
Source | AI Researcher


Introduction This article showcases the application of large language models (LLMs) in real work through the personal experience of Nicholas Carlini and discusses how AI technology is changing our work methods and enhancing productivity.
Table of Contents:
1. Nuances
2. My Background
3. How to Utilize Language Models
4. Evaluating the Capabilities of LLMs, Not Their Limitations
5. Conclusion

In today’s tech world, the debate over whether artificial intelligence is overhyped has never ceased. However, few experts like Nicholas Carlini, a safety researcher and machine learning scientist at Google DeepMind, provide us with a unique perspective through personal experience. Through his article, we see the powerful capabilities and diversity of large language models (LLMs) in practical applications. These are not hollow marketing claims, but tools that can truly change work methods, enhance productivity, and spark creativity.
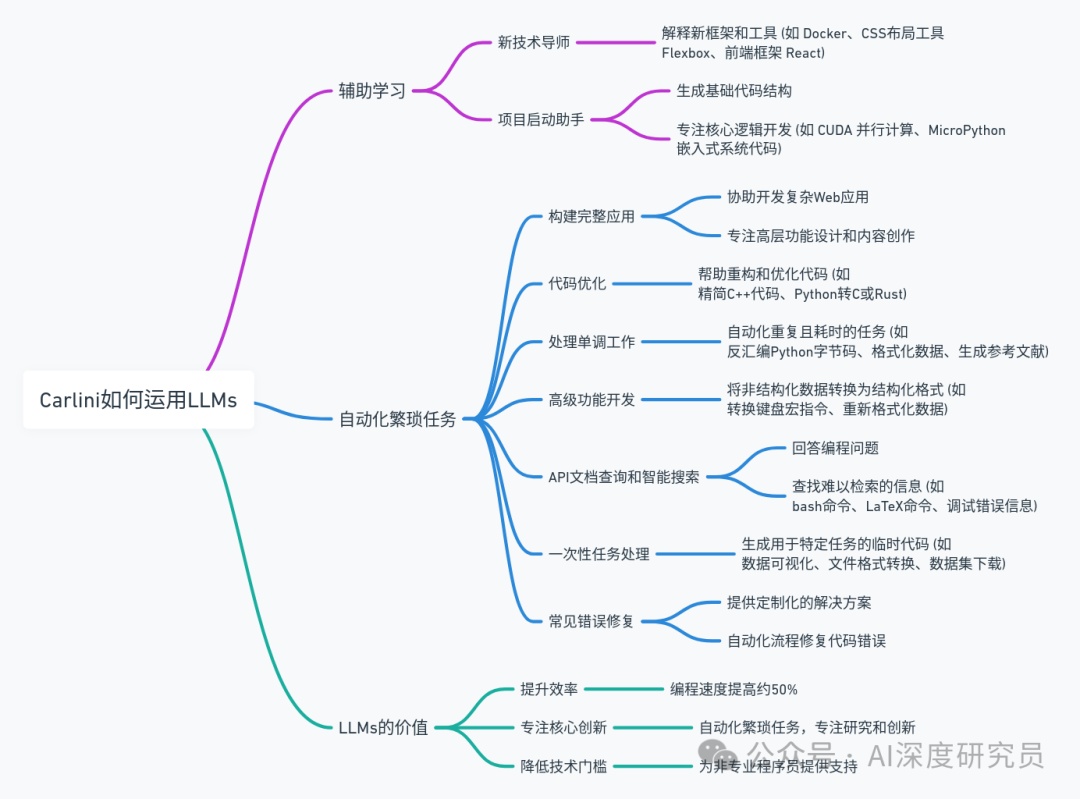
Carlini lists 50 instances of how he personally uses AI, covering aspects like work efficiency, creative writing, and programming assistance. However, surprisingly, these 50 examples are just the tip of the iceberg of his AI applications—he estimates they represent less than 2% of his actual usage. This transformation is astounding, reflecting not only the depth and breadth of AI technology but also highlighting the potential of AI that we might not have fully recognized yet.
Indeed, Carlini’s experience may herald a broader trend: as AI technology continues to advance and proliferate, we may be standing at the forefront of a technological revolution. Just as personal computers and the internet fundamentally changed our lifestyles and work methods, AI may become the next key force driving social change.
