

Introduction by Alibaba Mei: When you search for “tomato”, you can not only learn about its nutritional benefits and calories, but also pick up a recipe for beef stew or scrambled eggs! When did search engines become so accommodating? Behind this is the powerful secret weapon known as the “Knowledge Graph”.
As a hot topic in the fields of search and natural language processing in recent years, the Knowledge Graph is leading the transformation of search engines into knowledge engines. In Alibaba’s “Shenma Search”, the extensive application of Knowledge Graph and related technologies not only helps users find the information they want the most, but also allows them to gain unexpected knowledge.
Background Introduction
In order to continuously enhance the search experience, the Knowledge Graph and Application Team of Shenma Search has been exploring and improving the technology for building graphs. Among them, Open Information Extraction, also known as General Information Extraction, aims to extract structured information from large-scale unstructured natural language texts. It is one of the core technologies for constructing Knowledge Graph data and determines the sustainable expansion capability of the Knowledge Graph.
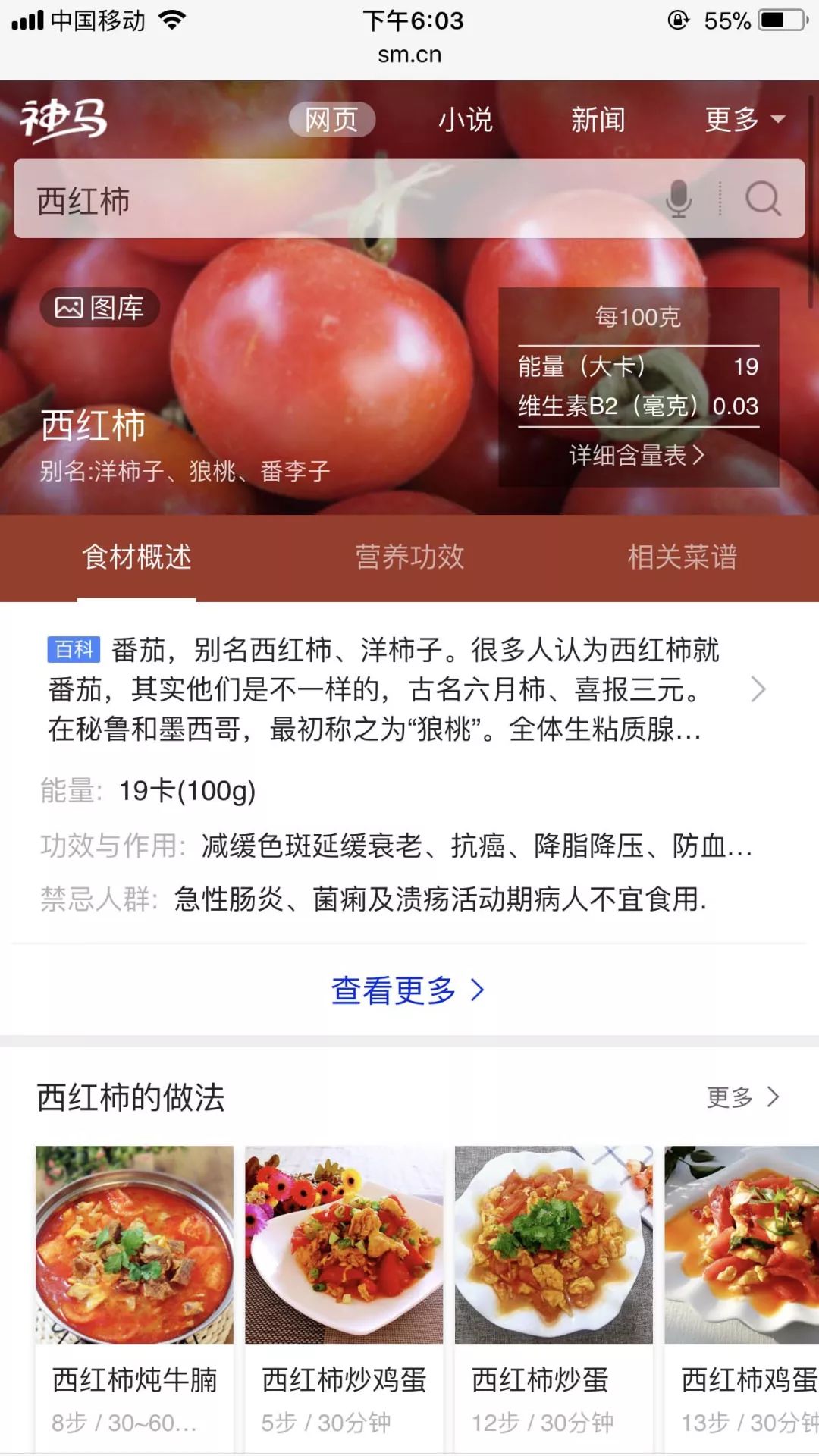
“Shenma Search” Interface
This article focuses on an important sub-task in Open Information Extraction—Relation Extraction. It first provides an overview of various mainstream technologies for relation extraction, and then, in conjunction with business choices and applications, highlights the method based on DeepDive, detailing its application progress in the construction of Shenma Knowledge Graph data.
