
Chatbot Practice
A chatbot is a computer program designed to simulate human conversation or chat, essentially enabling machines to understand human language through technologies like machine learning and artificial intelligence. It integrates methods from various disciplines and serves as a concentrated training camp in the field of artificial intelligence. In the coming decades, the way humans interact with machines will undergo a transformation. More and more devices will have networking capabilities, and how these devices interact with people will become a challenge. Natural language is becoming a new interaction method suited to this trend, and chatbots are expected to replace past websites and current apps, occupying a new generation of human-computer interaction. In the future, chatbot products will not require humans to adapt to machines but rather machines to adapt to humans, with AI-based chatbot products gradually becoming mainstream.
Chatbots can be categorized based on their dialogue generation methods into retrieval-based models and generative models. For retrieval-based models, we can utilize search engines like Solr Cloud or ElasticSearch. For generative models, we can implement the Seq2Seq algorithm using deep learning frameworks like TensorFlow or MXnet, while also incorporating reinforcement learning ideas to optimize the Seq2Seq algorithm. Below, we will discuss the principles and hands-on implementation of chatbots.

Chatbots can be divided into three types: casual chatbots, question-answering chatbots, and task-oriented chatbots. Let’s discuss their principles separately.
1. Casual Chatbots
The main function of casual chatbots is to engage users in casual conversations, examples include Microsoft’s Xiaoice and WeChat’s Xiaowei, as well as the earlier Xiao Huang Ji. When chatting with a casual chatbot, users do not have a specific purpose, and the chatbot does not have a standard answer, but responds in a fun manner to please users. As time goes on, user demands are increasing, and they expect chatbots to have more functionalities beyond just casual chatting. Meanwhile, enterprises also need to continuously explore the commercialization of chatbots to achieve greater business value.
Currently, chatbots can be classified based on their dialogue generation methods into retrieval-based models and generative models.
1) Retrieval-Based Models
Retrieval-based models have a predefined set of responses, and we need to design some heuristic rules that can select appropriate responses based on the input question and context.
The advantages of retrieval-based models include:
(1) High readability of responses
(2) Strong diversity of responses
(3) Easier to analyze and locate irrelevant responses, making bug fixing simpler
However, its disadvantage is that it requires ranking the candidate results for selection.
2) Generative Models
Generative models do not rely on a predefined set of responses but generate a new response based on the input question and context.
The advantages of generative models include:
(1) End-to-end training is relatively easy to implement
(2) Avoids the need to maintain a large Q-A dataset
(3) No additional tuning is required for each module, avoiding the error cascading effect between different modules
However, its disadvantage is that it is challenging to guarantee the generated results are readable and diverse.
These two technical routes of chatbots currently still seem to be at the bottom of the development curve, and both face common challenges in the long term:
(1) How to utilize information from previous dialogue rounds in the current dialogue
(2) Merging existing knowledge base content
(3) Achieving personalization, tailoring responses to individual users. This is somewhat similar to our information retrieval systems, where we hope to perform better in specialized fields while also having different sorting preferences for different users’ queries.
From a development perspective, retrieval-based chatbots can use Solr Cloud or ElasticSearch to store prepared Q-A pairs as two fields in a search index. During a search, we can look up the question field using keywords or sentences to obtain a candidate set of answers for similar questions. We can then personalize the response based on the user’s historical chat records or other business data, delivering the most relevant answer to the user. Generative models can be implemented using the seq2seq+attention approach, where seq2seq, short for Sequence to Sequence, is a network structured as Encoder-Decoder. Its input is a sequence of questions, and its output is also a sequence of answers. The Encoder transforms a variable-length signal sequence into a fixed-length vector representation, and the Decoder converts this fixed-length vector back into a variable-length target signal sequence. Applying reinforcement learning to Seq2Seq can enhance the persistence of multi-turn dialogues.
2. Question-Answering Chatbots
Current intelligent customer service systems are classic cases of the commercial implementation of chatbots. Major mobile manufacturers have introduced standard voice assistants, and industries such as finance, retail, and telecommunications have successively integrated intelligent customer service to assist human agents…
The essence of question-answering chatbots is to find knowledge points that semantically match the user’s questions within a specific domain knowledge base.