So, in the face of such prospects, how should we view the development of AI technology? With caution, or should we embrace the change?
The Original Text is as Follows:Author: Nicholas Carlini, Safety Researcher and Machine Learning Scientist at DeepMind
-
Building an entire web application using technologies I had never used before. -
Teaching me how to use various frameworks, even though I had never used them before. -
Converting dozens of programs to C or Rust for a 10-100x performance increase. -
Simplifying large codebases, significantly streamlining projects. -
Writing initial experimental code for almost every research paper I authored in the past year. -
Automating almost all monotonous tasks or one-off scripts. -
Almost completely replacing web searches that help me set up and configure new packages or projects. -
Achieving about a 50% replacement rate for web searches when helping me debug error messages.
Nuances
My Background
Typically, I am not the kind of person who easily believes in anything. For instance, despite experiencing the cryptocurrency craze in the information security field a decade ago, I never participated in writing any research papers on blockchain. I have never owned any Bitcoin because I believe they have no real value other than for gambling and fraud. I have always been skeptical, and whenever someone claims that “a new technology will change the world,” my response has always been indifference.
Therefore, when someone first told me that AI would greatly enhance my work efficiency and change my daily work methods, I was equally reserved, responding, “I will believe it when I see the actual results.”
Additionally, I am a security researcher. In nearly a decade of work, I have focused on demonstrating how AI models can completely fail in environments they have never been trained on. I have shown that even a slight perturbation to the input of machine learning models can lead to completely erroneous outputs; or that these models often merely memorize specific cases from their training data and simply repeat them in practical applications. I am acutely aware of the limitations of these systems.
However, now I am here to say that I believe current large language models are the greatest enhancement to my productivity since the advent of the internet. Frankly, if I had to choose between using the internet and a cutting-edge language model today to solve a random programming task, I would likely choose the language model more than half the time.
How to Utilize Language Models
1. Developing Complete Applications for Me
I used to be able to keep up with various emerging frameworks. However, one person’s time is limited, and due to my job nature, I spend most of my time keeping up with the latest research developments rather than the latest JavaScript frameworks.
This means that when I start a new project outside my research area, I typically have two choices: either use the technologies I already know, which may be outdated by ten or twenty years but are usually sufficient for small projects, or try to learn new (often better) methods.
This is where language models come into play. For me, newer frameworks or tools like Docker, Flexbox, or React may be familiar to others. There may be thousands of people in the world who are already very familiar with these technologies. Current language models can do this too.
This means I can learn any knowledge needed to solve tasks through interactive learning with language models without relying on static tutorials that assume the reader has specific knowledge and clear objectives.
For instance, earlier this year, when building an LLM evaluation framework, I wanted to run code generated by LLMs in a constrained environment to avoid it deleting random files on my computer and other issues. Docker was the ideal tool for this task, but I had never used it before.
Importantly, the goal of this project was not to learn how to use Docker; Docker was just a tool I needed to achieve my goal. I only needed to grasp 10% of Docker to ensure I could use it safely in the most basic manner.
If it were the 90s, I might have needed to buy a book on Docker and learn from scratch, reading the first few chapters and then trying to skim through to find out how to implement what I wanted. Over the past decade, things have improved; I might have searched online for tutorials on how to use Docker, followed the operations, and then searched for error messages I encountered to see if anyone had faced the same issues.
But today, I only need to ask a language model to teach me how to use Docker.
4. Code Simplification
Real programmers read the reference manuals when they want to understand how a tool works. But I’m a lazy programmer; I prefer to get the answer directly. So now I ask language models.
When I show these examples to people, some become somewhat defensive and say, “LLMs haven’t done anything you couldn’t accomplish with existing tools!” You know what? They’re right. But what can be done with a search engine can also be done with a physical book on the subject; what can be done with a physical book can also be done by reading the source code.
However, each method is simpler than the previous one. When things become simpler, you will do them more frequently, and the way you approach them will also change.