Overview of Relation Extraction
Classification of Relation Extraction Technologies
Current relation extraction technologies can be mainly divided into three categories:
-
Supervised Learning Methods: This method treats the relation extraction task as a classification problem, designing effective features based on training data to learn various classification models, and then using the trained classifier to predict relations. The drawback of this method is that it requires a large amount of manually labeled training corpus, which is often very time-consuming and labor-intensive.
-
Semi-supervised Learning Methods: This method mainly uses Bootstrapping for relation extraction. For the relations to be extracted, this method first manually sets several seed instances, and then iteratively extracts relation templates and more instances from the data.
-
Unsupervised Learning Methods: This method assumes that entity pairs with the same semantic relation have similar contextual information. Therefore, the contextual information corresponding to each entity pair can represent the semantic relation of that entity pair, and clustering can be performed on the semantic relations of all entity pairs.
Among these three methods, supervised learning has advantages in extracting and effectively utilizing features, achieving high accuracy and high recall rate, and is currently the most widely used method in the industry.
Distant Supervision Algorithm
To break the limitations of manual data labeling in supervised learning, Mintz and others proposed the Distant Supervision algorithm. The core idea of this algorithm is to align text with a large-scale Knowledge Graph, using the existing entity relationships in the Knowledge Graph to label the text. The basic assumption of distant supervision is: if a triple R (E1, E2) can be obtained from the Knowledge Graph (where R represents the relation, E1 and E2 represent two entities), and E1 and E2 co-occur in sentence S, then S expresses the relation R between E1 and E2 and is labeled as a positive training example.
Distant Supervision is a widely adopted method in mainstream relation extraction systems and is also one of the research hotspots in this field. This algorithm effectively addresses the scale problem of data labeling, but its basic assumption is too strong, which introduces a lot of noisy data. For example, from the Knowledge Graph, a triple can be obtained: Founder (Steve Jobs, Apple Inc.). The following sentences 1 and 2 correctly express this relation, but sentences 3 and 4 do not express such a relation, so applying the basic assumption to sentences 3 and 4 will yield incorrect labeling information. This problem is commonly referred to as the wrong label problem.
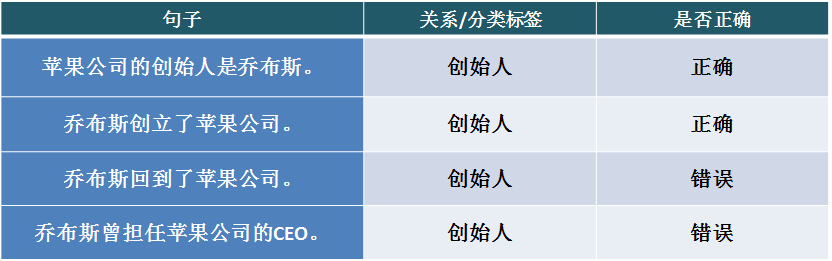
The fundamental reason for the occurrence of the wrong label problem is that distant supervision assumes that an entity pair corresponds to only one relation, but in reality, entity pairs can simultaneously have multiple relations. For example, in the above case, there is also a CEO relation (Steve Jobs, Apple Inc.), and entity pairs may not have the typically defined relation at all, but merely co-occur in a sentence due to their involvement in a shared topic.
To mitigate the impact of the wrong label problem, various improved algorithms have been proposed in academia, mainly including:
-
Rule-based Methods: By statistically analyzing wrong label cases, adding rules to directly mark the originally obtained positive label wrong label cases as negative or offsetting the original positive label through score control.
-
Graph Model-based Methods: Constructing factor graphs and other graph models that can represent the correlation between variables, reducing the impact of wrong label cases on the global scale through feature learning and feature weight inference.
-
Multi-instance Learning Methods: All sentences containing (E1, E2) are grouped into a bag, and sentences are filtered from each bag to generate training samples. This method was first proposed with the assumption that if R (E1, E2) exists in the Knowledge Graph, then at least one instance among all instances containing (E1, E2) in the corpus expresses the relation R. Generally combined with undirected graph models, the sample with the highest confidence in each bag is labeled as a positive training example. This assumption is more reasonable than that of distant supervision, but it may lose many training samples, resulting in a loss of useful information and insufficient training. To obtain richer training samples, the multi-instance multi-label method was proposed. This method assumes that within the same bag, a sentence can only represent one relation for (E1, E2), meaning it can only provide one label, but different sentences can represent different relations for (E1, E2), thus obtaining different labels. The multi-label annotation value is not positive or negative but represents a certain relation. This provides a possible implementation path for simultaneously mining multiple relations for an entity pair. Another improvement method is to select multiple valid sentences from a bag as the training set, generally combined with deep learning methods; more detailed explanations and implementations will be arranged in subsequent chapters introducing deep learning models.
Selection of Relation Extraction Methods in Shenma Knowledge Graph Construction
In terms of data sources, the data construction of the Knowledge Graph is divided into three categories: structured data, semi-structured data, and unstructured data. Among them, unstructured data is the largest and most easily accessible resource, but it is also the most challenging resource to process and utilize. The construction of Shenma Knowledge Graph has now developed into a large-scale Knowledge Graph with nearly 50 million entities and nearly 3 billion relations. After going through the initial stages dominated by structured and semi-structured data, the focus of Shenma Knowledge Graph’s data construction has gradually shifted to how to accurately and efficiently utilize unstructured data for automatic identification and extraction of entities and relations. This construction strategy gives Shenma Knowledge Graph strong competitiveness in the construction of general fields and sustainable expansion.
