This article is written by Professor Liu Zhiyuan from Tsinghua University and his students Han Xu and Gao Tianyu, introducing the topic of knowledge graphs. The article reviews the development of the knowledge graph field and summarizes recent research progress. It has been authorized for reprint by Machine Heart.
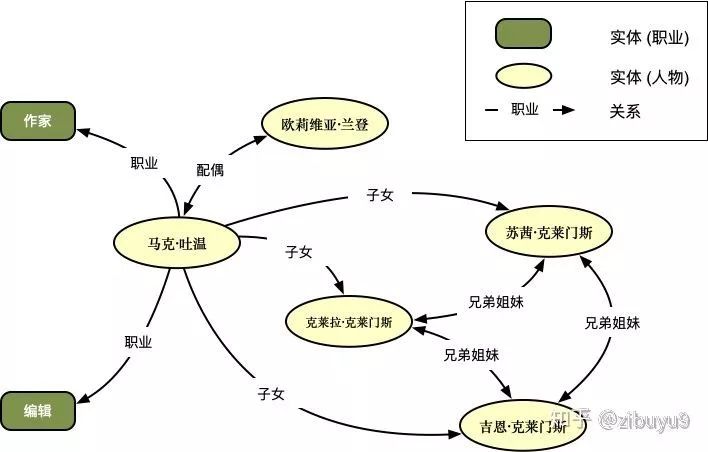
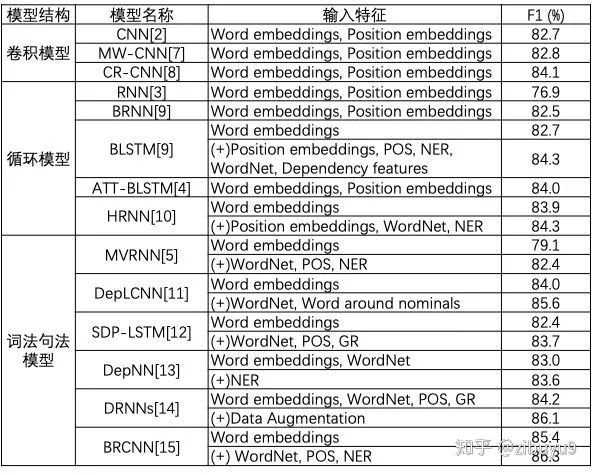
-
Data Scale Issue: Accurately annotating sentence-level data manually is extremely expensive and requires a lot of time and manpower. In practical scenarios, facing thousands of relationships, tens of millions of entity pairs, and hundreds of millions of sentences, relying on manual annotation to train data is almost an impossible task.
-
Learning Ability Issue: In real situations, the frequency of relationships between entities and entity pairs often follows a long-tail distribution, with a large number of relationships or entity pairs having few samples. The performance of neural network models relies on a large amount of annotated data, leading to the “ten to one” problem. How to enhance the learning ability of deep models to achieve “one to many” is a problem that relationship extraction needs to solve.
-
Complex Context Issue: Existing models mainly extract relationships between entities from individual sentences, requiring that the sentences must contain both entities. In reality, many relationships between entities are often expressed across multiple sentences in a document, or even across multiple documents. How to extract relationships in more complex contexts is also a challenge for relationship extraction.
-
Open Relationship Issue: Current task settings generally assume a predefined closed set of relationships, transforming the task into a relationship classification problem. In this case, new types of relationships between entities contained in the text cannot be effectively captured. How to utilize deep learning models to automatically discover new types of relationships between entities and achieve open relationship extraction remains an “open” problem.