
Produced by Big Data Digest
Source:Zhihu (zibuyu9)
Authors:Han Xu, Gao Tianyu, Liu Zhiyuan
In recent years, the wave of artificial intelligence triggered by deep learning has swept the globe, rapidly enhancing computational resources under the dual support of massive data resources brought by the popularization of the Internet and the Moore’s Law. Deep learning has profoundly impacted various directions of natural language processing, greatly promoting its development. As we arrive in 2019, many limitations of deep learning are gradually being recognized. For natural language processing, achieving fine-grained semantic understanding cannot be resolved solely by relying on data annotation and computational investment. Without prior knowledge support, the phrases “No one can beat China’s table tennis” and “No one can beat China’s football” do not seem to have significant semantic differences from a computer’s perspective, while in reality, the meanings of “beat” in the two sentences are exactly opposite. Therefore, incorporating knowledge to guide natural language processing is the only way to achieve fine and deep language understanding. But where does this knowledge come from? This involves a key research issue in artificial intelligence—knowledge acquisition.
Knowledge Graphs
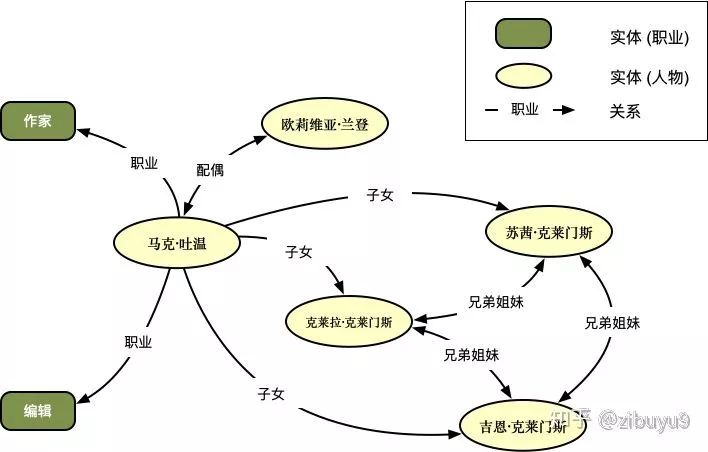
Existing large knowledge graphs, such as Wikidata, Yago, and DBpedia, contain vast amounts of world knowledge and store it in a structured format. As shown in the figure below, each node represents an entity in the real world, and the edges between them indicate the relationships between the entities. For example, knowledge related to American writer Mark Twain is recorded in a structured format.
Currently, this structured knowledge has been widely applied in natural language processing applications such as search engines and question-answering systems. However, compared to the rapidly growing amount of knowledge in the real world, the coverage of knowledge graphs still falls short. Due to the vast scale of knowledge and the high cost of manual annotation, adding new knowledge solely through human annotation is nearly impossible. To enrich knowledge graphs with more world knowledge in a timely and accurate manner, researchers are striving to explore efficient methods for automatically acquiring world knowledge, namely entity relation extraction technology.
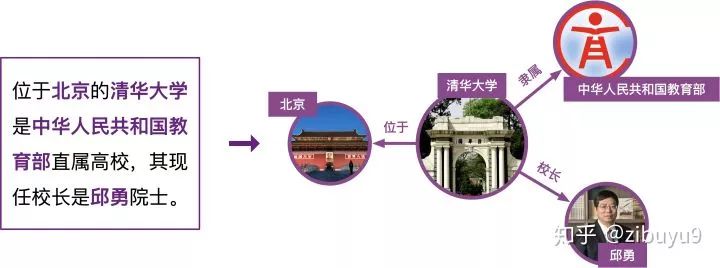
Specifically, given a sentence and the entities that appear in it, the entity relation extraction model needs to infer the relationship between the entities based on the semantic information of the sentence. For example, given the sentence: “Tsinghua University is located near Beijing” and the entities “Tsinghua University” and “Beijing”, the model can infer the relationship “is located in” through semantics and ultimately extract the knowledge triplet (Tsinghua University, is located in, Beijing).