The Distant Supervision algorithm utilizes existing information from the Knowledge Graph, making large-scale text labeling required in supervised learning possible. On the one hand, distant supervision greatly enhances the scale and accuracy of supervised learning relation extraction, providing possibilities for large-scale Knowledge Graph data construction and supplementation; on the other hand, distant supervision has a strong dependence on the existing data and scale of the Knowledge Graph, and rich labeled data greatly aids in improving machine learning capabilities. To fully leverage the complementary characteristics of the Knowledge Graph scale and distant supervision learning, in the current stage of Shenma Knowledge Graph’s data construction business, we have adopted a relation extraction technology based on the existing large-scale entity and relation data of the graph, using distant supervision algorithms as tools.
In the overview of the previous chapter, we introduced several improved methods based on the idea of distant supervision. In the specific implementation of the business, we selected two representative methods that are most aligned with business needs: the extraction system based on DeepDive and the extraction algorithm based on deep learning. The two methods complement each other and have their respective advantages: the DeepDive system relies more on natural language processing tools and context-based features for extraction, offering more flexibility in the selection of corpus scale, targeted relation extraction, and allowing for easy manual inspection and intervention during the extraction process; while the deep learning method mainly applies word vectors and convolutional neural networks, showing significant advantages in processing large-scale corpus and extracting multiple relations. In the following chapters, we will take a closer look at the implementation and application of these two methods.
Introduction to the DeepDive System
Overview of DeepDive
DeepDive (http://deepdive.stanford.edu/) is an information extraction system developed by Stanford University that can process various formats of unstructured data, including text, tables, charts, and images, to extract structured information. The system integrates functions such as file analysis, information extraction, information integration, and probabilistic prediction. The main application of DeepDive is specific domain information extraction, and since its development, it has achieved good results in projects across multiple fields such as transportation, archaeology, geography, and healthcare; it has also performed well in open-domain applications, such as automatic supplementation of infobox information in Wikipedia and participation in the TAC-KBP competition.
The basic inputs of the DeepDive system include:
-
Unstructured data, such as natural language text
-
Relevant knowledge from existing knowledge bases or Knowledge Graphs
-
Several heuristic rules
The basic outputs of the DeepDive system include:
-
Structured knowledge in specified formats, which can be in the form of relations (entity1, entity2) or attributes (entity, attribute value)
-
Probability predictions for each extracted piece of information
An important iterative step is also included in the operation of the DeepDive system. After each round of output generation, users need to perform error analysis on the results, intervening in the system’s learning through feature adjustments, updating knowledge base information, and modifying rules. This interaction and iterative computation allow the system’s output to be continuously improved.
Architecture and Workflow of the DeepDive System
The architecture of DeepDive is shown in the figure below, which is roughly divided into four processes: data processing, data labeling, learning inference, and interactive iteration:
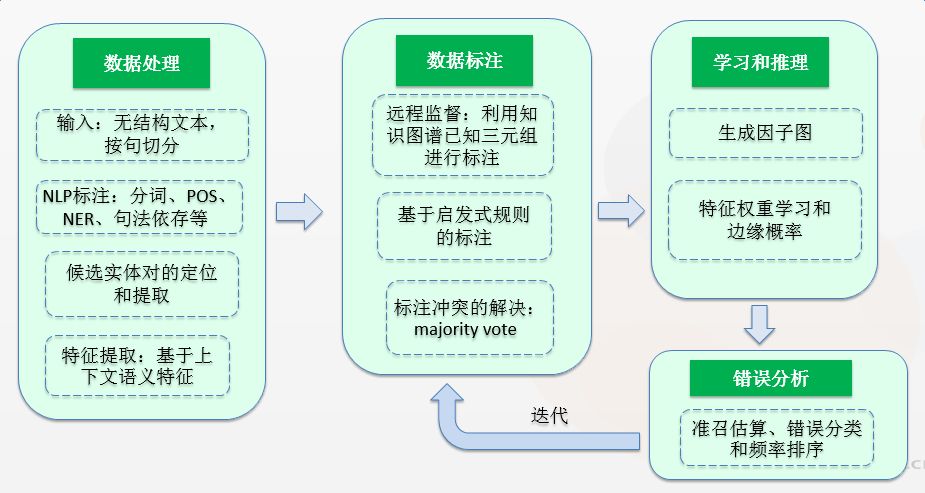
Data Processing
1. Input and Segmentation
In the data processing workflow, DeepDive first receives the user’s input data, usually natural language text, and segments it by sentence. At the same time, it automatically generates text IDs and indexes for each sentence. The doc_id + sentence_index forms a globally unique identifier for each sentence.
2. NLP Labeling
For each segmented sentence, DeepDive uses the embedded Stanford CoreNLP tool for natural language processing and labeling, including token segmentation, lemmatization, POS tagging, NER tagging, marking the starting position of tokens in the text, and dependency grammar analysis.
3. Candidate Entity Pair Extraction
Based on the entity types to be extracted and the NER results, entities are first located and extracted, and then candidate entity pairs are generated according to certain pairing rules. It is important to note that in DeepDive, each entity mention is globally unique, identified by doc_id, sentence_index, and the start and end positions of that mention in the sentence. Therefore, entity pairs (E1, E2) with the same name appearing in different positions will have different (E1_id, E2_id) and the final prediction results will also differ.