When customers inquire about product information, pre-sales, after-sales, and other basic questions, question-answering chatbots can provide timely and accurate responses. When the chatbot cannot answer a user’s question, it will transfer the customer to a human agent through a certain mechanism. Therefore, question-answering chatbots that have a specific domain knowledge base are smarter, more professional, and more accurate than casual chatbots; it is not an exaggeration to say they are experts in their respective fields.
Selecting the appropriate question-answering dialogue solution based on specific situations includes:
Classification-based question-answering systems;
Retrieval and ranking-based question-answering systems;
Sentence vector-based semantic retrieval systems.
Classification-based question-answering systems categorize each knowledge point, utilizing deep learning, machine learning, etc., achieving good results. However, they require a substantial amount of training data, and the cost of retraining when updating categories is high, making them more suitable for static knowledge bases with sufficient data.
Retrieval and ranking-based question-answering systems can effectively address the issues present in classification models by tracking knowledge point additions and deletions in real-time. However, they still face retrieval recall problems; if the keywords inputted by the user do not hit the knowledge base, the system cannot find a suitable answer.
A better solution is the sentence vector-based semantic retrieval. By using a sentence vector encoder, we can encode both knowledge base data and user questions, allowing for efficient searches across the entire dataset, thus resolving the traditional retrieval recall issue.
3. Task-Oriented Chatbots
Task-oriented chatbots provide information or services under specific conditions to meet users’ specific needs, such as checking traffic, checking phone bills, booking tickets, ordering food, and inquiries. Due to the complexity and diversity of user needs, task-oriented chatbots generally clarify user intentions through multi-turn dialogues. To understand how task-oriented chatbots operate, we need to introduce an important concept of task-oriented chatbots—Dialog Act.
The essence of task-oriented dialogue systems is to map both user inputs and system outputs to dialogue acts, using dialogue states to achieve understanding and representation of context. For instance, in a scenario where the chatbot assists in scheduling a cleaning service, the dialogue between the user and the chatbot corresponds to different actions. This approach can reduce the difficulty of dialogue in specific domains, allowing the chatbot to perform appropriate actions.
Additionally, the dialogue management module is one of the core modules of task-oriented chatbots and serves as the brain of the dialogue system. Traditional dialogue management methods include various architectures based on FSM, Frame, Agenda, etc., each suitable for different scenarios.
Dialogue management based on deep reinforcement learning directly maps dialogue context to system actions through neural networks, making it more flexible and trainable using reinforcement learning methods. However, it requires a large amount of real, high-quality labeled dialogue data for training, making it suitable only for scenarios with abundant data.
Applications of Chatbots:
Under human demands, chatbots are becoming increasingly intelligent, with some even predicting that in the next five to ten years, time-consuming and labor-intensive communication will be replaced by robots. The practical applications of chatbots are gradually proving this point.
Currently, chatbots are mainly applicable in three types of scenarios:
1) Natural dialogue is the only interaction method
In-car systems, smart speakers, wearable devices.
2) Replacing human agents with chatbots
Online customer service, intelligent IVR, smart outbound calls.
3) Enhancing efficiency and experience with chatbots
Intelligent marketing, intelligent recommendations, smart ordering.
We can assess the suitability of chatbot deployment in various fields based on online marketing conversion rates and online interaction demand levels. However, from a technical perspective, enabling machines to truly understand human language remains a challenging task. For building chatbots, consider the following suggestions:
Select suitable scenarios and define product boundaries;
Accumulate sufficient training data;
Continuously learn and optimize after launch;
Encourage user feedback;
Ensure the product reflects personalization.
Next, we will implement the chatbot based on the generative model using Seq2Seq+attention, with TensorFlow as the framework.

In the previous chapters discussing distributed deep learning practice, we covered the principles of Seq2Seq, so we won’t repeat them here. The Seq2Seq+attention approach is particularly suitable for scenarios involving question-answer pairs, such as chatbot dialogues and translating Chinese to English. Below, we will discuss an open-source project on GitHub called DeepQA, which is implemented based on the TensorFlow framework. Project address: https://github.com/Conchylicultor/DeepQA.