That’s how I ask, “Which $ command can pass all remaining parameters” and get the answer. (Followed by another question, “How should I use this thing!”) This is actually one of the ways I most commonly use LLMs. The reason I can’t show you more such examples is that I have tools built into my Emacs and shell to query LLMs. Therefore, when I want to do these things 90% of the time, I don’t even need to leave my editor.
Searching for content on the internet used to be a skill that needed to be learned. What specific vocabulary do you want to include in your query? Should they be plural or singular? Past tense? What words do you want to avoid appearing on the page? Am I looking for X and Y, or X or Y?
Now, things are different. I can’t remember the last time I used OR in Google. I also can’t remember the last time I used a minus (-) to remove a subset of results. In most cases, today you just need to write down what you want to find, and the search engine will find it for you.
But search engines are still not 100% natural language queries. It’s still a bit like playing a game of reverse danger, trying to use keywords that would be in the answers rather than the questions. This is a skill I think we’ve all almost forgotten we learned.
For some simple tasks today (and over time, there will be more), language models are simply better. I can directly input, “So I know + corresponding to __add__, but what is it” and it will tell me that the answer is __inv__. This is something that is difficult to search for using standard search engines. Yes, I know there are ways to ask so that I can find the answer. Maybe if I input “python documentation metaclass ‘add'” I can search for it on the page and get the answer. But you know what else works? Just asking the LLM your question.
Doing this saves a few seconds each time, but when you’re in the midst of solving a coding task, trying to remember a million things at once, being able to spill out the problem you’re trying to solve and get a coherent answer is amazing.
This is not to say that they are perfect in this regard today. Language models only know things when they have been repeated online frequently enough. What “frequently enough” means depends on the model, so I do need to spend some effort thinking about whether I should ask the model or the internet. But the models will only get better.
Or, whenever I encounter a random crash, I will dump what I saw to the model and ask for an explanation, just like I did here when I simply input “zsh no matching remote wildcard transfer problem.” Or as a completely separate example, last year when I was writing a blog post, I wanted the first letter capitalized and the rest of the text to wrap around it, just as I did in this sentence. This is now referred to as sinking capitalization. But I didn’t know this. I only knew the effect I wanted, so I asked the language model, “I want it to look like a fancy book, with the text wrapping around O,” and it gave me what I wanted: this task is another one of those “I only did this because of LLMs” categories—I wouldn’t consider it worth spending a lot of time figuring out how to do it. But because I could directly ask the model, I did it, and it made my post look a bit better.
There are two types of programs. First, you have some programs you want to get right; they will exist for a while because you need to maintain them for years, so code clarity is important. Then you have those programs that exist for only about 25 seconds; they help you complete certain tasks and are then immediately discarded.
In these cases, I don’t care about the quality of the code at all, and the programs are completely independent, so I now almost exclusively use LLMs to write these programs for me.
Note: Most of these situations arise again, and you’ll look at them and say, “Is that it?” But as I mentioned earlier, I only have so many hours a day to work on a project. If I can save time and effort writing a one-off program, I will choose to do so.
Perhaps the most common example is helping me generate some charts to visualize some data I generated as results from certain research experiments. I have dozens of such examples. Probably close to a hundred instead of zero. They all look basically the same; here’s just one example: or another similar example when I have some data in one format and want to convert it to another format. Usually, this is something I only need to do once, and once completed, I will discard the generated script. But I could also give you a thousand other examples. Generally, when I have a sufficiently simple script I want to write, I will directly request the LLM to write it as a whole. For example, here I asked the LLM to write a script to read my paper aloud so that I could ensure they don’t have any silly grammatical issues. In many cases, when I’m not quite sure what I want, I also start by asking the model to provide some initial code and then iterate from there. For example, here’s a one-off task where I just needed to quickly process some data. In 2022, I would have spent two minutes writing this in Python and waited for hours because it only runs once—the time needed to optimize it would take longer than the Python program’s runtime. But now? You can bet I would spend the same two minutes requesting Rust code to process the data for me. Or here’s another example where I asked the model to download a dataset and do some initial processing on it. Is this easy for me to do? Perhaps. But that’s not the task I want to think about; what I want to consider is the research I will do with the dataset. Eliminating distractions is incredibly valuable, not just saving a few minutes of time.