Entity relation extraction is a classic task that has been continuously researched for over 20 years, with feature engineering, kernel methods, and graph models widely applied, achieving some phased results. With the advent of the deep learning era, neural network models have brought new breakthroughs to entity relation extraction.
Neural Network Relation Extraction Models
There are many types of neural networks designed for natural language text sequences, such as Recurrent Neural Networks (RNN, LSTM), Convolutional Neural Networks (CNN), and Transformers. These models can be appropriately modified for relation extraction. Initially, works [1, 2] proposed using CNNs to encode sentence semantics for relation classification, significantly outperforming non-neural network methods; works [3, 4] applied RNNs and LSTMs for relation extraction; furthermore, work [5] proposed using recursive neural networks to model the syntactic parse trees of sentences, attempting to consider both lexical and syntactic features while extracting semantic features, an idea that has been further explored by many subsequent works. Here, we present a table summarizing the performance of various typical neural networks on the benchmark dataset SemEval-2010 Task-8 [6].
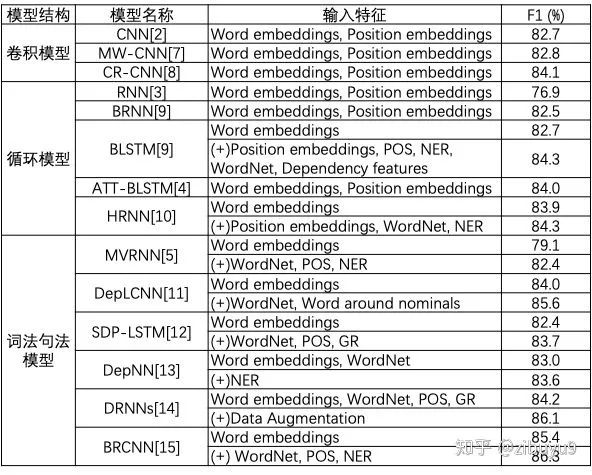
From the table above, it can be seen that these neural network models have achieved excellent experimental results, and there are no significant performance differences among them. Does this mean that the relation extraction problem has been solved? In fact, it is not. The task setting of SemEval-2010 Task-8 is to label a large number of training and testing samples for predefined relation categories, and the samples are relatively simple short sentences, with a fairly uniform distribution of samples for each relation. However, in practical applications, many challenges often arise:
-
Data Scale Issue:Manually annotating sentence-level data accurately is extremely costly, requiring a significant amount of time and manpower. In practical scenarios, facing thousands of relations, millions of entity pairs, and billions of sentences, relying solely on human annotation to train data is nearly impossible.
-
Learning Ability Issue:In reality, the appearance frequency of relations between entities and entity pairs often follows a long-tail distribution, with a large number of relations or entity pairs having few samples. The effectiveness of neural network models relies on large-scale annotated data, leading to the problem of “learning a few from many”. How to improve the learning ability of deep models to achieve “learning a few from many” is a problem that needs to be solved in relation extraction.
-
Complex Context Issue:Existing models primarily extract relations between entities from single sentences, requiring that the sentences must simultaneously contain both entities. In reality, many relations between entities often manifest across multiple sentences within a document, or even across multiple documents. How to perform relation extraction in more complex contexts is another challenge faced by relation extraction.
-
Open Relation Issue:Existing task settings generally assume a predefined closed set of relations, transforming the task into a relation classification problem. In this case, novel relations between entities implied in the text cannot be effectively captured. How to leverage deep learning models to automatically discover new relations between entities and achieve open relation extraction remains an “open” problem.
Thus, there is a significant gap between the ideal setting of SemEval-2010 Task-8 and practical scenarios; relying solely on neural networks to extract single-sentence semantic features makes it difficult to meet the various complex demands and challenges of relation extraction. We urgently need to explore more innovative relation extraction frameworks, acquire larger-scale training data, possess more efficient learning capabilities, be adept at understanding complex document-level contextual information, and be easily extensible to open relation extraction.
