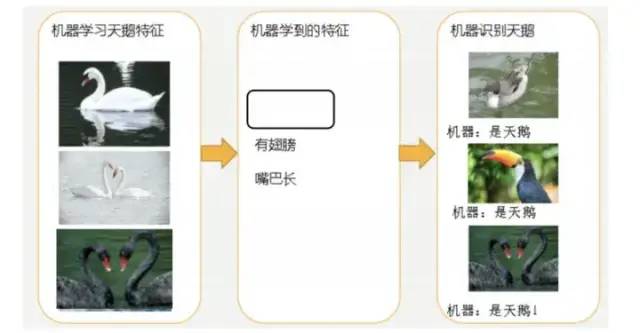
Because the features learned by the machine learning model are too few, the distinguishing criteria are too coarse to accurately identify a swan.
Underfitting: The model learns too roughly, failing to capture the feature relationships in the training set samples.
4.3.2 Overfitting

The machine can distinguish between swans and other animals quite well. However, unfortunately, all existing swan images are of white swans, so after learning, the machine will assume that swan feathers are always white, and when it sees a black swan, it will not recognize it as a swan.
Overfitting: The machine learning or deep learning model performs excessively well on the training samples, leading to poor performance on the testing dataset.
5. Azure Machine Learning Model Building Experiment
Introduction to Azure Platform:
Azure Machine Learning (AML) is a web-based machine learning service launched by Microsoft on its public cloud Azure. Machine learning is a branch of artificial intelligence that uses algorithms to enable computers to recognize large flowing datasets. This approach can predict future events and behaviors based on historical data, and its implementation is significantly superior to traditional business intelligence forms.
Microsoft aims to simplify the process of using machine learning to facilitate widespread and convenient application by developers, business analysts, and data scientists.
The purpose of this service is to “combine the power of machine learning with the simplicity of cloud computing.”
AML is currently available on Microsoft’s Global Azure cloud service platform, and users can apply for a free trial at:https://studio.azureml.net/

-
Azure Machine Learning Experiment
Experiment Purpose: To understand the entire process of machine learning from data to modeling and ultimately to evaluation and prediction.
Editor: Huang Jiyan