Another time, I wrote a program so that I could 3D print some pixelated images using small cubes. For this, I wanted to convert PNG files to STL files; but this is not the focus of the project. This is just something that must happen along the way. So I requested the LLM to solve this problem for me. Or as another example, I recently wanted to set up a new project using Docker Compose. I encountered some issues and just wanted to get it running, and then I would figure out what went wrong. So I just went back and forth, copying one error message after another until it finally gave me a valid solution. I also find myself in many situations requesting a complete solution first and then asking for hints on how to modify it. In this conversation, I first requested a program to parse HTML, then requested API references or hints on how to improve it. Recently, I’ve been trying to do some electronics-related tasks; I have a C program running on Arduino, but I want it to run on Raspberry Pi Pico using MicroPython. The conversion process is not interesting; it just needs to be done. So I didn’t do the work myself; I just asked the language model to do it for me. For another project, I needed to classify some images in some interactive loops using some fancy ML models. I could have written it myself, or I could just ask the model to do it for me directly.
10. Explaining Things to Me
I recently started developing an interest in electronics. I did some electronic projects when I was younger and took a few related courses in college. But now that I want to engage in practical electronics projects, I find there are many details I don’t understand, making it difficult to start any project.
I could read a book on practical electronics. I might actually do this at some point to thoroughly understand the subject. But I don’t want to spend my time feeling like I’m learning. Part of the reason I engage in electronics is to step away from reading and writing all day.
This is where LLMs excel. They may not be as knowledgeable as the world’s best experts, but there are likely thousands of people who might know the answers to any electronics question I might ask. This means that language models are likely to know the answers too. They are happy to provide me with answers to all my questions, allowing me to enjoy the fun without getting bogged down in details. While I could certainly find answers by searching online, the convenience of simply having the model do this work for me after a busy day feels very relaxing.
Here are some examples showing how I ask language models about how things work in electronics. Are these answers perfect? Who knows? But you know what they’re better than? Being completely clueless.
11. Solving Tasks with Known Solutions
Almost everything has been done by someone before. The things you want to do are rarely truly novel. Language models are particularly good at providing solutions to things they have seen before.
In a recent project, I needed to enhance the performance of some Python code. So, I (1) requested the LLM to rewrite it in C, and then (2) asked it to build an interface so that I could call the C code from Python.
These tasks are not “difficult.” Converting Python to C is something I am confident I could complete in an hour or two. Although I do not fully understand how the Python to C API works, I believe I could figure it out by reading the documentation. But if it were up to me, I would never do it. It’s not part of the critical path; I would rather let the computer solve the problem than spend time speeding up tasks I don’t frequently need to run.
However, converting Python to C is primarily a technical process for simple programs, and there is a standard Python to C calling convention. So, I directly asked the LLM to help me with it.
Since then, I have begun to expect this to be something I can do; almost any time I need some high-speed code, I describe what I want in Python and request optimized C code. Other times, I do the same thing, but if I think comparing the correctness of Rust output to C output is easier, I will request Rust output. Or, as another example, parallelizing a Python function using the multiprocessing library is not difficult. You need to write some boilerplate code, and it will basically do it for you. But writing code can be a bit painful, which hinders the actual work you want to accomplish. Now, whenever I need to do this, I just request an LLM to help me. There are many times when, while trying to test an API, I initially write a curl request to start. Once it starts working, I want to repeat the task programmatically, and I will convert it to Python. In the past, I would have done something very ugly, directly calling os.popen() to run the curl command, but that’s not ideal. A better way is to convert it to Python’s requests library; but that takes time, so I wouldn’t do it. But now I can simply ask an LLM to help me with it and get a cleaner program in less time. For an upcoming project, I might discuss here what people commonly use as simple radio transmitters. Because what I really want is the answer from most people, LLMs are a perfect choice!
Before 2022, when I encountered error messages from some popular tools or libraries, I generally followed these steps:
-
Copy the error message.
-
Paste it into Google search.
-
Click the top Stack Overflow link.
-
Confirm whether the problem matches what I encountered; if not, return to step 2.
-
If ineffective, return to step 2, change search terms, pray, etc.
Now, what is this process like in 2024?
-
Copy the error message.
-
Ask the LLM, “How do I fix this error? (error)”
-
If ineffective, feedback “That didn’t work.”