We believe these four aspects constitute the main directions for further exploration in entity relation extraction. Next, we will introduce the current state and challenges of development in these four aspects, along with some of our thoughts and efforts.
Larger Scale Training Data
Neural network relation extraction requires a large amount of training data, but manually annotating this training data is very time-consuming and expensive. To automatically acquire more training data for model training, the concept of distant supervision has been proposed, aligning pure text with existing knowledge graphs to automatically annotate large-scale training data.
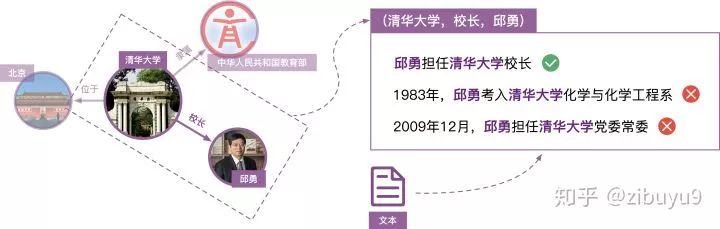
The idea of distant supervision is not complicated; specifically, if two entities are marked as a relation in the knowledge graph, we assume that all sentences containing both entities also express this relation. Taking (Tsinghua University, is located in, Beijing) as an example, we would consider all sentences containing both “Tsinghua University” and “Beijing” as training samples for the relation “is located in”.
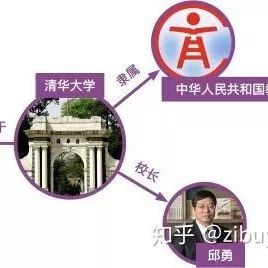
This heuristic annotation rule of distant supervision is a double-edged sword; it is an effective strategy for automatically annotating training data, but its overly strong assumptions inevitably lead to incorrect annotations. For instance, for the knowledge graph triplet (Tsinghua University, president, Qiu Yong), the sentence “Qiu Yong serves as the president of Tsinghua University” reflects the “president” relation between “Tsinghua University” and “Qiu Yong”; however, the sentences “Qiu Yong was admitted to Tsinghua University’s Department of Chemistry and Chemical Engineering” and “Qiu Yong serves as a member of the Tsinghua University Party Committee” do not express the “president” relation but would be incorrectly annotated as training instances for the “president” relation by the heuristic rules of distant supervision.
Although the distant supervision concept is quite simple and has many issues, it has opened a new era for collecting training data. Inspired by this idea, many scholars are actively considering how to minimize the interference of noisy annotations in distant supervision data. Since 2015, neural relation extraction models based on distant supervision and noise reduction mechanisms have made significant progress; work [17] introduced a multi-instance learning approach, utilizing all instances containing the same entity pair to jointly predict the relations between entities. Our research group, led by Lin Yankai et al., proposed a sentence-level attention mechanism that assigns different weights to different instances to reduce the impact of noisy instances. Work [20] introduced adversarial training to enhance the model’s resistance to noisy data. Work [21] constructed a reinforcement learning mechanism to filter out noisy data and utilize the remaining data to train the model.
In summary, existing noise reduction methods for distant supervision can balance the robustness and effectiveness of relation extraction while possessing strong operability and practicality. However, using existing knowledge graphs to align text for obtaining data to train relation extraction models, and then using that model to extract knowledge to add to the knowledge graph, has a sense of a chicken-and-egg problem. Imperfect knowledge graph alignments will yield imperfect text training data, making it difficult to obtain training instances for long-tail knowledge through this distant supervision mechanism. How to propose more effective mechanisms to efficiently acquire high-quality, high-coverage, and balanced training data remains a question worth deep exploration.
More Efficient Learning Ability
Even if high-quality training data can be automatically obtained through methods like distant supervision, due to the long-tail distribution of relations and entity pairs in real scenarios, the available samples for the vast majority of relations and entity pairs remain limited. Moreover, for specialized relations in fields such as healthcare and finance, the available samples are also very limited due to data scale issues. As a typical data-hungry technology, neural network models are significantly affected by the scarcity of training samples. Therefore, researchers hope to explore effective methods to enhance model learning abilities to better utilize limited training samples and achieve satisfactory extraction performance.