4. Feature Extraction
This step aims to represent each candidate entity pair with a set of features so that the subsequent machine learning module can learn the correlation between each feature and the relation to be predicted. DeepDive contains an automatic feature generation module (DDlib) that mainly extracts context-based semantic features, such as the token sequence between two entity mentions, the NER tag sequence, and the n-grams before and after the entities. DeepDive also supports user-defined feature extraction algorithms.
Data Labeling
In the data labeling phase, we obtain candidate entity pairs and their corresponding feature sets. In the data labeling phase, we will use distant supervision algorithms and heuristic rules to label each candidate entity pair, obtaining the positive and negative samples required for machine learning.
1. Distant Supervision
To implement distant supervision labeling, we first need to obtain relevant triples from known knowledge bases or Knowledge Graphs. For example, for marriage relations, DeepDive retrieves existing pairs of married entities from DBpedia. If a candidate entity pair can find a matching mapping in known married entities, that candidate pair is labeled as a positive example. The labeling of negative examples varies depending on the different relations to be extracted. For example, entity pairs that do not appear in the knowledge base can be labeled as negative examples, but this method may introduce noisy negative examples if the knowledge base is incomplete; alternatively, instances under mutually exclusive relations in the knowledge base can be used for negative labeling, such as parent-child relations and sibling relations, which are mutually exclusive with marriage relations and are unlikely to introduce noise.
2. Heuristic Rules
Labeling of positive and negative samples can also be achieved through user-defined heuristic rules. For example, to extract marriage relations, the following rules can be defined:
-
Candidates with person mentions that are too far apart in the sentence are marked as false.
-
Candidates with person mentions that have another person in between are marked as false.
-
Candidates with person mentions that have words like “wife” or “husband” in between are marked as true.
Users can write and modify heuristic rules through the reserved user-defined function interface.
3. Resolving Label Conflicts
When the labels generated by distant supervision conflict with those generated by heuristic rules, or when conflicts arise between labels generated by different rules, DeepDive uses the majority vote algorithm to resolve them. For example, if a candidate pair finds a mapping in DBpedia and receives a label of 1, but also meets the second rule in the previous example, obtaining a label of -1, the majority vote sums all labels: sum = 1 – 1 = 0, resulting in a final label of doubt.
Learning and Inference
After obtaining the training set through data labeling, in the learning and inference phase, DeepDive mainly learns the feature weights and ultimately predicts the probability of candidate triples being true through inference based on factor graph models.
A factor graph is a probabilistic graphical model used to represent variables and the functional relationships between them. Using factor graphs allows for weight learning and marginal probability inference. In the DeepDive system, there are two types of vertices in the factor graph: one is a random variable, which is the extracted candidate entity pair, and the other is a function of the random variable, which includes all features and functions obtained from rules, such as whether the distance between two entities exceeds a certain threshold. The edges in the factor graph represent the relationships between entity pairs and features and rules.
When the scale of the training text is large and involves many entities, the generated factor graph may become very complex and large. DeepDive uses Gibbs sampling to simplify probability inference based on the graph. In feature weight learning, a standard SGD process is employed, and the gradient values are predicted based on the results of Gibbs sampling. To make the acquisition of feature weights more flexible and reasonable, users can also directly assign values to adjust the weight of a certain feature. Due to space constraints, a more detailed learning and inference process will not be elaborated on here; more information can be found on the DeepDive official website.
Interactive Iteration
The iterative phase ensures that through certain manual interventions, errors in the system are corrected, thereby continuously improving the system’s precision and recall rates. Interactive iteration generally includes the following steps:
1. Rapid Estimation of Precision and Recall
-
Precision: Randomly select 100 from the P set and calculate the proportion labeled as TP.
-
Recall: Randomly select 100 positive cases from the input set and see how many fall into the calculated P set.
2. Error Classification and Induction
Each extraction failure (including FP and FN) is categorized and summarized according to the reasons for the errors, sorted by frequency. Generally, the main error reasons include:
-
Failure to capture entities that should have been captured during the candidate set generation phase, typically due to token segmentation, token concatenation, or NER issues.
-
Feature acquisition issues, failing to obtain highly distinguishing features.
-
Feature calculation issues, where highly distinguishing features do not receive corresponding high scores during training (including both positive and negative high scores).
3. Error Correction
Based on the reasons for the errors, the system is adjusted through adding or modifying rules, adding or deleting features, and adjusting the weights of features, and the corresponding modified processes are re-run to obtain new calculation results.
Applications and Improvements of DeepDive in Shenma Knowledge Graph Construction
After understanding the workflow of DeepDive, this chapter will introduce how we use DeepDive in the data construction business of Shenma Knowledge Graph. To fully utilize corpus information and improve system operational efficiency, we have made some improvements to DeepDive in areas such as corpus processing and labeling, control of input scale, and enhancement of input quality, and successfully applied these improvements in the business implementation process.
Chinese NLP Labeling
NLP labeling is an important step in data processing. The Stanford CoreNLP tool that comes with DeepDive mainly processes English texts, while the main processing demand in the application of the Knowledge Graph is for Chinese. Therefore, we have developed an external process for Chinese NLP labeling to replace CoreNLP, with the following main changes:
-
Using Ali word segmentation instead of CoreNLP’s token segmentation, removing lemmatization, POS tagging, and dependency grammar analysis, while retaining NER tagging and marking the starting position of tokens in the text.