I don’t have any conversation records to show these examples. (Or rather, I searched for an hour and couldn’t find any.) But there’s a very good reason for this: I have integrated it into my workflow.
I am an Emacs user. I set up my environment so that whenever I run a program and it exits with a non-zero status code (indicating an error occurred), it automatically calls the latest and fastest LLM and asks it to explain the answer while requesting a patch that can be directly applied to fix the bug in the code.
Most of the time, today’s models are not yet good enough to outperform me in this task, but they are gradually improving. Occasionally, when an LLM fixes a bug that I know would be very difficult to trace if I were to do it myself, especially when the error is simply due to a small typo, I am pleasantly surprised.
13. And Countless Other Things
All the conversations I mentioned above account for less than 2% of my total interactions with LLMs over the past year. The reason I haven’t provided links to other examples is not that these are cases of model failure (although there are many such cases), but because: (1) many interactions repeat the patterns I have already mentioned, or (2) they are not easy to explain clearly what happened and why it was useful to me.
I fully expect the frequency with which I use these models to continue increasing. As a reference, my LLM queries through the web interface in 2024 increased by 30% compared to 2023—and I can’t even quantify the increase in API queries, but I guess it has at least doubled or tripled.
Evaluating the Capabilities of LLMs, Not Their Limitations
-
… counting the number of words in a sentence! -
… writing a poem where every word starts with the letter “a” -
… multiplying two-digit numbers -
… randomly selecting an element from a list
Conclusion
The intention behind writing this article is twofold. First, as I mentioned at the beginning of the article, I want to demonstrate that LLMs have provided me with significant value. Additionally, I’ve noticed that many people express interest in using LLMs but do not know how they can help themselves. Therefore, if you are one of those people, I hope to provide some examples through my use cases.
Because at least for me, LLMs can do many things. They cannot do everything, nor can they do most things. But the current models, as they exist now, provide me with considerable value.
After showcasing these examples, a common rebuttal I receive is, “But these tasks are simple! Any undergraduate in computer science could learn how to do this!” Indeed, undergraduates can tell me how to properly diagnose CUDA errors and which packages can be reinstalled after a few hours of searching. Undergraduates can rewrite that program in C after a few hours of work. Undergraduates can teach me anything I want to know about that subject after a few hours of studying the relevant textbooks. Unfortunately, I don’t have a magical undergraduate who can answer any question at my disposal. But I have language models. So, while language models are not yet good enough to solve the interesting parts of my work as a programmer, and the current models can only solve simple tasks.
But five years ago, the best LLMs could do was write paragraphs that looked like English. When they could form coherent thoughts from one sentence to the next, we were all amazed. Their practical utility was almost zero. However, today, they have increased my productivity in programming projects by at least 50% and eliminated enough tedious work to allow me to create things I otherwise would never have attempted.
Therefore, when people say, “LLMs are just hype” and “all LLMs have provided no real value to anyone,” it is clear they are mistaken because they have provided me with value. Now, perhaps I am an exception. Maybe I am the only one who has found ways to make these models useful.
I can only speak for myself.
Previous Recommendations
Volcano Engine’s Evolution and Practice Based on Large Model ChatBI
AI Changes Work: Build Your Own RAG in One Day
Observability Research Practice of Multi-Agent Systems (OpenAI Swarm)
JD Data Architecture Analysis: Supply Chain Efficiency Improvement and Decision Optimization Strategy
Exploration Practice of Memory Optimization in Large Model Inference
Ant Group and My Bank’s Unified Dynamic Correction Framework: A New Perspective on Non-Random Missing Problem Optimization
Data Security and Utilization in the Era of Large Models
Breaking Down Data Access Barriers: Alluxio’s Applications and Practices in AI/ML Scenarios
Exclusive Interview with Li Feifei’s Disciple, Stanford AI Doctor, a16z Invests Millions, AI Video Monthly Revenue Soars 200%
Dialogue with Nvidia’s Jensen Huang: Machine Learning is Not Just About Software but Involves the Entire Data Pipeline; The Flywheel Effect of Machine Learning is Most Important

Give a look to your best view
SPRING HAS ARRIVED