In fact, humans can quickly learn knowledge from a small number of samples, demonstrating the ability to “learn a few from many”. To explore the “learn a few from many” capability of deep learning and machine learning, few-shot learning tasks have been proposed. By designing few-shot learning mechanisms, models can utilize generalized knowledge learned from past data, combined with a small number of training samples of new types of data, to achieve rapid transfer learning and exhibit a certain degree of “learn a few from many” ability.
In the past, few-shot learning research primarily focused on the field of computer vision, with little exploration in natural language processing. Our research group, led by Han Xu et al., was the first to introduce few-shot learning into relation extraction, constructing the FewRel few-shot relation extraction dataset, hoping to drive research in few-shot learning for natural language processing, especially in relation extraction tasks. As shown in the figure below, the few-shot learning problem for relation extraction only provides a very small number of samples (e.g., 3-5) for each relation, requiring the model to maximize the relationship classification effectiveness on the test samples.
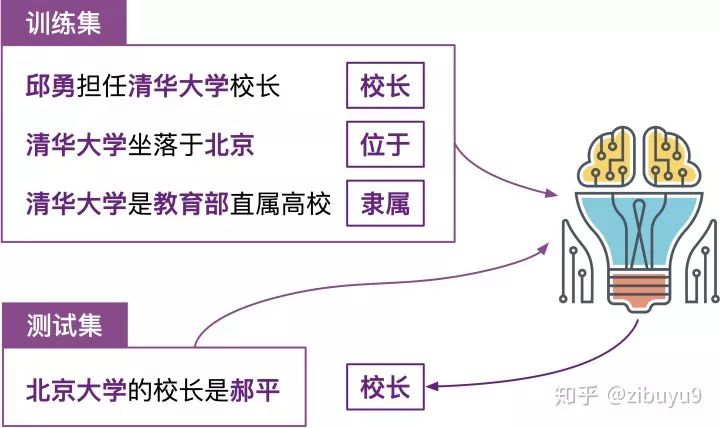
Initial experiments with the FewRel paper attempted several representative few-shot learning methods, including metric learning, meta-learning, and parameter prediction. Evaluations showed that even the best-performing Prototypical Networks model still fell short of human performance in few-shot relation extraction.
To better address the few-shot learning problem in distant supervision relation extraction, our research group’s Gao Tianyu et al. proposed a hybrid attention mechanism-based prototypical network that considers both instance-level and feature-level attention mechanisms, reducing the impact of noisy annotations while better focusing on useful features in sentences. Work [23] proposed a multi-level matching and integration structure to fully learn the potential relationships between training samples, trying to extract potential information from the limited samples. Work [24] adopted the pre-trained language model BERT to tackle the few-shot learning problem in relation extraction, achieving performance that exceeds human relation classification levels on the FewRel dataset.
During the exploration of few-shot learning for relation extraction, our research group, led by Gao Tianyu et al., further identified two long-neglected aspects [25]: to apply few-shot learning models in production environments, they should possess the ability to transfer from resource-rich domains to resource-scarce domains, and they should also be capable of detecting whether a sentence genuinely expresses a predefined relation or does not express any relation at all. To this end, they proposed FewRel 2.0, adding two major challenges to the original FewRel dataset: domain adaptation and “none-of-the-above” detection.
For the domain adaptation challenge, FewRel 2.0 collected a large amount of medical domain data and annotated it, requiring relation extraction models to perform few-shot learning on these new domain corpora after training on the original corpus. For the “none-of-the-above” detection, FewRel 2.0 added a “none-of-the-above” option to the original N-way K-shot setting (providing N new types, each with K training samples), significantly increasing the difficulty of classification and detection.