-
Token segmentation is changed from being based on words to being based on entities. In the NER stage, tokens segmented by Ali are recombined at the entity level. For example, the segmentation results “Washington”, “State”, “University” will be combined into “Washington State University” and labeled as a complete entity with the NER tag “University”.
-
Long sentence segmentation: Some paragraphs in the text may have sentences exceeding a certain length threshold (e.g., 200 Chinese characters) due to missing correct punctuation or containing numerous parallel items, making the NER step take too long. This situation will be re-segmented according to a predefined set of rules.
Automatic Subject Supplementation
Another improvement in the data processing phase is the addition of an automatic subject supplementation process. For example, in Chinese encyclopedia texts, it has been found that nearly 40% of sentences lack a subject. As shown in the introduction to Andy Lau, all sentences in the second paragraph lack subjects.

The absence of a subject often directly means the lack of one of the entities in the candidate entity pair, which will prevent the system from learning from many sentences containing useful information and severely affect the system’s accuracy and recall rate. The judgment of subject absence involves two aspects:
-
Judgment of subject absence
-
Addition of missing subjects
Since most of the texts involved in current business applications are encyclopedia texts, the strategy for adding missing subjects is relatively simple, i.e., extracting the subject from the previous sentence of the current sentence; if the previous sentence also lacks a subject, the NER result of the encyclopedia title will be used as the subject to be added. The judgment of missing subjects is relatively complex and is currently mainly based on rule-based methods. Assuming that the candidate pair (E1, E2) corresponds to entity types (T1, T2), the judgment process is shown in the figure below:
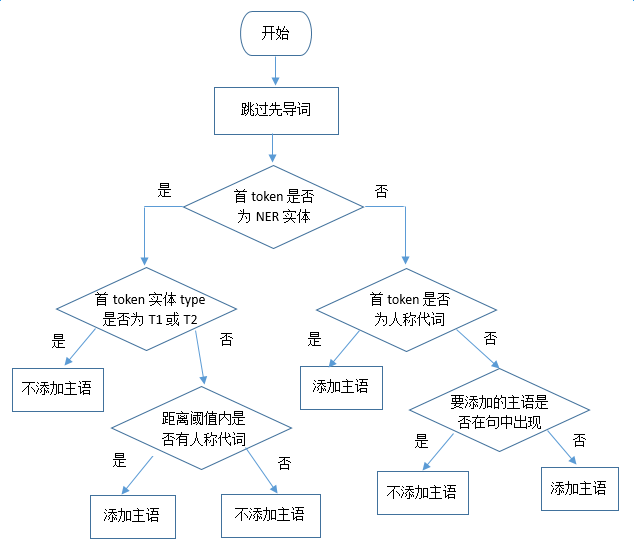
Specific examples and processing processes for subject supplementation are as follows:
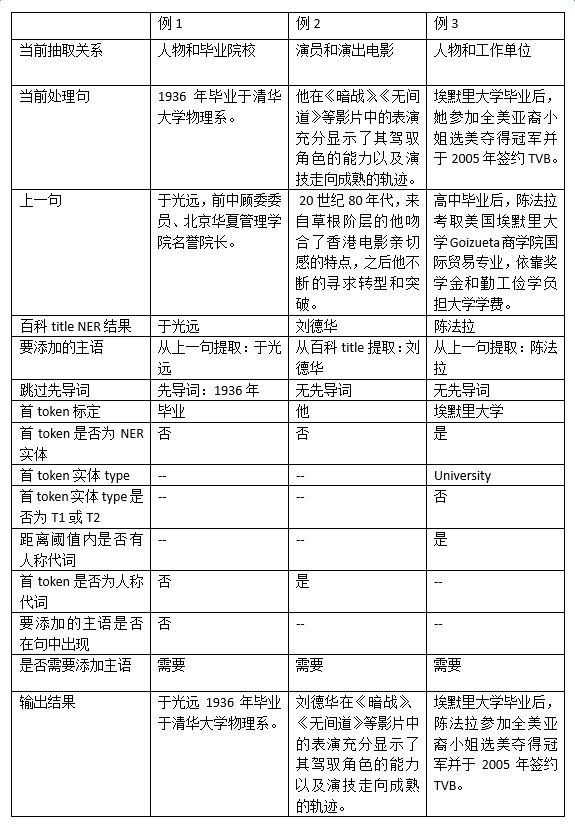
Based on encyclopedia texts, experimental statistics show that the accuracy of the above automatic subject supplementation algorithm is about 92%. From the results of relation extraction, among all error extraction cases, the proportion of errors caused by subject supplementation does not exceed 2%.
Input Filtering Based on Relation-Related Keywords
DeepDive is a machine learning system, and the size of the input set directly affects the system’s runtime, especially in the time-consuming feature calculation and learning inference steps. Reasonably reducing the input set size while ensuring the system’s recall rate can effectively improve system operational efficiency.