The original training data for the project is in English, while our actual scenarios involve processing Chinese dialogues. Therefore, we first need to find Chinese training corpora, perform Chinese word segmentation and data processing, and convert it into the required data format for the project. The second step is to train the model, which can be done using either a CPU or a GPU. Using a CPU has the drawback of being very slow, with a training set of over a hundred thousand dialogues taking about half a month to over a month. Using a GPU, however, is much faster, yielding results in just a few hours. The third step involves developing a web application to provide an HTTP service for the Q&A interface. We will discuss each step below.
1. Installation Process
Let’s take a look at the code directory:
chatbot contains chatbot.py, model.py, trainner.py and other core model source code; chatbot_website is based on Python’s django web framework for web interaction pages; data is the training data we need; main.py is the entry point for training the model. The DeepQA code directory is shown in Figure 8.9:
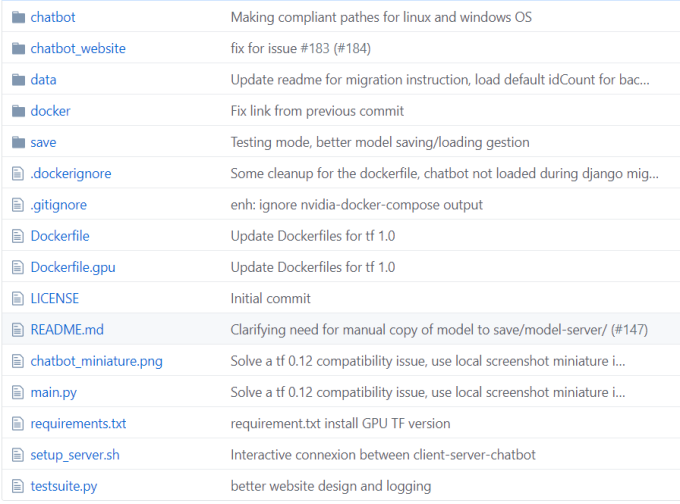
Figure 8.9 DeepQA Code Directory
The installation script code is as follows:
# Install dependencies
pip3 install nltk
python3 -m nltk.downloader punkt
# If an error occurs:
ImportError: No module named ‘_sqlite3’
# Install sqlite3
apt-get update
apt-get install sqlite3
pip3 install tqdm
# Install Python’s web framework Django
pip3 install django
# Check Django version
django-admin –version
pip3 install channels
# Install Python’s Redis client library
pip3 install asgi_redis
If you do not use the project’s built-in web framework, then Redis is not necessary; actual engineering requires a more complete mechanism.
2. Preparation and Processing of Chinese Dialogue Training Data
To prepare Chinese dialogue data, we first need to understand the format of the English training data. The project has provided English training corpora in two files:
One file contains question-answer dialogue data: /data/cornell/movie_conversations.txt
Here is a snippet of its content:
L232290 +++$+++ u1064 +++$+++ m69 +++$+++ WASHINGTON +++$+++ Don’t be ridiculous, of course that won’t happen.
L232289 +++$+++ u1059 +++$+++ m69 +++$+++ MARTHA +++$+++ I can not allow the fortune in slaves my first husband created and what our partnership has elevated, to be destroyed…
L232288 +++$+++ u1064 +++$+++ m69 +++$+++ WASHINGTON +++$+++ I’m very aware of that.
L232287 +++$+++ u1059 +++$+++ m69 +++$+++ MARTHA +++$+++ Well, a very real expectation is the British will hang you! They’ll burn Mount Vernon and they’ll hang you! Our marriage is a business just as surely as…
L232286 +++$+++ u1064 +++$+++ m69 +++$+++ WASHINGTON +++$+++ The eternal dream of the disenfranchised, my dear: a classless world. Not a very real expectation.
L232285 +++$+++ u1059 +++$+++ m69 +++$+++ MARTHA +++$+++ My God, what?