Initial experiments found that previously effective models (including BERT-based models) experienced significant performance drops on both challenges. Although Gao Tianyu et al. attempted some possible solutions in the FewRel 2.0 paper: for domain adaptation, they tried classic adversarial learning methods, leading to some performance improvement; for “none-of-the-above” detection, they proposed a BERT-PAIR model based on BERT next sentence prediction tasks, achieving some effectiveness in the “none-of-the-above” challenge. However, both challenges still require more innovative exploration.
In summary, exploring few-shot learning for relation extraction to empower relation extraction models with stronger and more efficient learning capabilities is still a very emerging research direction, especially for the few-shot learning problem in relation extraction, which has unique characteristics and challenges compared to few-shot learning problems in other fields. Whether improving existing few-shot learning techniques to suit NLP and relation extraction or proposing entirely new few-shot learning models for relation extraction, both will maximize the utilization of limited annotated data and promote the practical application of relation extraction technology.
More Complex Text Contexts
Current relation extraction work mainly focuses on sentence-level relation extraction, i.e., extracting relations based on intra-sentence information. Various neural network models excel at encoding sentence-level semantic information and can achieve the best results on many public evaluation datasets. However, in practical scenarios, many relations between entities are expressed through multiple sentences. As shown in the figure below, multiple entities are mentioned in the text, demonstrating complex interrelations. Statistics from manually annotated data sampled from Wikipedia indicate that at least 40% of entity relationship facts can only be jointly obtained from multiple sentences. To achieve cross-sentence relation extraction among multiple entities, it is essential to read and reason across multiple sentences in a document, which clearly exceeds the capabilities of sentence-level relation extraction methods. Therefore, document-level relation extraction is imperative.
Research on document-level relation extraction requires large-scale manually annotated datasets for training and evaluation. Currently, there are very few document-level relation extraction datasets available. Works [26, 27] constructed two datasets based on distant supervision, but since they did not undergo manual annotation, their evaluation results are not very reliable. BC5CDR [28] is a manually annotated document-level relation extraction dataset consisting of 1,500 PubMed documents, specific to the biomedical field, and only considers the “chemically induced disease” relation, which may not be suitable for exploring general methods for document-level relation extraction. Work [29] proposed a method to extract entity relationship facts from documents by answering questions using reading comprehension techniques, where the questions are derived from the conversion of “entity-relation” pairs. Since this dataset is tailored for this method, it is also not very suitable for exploring general methods for document-level relation extraction. These datasets either have very few manually annotated relations and entities, or have noise annotations from distant supervision, or serve specific fields or methods, each with its own limitations.
To promote research in document-level relation extraction, our research group, led by Yao Yuan et al., proposed the DocRED dataset, which is a large-scale manually annotated document-level relation extraction dataset constructed from Wikipedia text and the WikiData knowledge graph. It contains 5,053 Wikipedia documents, 132,375 entities, and 53,554 entity relationship facts, making it the largest manually annotated document-level relation extraction dataset currently available. As shown in the figure below, the document-level relation extraction task requires models to possess strong pattern recognition, logical reasoning, coreference reasoning, and common sense reasoning abilities, all of which urgently need further long-term research exploration.

More Open Relation Types
Existing relation extraction work generally assumes a predefined closed set of relations, transforming the task into a relation classification problem. However, in open-domain real relation extraction scenarios, texts contain a large number of open entity relations, with a wide variety of relations, and the number of relations is constantly increasing, far exceeding the number of human-defined relation types. In this case, traditional relation classification models cannot effectively capture new relations between entities implied in the text. How to leverage deep learning models to automatically discover new relations between entities and achieve open relation extraction remains an “open” problem.

To achieve open relation extraction oriented towards open domains, researchers have proposed the Open Relation Extraction (OpenRE) task, which aims to extract any relational facts between entities from open text. Open relation extraction involves three aspects of “openness”: first, the openness of the types of extracted relations; unlike traditional relation extraction, it aims to extract all known and unknown relations; second, the openness of the test corpus, such as news, healthcare, etc., where the texts have different characteristics, necessitating the exploration of cross-domain robust algorithms; third, the openness of the training corpus; to obtain the best possible open relation extraction model, it is essential to fully utilize various existing annotated data, including finely annotated and distant supervision annotated data, and the relation definitions and distributions of different training datasets may vary, requiring the simultaneous utilization of multiple sources of data.