Assuming that the triple to be extracted is R (E1, E2) and the entity types corresponding to (E1, E2) are (T1, T2). The default running mechanism of DeepDive is to extract all entity pairs satisfying the type (T1, T2) as candidates during the data processing phase, without considering whether the context has the potential to express the relation R. For example, when extracting marriage relations, as long as a sentence contains at least two person entities, that sentence will be included in the entire data processing, labeling, and learning process. Among the five example sentences below, except for sentence 1, the other four do not involve marriage relations at all:

Especially when the two person entities in the sentence cannot obtain positive or negative labels through distant supervision, such inputs cannot contribute to the system’s accuracy during the learning phase. To reduce the time loss caused by such inputs, we propose the following improvement algorithm:

Experiments have shown that the input set size obtained using the improved algorithm has significantly decreased. For example, in the extraction of encyclopedia texts, the input set for marriage relations can be reduced to 13% of the original input set, while the input set for relationships between people and their alma maters can be reduced to 36% of the original input set. The reduction in input set size can significantly decrease the system’s runtime, and experiments have shown that it eliminates a large number of doubtful labeled entity candidate pairs, leading to a substantial improvement in the system’s accuracy.
It should be noted that although filtering the input set based on relation-related keywords effectively improves system operational efficiency (as it skips all subsequent computation steps, including feature extraction), this filtering occurs at the sentence level rather than on the extracted candidate entity pairs. Consider a multi-person example for marriage relation extraction:
-
In addition to performing guests such as Sun Nan and Na Ying, Mr. Wang Zhonglei, president of Huayi Brothers, director Feng Xiaogang and his wife Xu Fan, as well as stars such as Ge You, Song Dandan, and Li Bingbing all appeared on the red carpet to support this concert.
Because it contains the marriage relation-related keyword “wife”, this sentence will be retained as system input. The multiple candidates for entity pairs extracted from this sentence need to rely on more complete heuristic rules for further labeling and filtering.
Expansion from Entity Pair to Multiple Entities
The majority of tasks in relation extraction only involve the extraction of triples. Triples generally have two forms: one where two entities have a certain relation, expressed as R (E1, E2), for example: marriage relation (Andy Lau, Zhu Lijian); the other is the attribute value of an entity, expressed as P (E, V), for example: height (Andy Lau, 1.74m). The default relation extraction mode of DeepDive is based on triples. However, in practical applications, many complex relations cannot be fully expressed with triples, such as a person’s educational background, which includes the person, their alma mater, major, degree obtained, graduation time, etc. These complex multi-entity relations are represented in Shenma Knowledge Graph using composite types. Therefore, to ensure the extraction task is compatible with the construction of composite types, we made some modifications to DeepDive’s code, expanding the extraction of candidate entity pairs to the extraction of candidate entity groups. Code modifications involve files such as app.ddlog in the main extraction module, DDlib used for automatic feature generation, and map_entity_mention.py and extract_relation_features.py in udf. The figure below shows an expanded example of entity group extraction, where the relation is (person, organization, position):

Application of DeepDive in Data Construction
This section first provides an input example and the output results at each step during the operation of DeepDive, as shown in the figure below. Through this example, we can have a more intuitive understanding of the functions and outputs of each module in DeepDive.
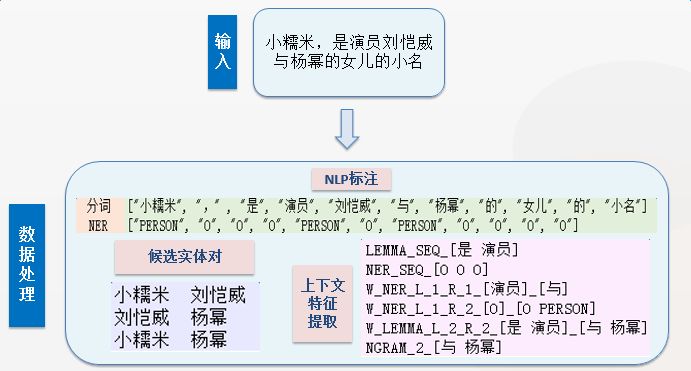
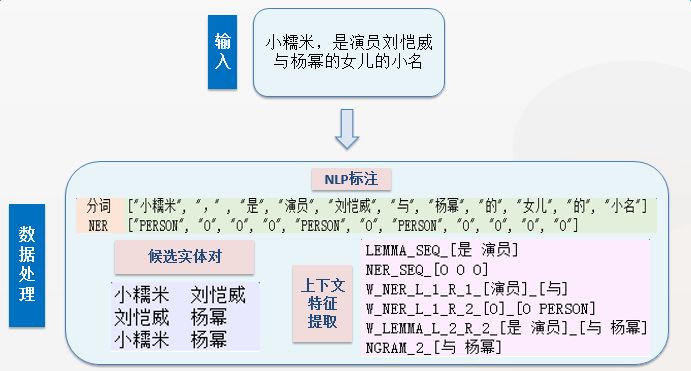
To understand the application of DeepDive and the effects of the improved algorithms in more detail, we provide specific operational data related to a marriage relation extraction task.