The other file, /data/cornell/movie_lines.txt, contains the dialogue IDs:
u1059 +++$+++ u1064 +++$+++ m69 +++$+++ [‘L232282’, ‘L232283’, ‘L232284’, ‘L232285’, ‘L232286’]
u1059 +++$+++ u1064 +++$+++ m69 +++$+++ [‘L232287’, ‘L232288’, ‘L232289’, ‘L232290’, ‘L232291’]
We need to prepare the original Chinese dialogue data in a format similar to this. Let’s look at the original Chinese dialogue data:
E
M 今天/吃/的/小/通/炖/蘑/菇
M 分/我/点/吧/,/喵/~
E
M 来/杯/茶
M 加/大/蒜/还/是/香/菜/?
E
M 大/葱
M 最/喜/欢/的/了
E
The approach we take to process the data is to remove slashes, then use Chinese word segmentation to segment the sentences, as this method allows the generated response sentences to appear smoother and more natural. The processing code can be written in Python, Java, or Scala, depending on your preference. Below is an example using Scala+Spark, as shown in Code 8.8:
[Code 8.8] ETLDeepQAJob.scala
def etlQA(inputPath: String,outputPath: String, mode: String) = { val sparkConf = new SparkConf().setAppName(“Is the battery chargedApp-Dialogue Robot Data Processing-Job”) sparkConf.setMaster(mode) //SparkContextinstance
val sc = new SparkContext(sparkConf)
//Load Chinese dialogue data file
val qaFileRDD = sc.textFile(inputPath)
//Initial value
var i = 888660
val linesList = ListBuffer[String]()
val conversationsList = ListBuffer[String]()
val testList = ListBuffer[String]()
val tempList = ListBuffer[String]()
qaFileRDD.collect().foreach(line=>{
if (line.startsWith(“E”)) {
if (tempList.size>1)
{
val lineIDList = ArrayBuffer[String]()
tempList.foreach(newLine=>{
val lineID = newLine.split(” “)(0)
lineIDList += “‘”+lineID+ “‘”
linesList += newLine
})
conversationsList += “u0 +++$+++ u2 +++$+++ m0 +++$+++ [“+lineIDList.mkString(“, “)+“]”
tempList.clear()
}
}
else {
if (line.length>2)
{
//Remove slashes/ characters, prepare for Chinese word segmentation
val formatLine = line.replace(“M”,“”).replace(” “,“”).replace(“/”,“”)
import scala.collection.JavaConversions._
//Use HanLP open-source segmentation tool
val termList = HanLP.segment(formatLine);
val list = ArrayBuffer[String]()
for(term <- termList)
{
list += term.word
}
//After Chinese word segmentation, join with spaces, treating segmented Chinese words like English words during training
val segmentLine = list.mkString(” “)
val newLine = if (tempList.size==0) {
testList += segmentLine
“L” + String.valueOf(i) + ” +++$+++ u2 +++$+++ m0 +++$+++ z +++$+++ ” + segmentLine
}
else “L”+ String.valueOf(i) + ” +++$+++ u2 +++$+++ m0 +++$+++ l +++$+++ ” + segmentLine
tempList += newLine
i = i + 1
}
}
})
sc.parallelize(linesList, 1).saveAsTextFile(outputPath+“linesList”)
sc.parallelize(conversationsList, 1).saveAsTextFile(outputPath+“conversationsList”)
sc.parallelize(testList, 1).saveAsTextFile(outputPath+“TestList”)
sc.stop()
}
conversationsList output result snippet:
L888666 +++$+++ u2 +++$+++ m0 +++$+++ z +++$+++ 欢迎 多 一些 这样 的 文章
L888667 +++$+++ u2 +++$+++ m0 +++$+++ l +++$+++ 谢谢 支持 !
Note: User z and l’s names can be arbitrary and have no actual meaning.
linesList output result snippet:
u0 +++$+++ u2 +++$+++ m0 +++$+++ [‘L888666’, ‘L888667’]
Note: The preceding u0 +++$+++ u2 +++$+++ m0 +++$+++ can remain unchanged; the key is the ID pairs of questions and answers in the brackets.