In the pre-deep learning era, researchers also explored the Open Information Extraction (OpenIE) task. Open relation extraction can be seen as a special case of OpenIE. At that time, OpenIE mainly achieved results through unsupervised statistical learning methods, such as the Snowball algorithm. Although these algorithms have good robustness for different data, their precision is often low, and practical application is still far off.
Recently, our research group, led by Wu Ruidong et al., proposed a supervised open relation extraction framework that can flexibly switch between supervised and weakly supervised modes through a “relation siamese network” (RSN), enabling the simultaneous learning of semantic similarities of different relational facts from supervised data of predefined relations and unsupervised data of new relations in open text. Specifically, the relation siamese network RSN adopts a siamese network structure to learn deep semantic features of relation samples from annotated data of predefined relations and their semantic similarities, which can be used to compute semantic similarities of open relation texts. Moreover, RSN employs conditional entropy minimization and virtual adversarial training as two semi-supervised learning methods to further utilize unannotated open relation text data, enhancing the stability and generalization abilities of open relation extraction. Based on the semantic similarity calculated by RSN, the model can cluster text relations in open domains, thus deducing new relations.

Our research group, led by Gao Tianyu et al., approached from another angle; for specific new relations in open domains, only a few precise instances are needed as seeds, allowing for the use of a pre-trained relation siamese network for neural snowballing to deduce more instances of the new relations from a large amount of unannotated text, continuously iterating to train a relation extraction model suitable for the new relations.
In summary, open-domain relation extraction has achieved some results in the pre-deep learning era, but how to effectively combine it with the advantages of neural network models in the deep learning era to significantly expand the generalization capabilities of neural network relation extraction models is worth further exploration.
Conclusion
To expand knowledge graphs more timely, automatically acquiring new world knowledge from massive data has become an essential path. Knowledge acquisition technologies represented by entity relation extraction have achieved some results, especially in recent years where deep learning models have greatly promoted the development of relation extraction. However, compared to the complex challenges of relation extraction in practical scenarios, existing technologies still have significant limitations. We urgently need to address challenges such as training data acquisition, few-shot learning capabilities, complex text contexts, and open relation modeling from the perspective of practical scene needs, establishing effective and robust relation extraction systems, which is also the direction that the entity relation extraction task needs to continue to strive for.
Our research group has been engaged in the entity relation extraction task since 2016, with students such as Lin Yankai, Han Xu, Yao Yuan, Zeng Wenyuan, Zhang Zhengyan, Zhu Hao, Yu Pengfei, Yu Zhijing, Gao Tianyu, Wang Xiaozhi, and Wu Ruidong conducting research in various aspects. Last year, with the efforts of Han Xu and Gao Tianyu, we released the OpenNRE toolkit [33], which has been continuously improved over the past two years, covering rich scenarios such as supervised relation extraction, distant supervised relation extraction, few-shot relation extraction, and document-level relation extraction. In addition, we have spent a significant amount of research funding to annotate datasets such as FewRel (1.0 and 2.0) and DocRED, aiming to promote research in related directions.
This article summarizes our understanding of the current status, challenges, and future development directions of entity relation extraction, as well as our efforts in these areas. We hope to spark interest among everyone and provide some assistance. We look forward to more scholars and students joining the research in this field. Of course, this article does not mention an important challenge, which is the complex structure of knowledge acquisition represented by event extraction; we will discuss this in detail in the future.
Due to personal limitations, there may inevitably be biases and errors, and we kindly ask everyone to point them out in the comments so we can improve. It should be noted that we did not intend to write this article as a rigorous academic paper, so we did not cover every direction and all works comprehensively; if there are significant omissions, please criticize and correct.