The table below shows the time spent and output quantity at each step of the data processing phase for this extraction task:
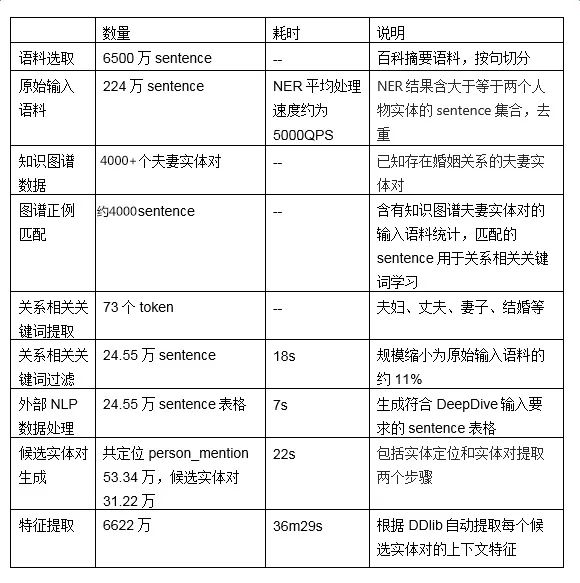
In the remote supervision phase of data labeling, in addition to using existing married relations in the Knowledge Graph for positive labeling, we also used existing parent-child relations and sibling relations for negative labeling, obtaining thousands of positive examples, with a positive to negative labeling candidate entity ratio of about 1:2.

In the DeepDive system, the wrong label problem of distant supervision can be corrected to some extent by reasonably written heuristic rules. Observing the wrong label examples for marriage relations, we find that a large proportion of wrong labels occur when married entities co-occur in a sentence through some form of collaboration (such as collaborative performances, collaborations in singing, or co-authoring books). When one of the married entities appears in quotation marks, misjudgments are also likely to occur. For example:

Similar observations and summaries can be compiled into heuristic rules. The negative labels obtained from rules can offset the positive labels obtained from distant supervision, reducing the bias in the system during learning and inference.
Although the writing of heuristic rules is mostly based on expert knowledge or manual experience, the improvement and expansion of rules can be assisted by certain automated mechanisms. For example, the rule definition states: if the sentence contains “P_1 and P_2 get married”, then (P_1, P_2) receives a positive label. By expanding tokens such as “and” and “married”, we can derive similar contexts that should be labeled as positive, such as “P_1 and P_2 get married”, “P_1 and P_2 after marriage”, and “P_1 and P_2’s wedding”. Here, the token expansion can be achieved through the word2vec algorithm with manual filtering. The table below provides the rules used in this extraction task and the corresponding statistical data. The entire data labeling process took 14m21s.
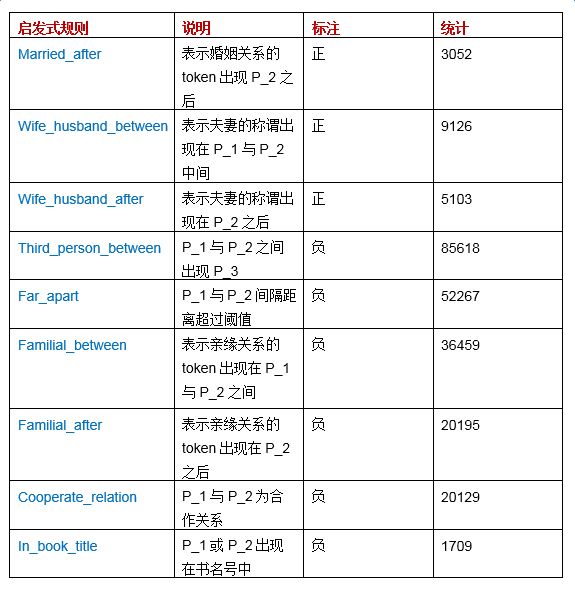
The learning and inference process took about 38m50s. We randomly extracted part of the output results for predicted entity pairs not included in the Knowledge Graph:

For the system’s accuracy, we take the expectation in the range of [0.95, 1] for the output results for segmented statistics, with the statistical results shown in the following chart:

Analyzing the erroneous examples predicted by the system, we summarize several error types. The table below presents error descriptions and examples in descending order of frequency:
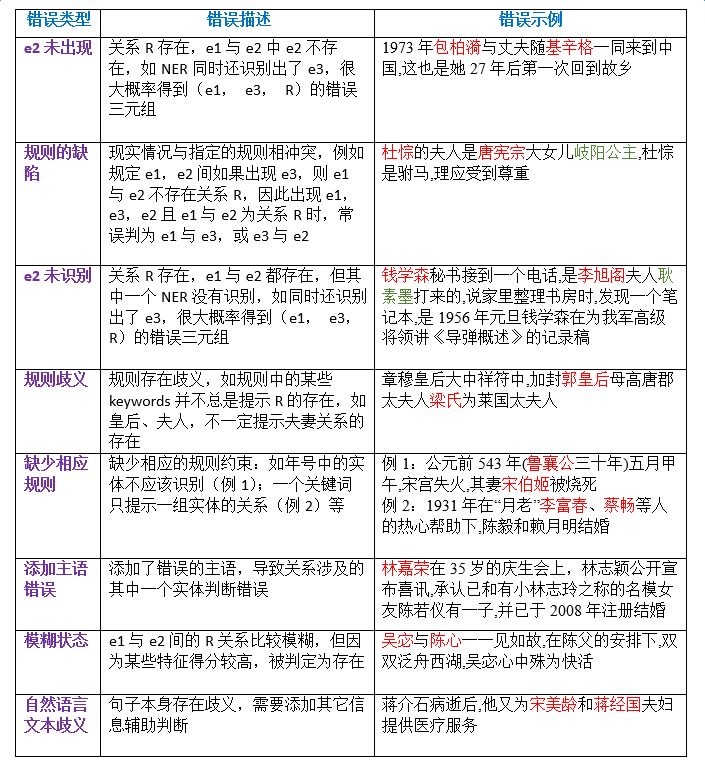
Calculating the recall rate of the system is more complex than calculating the accuracy rate. In scenarios with large corpus scales, accurately estimating the recall rate requires substantial manpower. We adopted a sampling detection method to estimate the recall rate, specifically implementing the following three methods (with the expectation taken to be >=0.95):
-
Sampling all sentences containing a specified entity and calculating recall: There are 78 sentences containing the entity “Yang Mi”, among which 13 sentences contain the entity pair (Yang Mi, Liu Kaiwei), and manual judgment indicates that 9 of them describe the marriage relation of this entity pair, with 5 being recalled, resulting in a recall rate of 0.556.
-
Among the over 4000 entity pairs used for positive labeling with distant supervision, statistics show that 42.7% of the entity pairs appeared in the corpus, and 26.5% of the entity pairs were recalled, resulting in a recall rate of 0.621.
-
Randomly select 100 positive cases from the input set, among which 49 cases have expectation values >=0.95, resulting in a recall rate of 0.49.
Research on relation extraction based on DeepDive is now relatively complete and has been implemented in the business of constructing Shenma Knowledge Graph. Currently, the application in data construction involves multiple core areas such as people, history, organizations, books, and films, with extracted relations including parent, child, sibling, marriage, historical events, co-references of individuals, authors of books, directors and actors of films, and alma maters and employment units of individuals. For example, in the full encyclopedia corpus, the scale of the candidate sentence set for each relation extraction task ranges from 800,000 to 10 million, and after filtering through improved algorithms, the input scale is between 150,000 and 2 million, with the scale of generated candidate entity pairs between 300,000 and 5 million. The time for each round of iterative operation of the system ranges from 1 hour to 8 hours, and after approximately 3-4 rounds of iteration, data with high accuracy and recall rates can be produced for operational review. Since the system’s operation began, nearly 30 million candidate triples have been generated.
In addition, we are continuously exploring and practicing the application of relation extraction technology based on deep learning models in the data construction of Shenma Knowledge Graph. Tomorrow, Alibaba Mei will continue to introduce relevant technological advancements and some challenges encountered in the business implementation process, so stay tuned!
References
[1]. Lin Yankai, Liu Zhiyuan, Relation Extraction Based on Deep Learning [2]. Daojian Zeng, Kang Liu, Yubo Chen, and Jun Zhao. 2015. Distant Supervision for Relation Extraction via Piecewise Convolutional Neural Networks. In EMNLP. 1753–1762.[3]. Guoliang Ji, Kang Liu, Shizhu He, Jun Zhao. 2017. Distant Supervision for Relation Extraction with Sentence-Level Attention and Entity Descriptions. Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence[4]. Siliang Tang, Jinjian Zhang, Ning Zhang, Fei Wu, Jun Xiao, Yueting Zhuang. 2017. ENCORE: External Neural Constraints Regularized Distant Supervision for Relation Extraction. SIGIR’17[5]. Zeng, D.; Liu, K.; Chen, Y.; and Zhao, J. 2015. Distant supervision for relation extraction via piecewise convolutional neural networks. EMNLP.[6]. Riedel, S.; Yao, L.; and McCallum, A. 2010. Modeling relations and their mentions without labeled text. In Machine Learning and Knowledge Discovery in Databases. Springer. 148–163.[7]. Ce Zhang. 2015. DeepDive: A Data Management System for Automatic Knowledge Base Construction. PhD thesis.[8]. Hoffmann, R.; Zhang, C.; Ling, X.; Zettlemoyer, L.; and Weld, D. S. 2011. Knowledge-based weak supervision for information extraction of overlapping relations. In Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies-Volume 1, 541–550. Association for Computational Linguistics.[9]. Surdeanu, M.; Tibshirani, J.; Nallapati, R.; and Manning, C. D. 2012. Multi-instance multi-label learning for relation extraction. In Proceedings of the 2012 Joint Conference on Empirical Methods in Natural Language Processing and Computational Natural Language Learning, 455–465. Association for Computational Linguistics.[10]. Shingo Takamatsu, Issei Sato and Hiroshi Nakagawa. 2012. Reducing Wrong Labels in Distant Supervision for Relation Extraction. Proceedings of the 50th Annual Meeting of the Association for Computational Linguistics, pages 721–729[11]. Zeng, D.; Liu, K.; Lai, S.; Zhou, G.; Zhao, J.; et al. 2014. Relation classification via convolutional deep neural network. In COLING, 2335–2344.[12]. Ce Zhang, Christopher Re; et al. 2017. Communications of the ACM CACM Homepage archiveVolume 60 Issue 5, Pages 93-102[13]. Mintz, M.; Bills, S.; Snow, R.; and Jurafsky, D. 2009. Distant supervision for relation extraction without labeled data. In Proceedings of the Joint Conference of the 47th Annual Meeting of the ACL and the 4th International Joint Conference on Natural Language Processing of the AFNLP: Volume 2, 1003–1011. Association for Computational Linguistics.[14]. http://deepdive.stanford.edu/

You Might Also Like
Click the image below to read

How to Interpret Blockchain Technology with an Architect’s Mindset?

How Did He Self-Learn Technology to Join Alibaba Ten Years Ago?

First Public Release! The Architecture Design of Cainiao’s Elastic Scheduling System

Follow “Alibaba Technology”
Grasp the Pulse of Cutting-Edge Technology