References
[1] ChunYang Liu, WenBo Sun, WenHan Chao, Wanxiang Che. Convolution Neural Network for Relation Extraction. The 9th International Conference>
[2] Daojian Zeng, Kang Liu, Siwei Lai, Guangyou Zhou, Jun Zhao. Relation Classification via Convolutional Deep Neural Network. The 25th International Conference>
[3] Dongxu Zhang, Dong Wang. Relation Classification via Recurrent Neural Network. arXiv preprint arXiv:1508.01006 (2015).
[4] Peng Zhou, Wei Shi, Jun Tian, Zhenyu Qi, Bingchen Li, Hongwei Hao, Bo Xu. Attention-Based Bidirectional Long Short-Term Memory Networks for Relation Classification. The 54th Annual Meeting of the Association for Computational Linguistics (ACL 2016).
[5] Richard Socher, Brody Huval, Christopher D. Manning, Andrew Y. Ng. Semantic Compositionality through Recursive Matrix-Vector Spaces. The 2012 Joint Conference>
[6] Iris Hendrickx, Su Nam Kim, Zornitsa Kozareva, Preslav Nakov, Diarmuid Ó Séaghdha, Sebastian Padó, Marco Pennacchiotti, Lorenza Romano, Stan Szpakowicz. SemEval-2010 Task 8: Multi-Way Classification of Semantic Relations between Pairs of Nominals. The 5th International Workshop>
[7] Thien Huu Nguyen, Ralph Grishman. Relation Extraction: Perspective from Convolutional Neural Networks. The 1st Workshop>
[8] Cícero dos Santos, Bing Xiang, Bowen Zhou. Classifying Relations by Ranking with Convolutional Neural Networks. The 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference>
[9] Shu Zhang, Dequan Zheng, Xinchen Hu, Ming Yang. Bidirectional Long Short-Term Memory Networks for Relation Classification. The 29th Pacific Asia Conference>
[10] Minguang Xiao, Cong Liu. Semantic Relation Classification via Hierarchical Recurrent Neural Network with Attention. The 26th International Conference>
[11] Kun Xu, Yansong Feng, Songfang Huang, Dongyan Zhao. Semantic Relation Classification via Convolutional Neural Networks with Simple Negative Sampling. The 2015 Conference>
[12] Yan Xu, Lili Mou, Ge Li, Yunchuan Chen, Hao Peng, Zhi Jin. Classifying Relations via Long Short Term Memory Networks along Shortest Dependency Paths. The 2015 Conference>
[13] Yang Liu, Furu Wei, Sujian Li, Heng Ji, Ming Zhou, Houfeng Wang. A Dependency-Based Neural Network for Relation Classification. The 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference>
[14] Yan Xu, Ran Jia, Lili Mou, Ge Li, Yunchuan Chen, Yangyang Lu, Zhi Jin. Improved Relation Classification by Deep Recurrent Neural Networks with Data Augmentation. The 26th International Conference>
[15] Rui Cai, Xiaodong Zhang, Houfeng Wang. Bidirectional Recurrent Convolutional Neural Network for Relation Classification. The 54th Annual Meeting of the Association for Computational Linguistics (ACL 2016).
[16] Mike Mintz, Steven Bills, Rion Snow, Daniel Jurafsky. Distant Supervision for Relation Extraction without Labeled Data. The 47th Annual Meeting of the Association for Computational Linguistics and the 4th International Joint Conference>
[17] Daojian Zeng, Kang Liu, Yubo Chen, Jun Zhao. Distant Supervision for Relation Extraction via Piecewise Convolutional Neural Networks. The 2015 Conference>
[18] Yankai Lin, Shiqi Shen, Zhiyuan Liu, Huanbo Luan, Maosong Sun. Neural Relation Extraction with Selective Attention over Instances. The 54th Annual Meeting of the Association for Computational Linguistics (ACL 2016).
[19] Yi Wu, David Bamman, Stuart Russell. Adversarial Training for Relation Extraction. The 2017 Conference>
[20] Jun Feng, Minlie Huang, Li Zhao, Yang Yang, Xiaoyan Zhu. Reinforcement Learning for Relation Classification from Noisy Data. The 32th AAAI Conference>
[21] Xu Han, Hao Zhu, Pengfei Yu, Ziyun Wang, Yuan Yao, Zhiyuan Liu, Maosong Sun. FewRel: A Large-Scale Supervised Few-Shot Relation Classification Dataset with State-of-the-Art Evaluation. The 2018 Conference>
[22] Tianyu Gao, Xu Han, Zhiyuan Liu, Maosong Sun. Hybrid Attention-based Prototypical Networks for Noisy Few-Shot Relation Classification. The 33th AAAI Conference>
[23] Zhi-Xiu Ye, Zhen-Hua Ling. Multi-Level Matching and Aggregation Network for Few-Shot Relation Classification. The 57th Annual Meeting of the Association for Computational Linguistics (ACL 2019).
[24] Livio Baldini Soares, Nicholas FitzGerald, Jeffrey Ling, Tom Kwiatkowski. Matching the Blanks: Distributional Similarity for Relation Learning. The 57th Annual Meeting of the Association for Computational Linguistics (ACL 2019).
[25] Tianyu Gao, Xu Han, Hao Zhu, Zhiyuan Liu, Peng Li, Maosong Sun, Jie Zhou. FewRel 2.0: Towards More Challenging Few-Shot Relation Classification. 2019 Conference>
[26] Chris Quirk, Hoifung Poon. Distant Supervision for Relation Extraction beyond the Sentence Boundary. The 15th Conference of the European Chapter of the Association for Computational Linguistics (EACL 2017).
[27] Nanyun Peng, Hoifung Poon, Chris Quirk, Kristina Toutanova, Wen-tau Yih. Cross-Sentence N-ary Relation Extraction with Graph LSTMs. Transactions of the Association for Computational Linguistics (TACL 2017).
[28] Chih-Hsuan Wei, Yifan Peng, Robert Leaman, Allan Peter Davis, Carolyn J. Mattingly, Jiao Li, Thomas C. Wiegers, Zhiyong Lu. Overview of the BioCreative V Chemical Disease Relation (CDR) Task. The 5th BioCreative Challenge Evaluation Workshop (BioC 2015).
[29] Omer Levy, Minjoon Seo, Eunsol Choi, Luke Zettlemoyer. Zero-Shot Relation Extraction via Reading Comprehension. The 21st Conference>
[30] Yuan Yao, Deming Ye, Peng Li, Xu Han, Yankai Lin, Zhenghao Liu, Zhiyuan Liu, Lixin Huang, Jie Zhou, Maosong Sun. DocRED: A Large-Scale Document-Level Relation Extraction Dataset. The 57th Annual Meeting of the Association for Computational Linguistics (ACL 2019).
[31] Ruidong Wu, Yuan Yao, Xu Han, Ruobing Xie, Zhiyuan Liu, Fen Lin, Leyu Lin, Maosong Sun. Open Relation Extraction: Relational Knowledge Transfer from Supervised Data to Unsupervised Data. 2019 Conference>
[32] Tianyu Gao, Xu Han, Ruobing Xie, Zhiyuan Liu, Fen Lin, Leyu Lin, Maosong Sun. Neural Snowball for Few-Shot Relation Learning. The 34th AAAI Conference>
[33] Xu Han, Tianyu Gao, Yuan Yao, Deming Ye, Zhiyuan Liu, Maosong Sun. OpenNRE: An Open and Extensible Toolkit for Neural Relation Extraction. The Conference on Empirical Methods in Natural Language Processing (EMNLP 2019).


Intern/Full-time Editor Journalist Recruitment
Join us to experience every detail of writing for a professional technology media outlet in the most promising industry, and grow alongside a group of the best people from around the globe. Located at the East Gate of Tsinghua University in Beijing, reply “Recruitment” on the Big Data Digest homepage chat page to learn more. Please send your resume directly to [email protected]