At this point, the data processing is complete. We have also generated a test set to evaluate the model’s performance on the test set. This testing can be subjective, manually testing by inputting a question and observing the differences in the response results compared to the test set answers. Of course, in this classification model, the responses do not necessarily have to match previous ones; training may yield better responses.
Next, we will replace the corresponding /data/cornell/movie_conversations.txt and /data/cornell/movie_lines.txt files, and then we can officially enter the training process.
3. Training the Model
After switching to our program directory, execute:
cd /home/hadoop/chongdianleme/DeepQA, then run:
python3 main.py; to start training. If we want to control the use of the GPU for training, we can specify which GPU to use by prefixing with:export CUDA_VISIBLE_DEVICES=0; main.py The Python file code is as follows:
from chatbot import chatbot
if __name__ == “__main__”:
chatbot = chatbot.Chatbot()
chatbot.main()
The core code is in chatbot, but since it is too long, I won’t paste it here. You can download it to view. The training model takes a long time; training on a CPU for over a hundred thousand dialogues can take half a month to over a month, while training on a GPU takes only a few minutes to a few hours. It is best to run it in the background without waiting for results. The background execution script code is as follows:
vim Create a filevim main.sh, enter the script
export CUDA_VISIBLE_DEVICES=0;
python3 main.py;
# Press:wq to save
# Grant executable permissions tomain.sh
sudo chmod 755 main.sh
# Next, create a shell script to run in the background:
vim nohupmain.sh
# Enter:
nohup /home/hadoop/chongdianleme/main.sh >tfqa.log 2>&1 &
# Then:wq to save
# Similarly, grant executable permissions tonohupmain.sh
sudo chmod 755 nohupmain.sh
# Finally, run the scriptsh nohupmain.sh to enjoy the results. Since the running time is long, there may be errors during the process, so we can start by observing the logs using the command:tail -f tfqa.log to view the latest logs in real-time.
Below is the log for CPU training over 30 iterations. To achieve good results, about 30 iterations are generally sufficient; too few iterations will yield poor results, with responses being somewhat incoherent and irrelevant.
Below is the log of the CPU training process:
2019-10-09 19:28:36.959843: W tensorflow/core/platform/cpu_feature_guard.cc:45] The TensorFlow library wasn’t compiled to use SSE4.1 instructions, but these are available on your machine and could speed up CPU computations.
2019-10-09 19:28:36.959910: W tensorflow/core/platform/cpu_feature_guard.cc:45] The TensorFlow library wasn’t compiled to use SSE4.2 instructions, but these are available on your machine and could speed up CPU computations.
2019-10-09 19:28:36.959922: W tensorflow/core/platform/cpu_feature_guard.cc:45] The TensorFlow library wasn’t compiled to use AVX instructions, but these are available on your machine and could speed up CPU computations.
2019-10-09 19:28:36.959982: W tensorflow/core/platform/cpu_feature_guard.cc:45] The TensorFlow library wasn’t compiled to use AVX2 instructions, but these are available on your machine and could speed up CPU computations.
2019-10-09 19:28:36.960028: W tensorflow/core/platform/cpu_feature_guard.cc:45] The TensorFlow library wasn’t compiled to use FMA instructions, but these are available on your machine and could speed up CPU computations.
Training: 0%| | 0/624 [00:00<?, ?it/s]
Training: 0%| | 1/624 [00:03<36:33, 3.52s/it]
Training: 0%| | 2/624 [00:06<33:26, 3.23s/it]
Training: 0%| | 3/624 [00:08<31:13, 3.02s/it]
Training: 1%| | 4/624 [00:11<29:36, 2.87s/it]
Training: 1%| | 5/624 [00:13<28:29, 2.76s/it]
Training: 1%| | 6/624 [00:16<27:40, 2.69s/it]
… (intermediate steps omitted)
Training: 100%|██████████| 624/624 [26:17<00:00, 2.29s/it]
—– Step 11600 — Loss 2.62 — Perplexity 13.76
—– Step 11700 — Loss 2.88 — Perplexity 17.79
—– Step 11800 — Loss 2.78 — Perplexity 16.06
Epoch finished in 0:26:16.157353
—– Epoch 20/30 ; (lr=0.002) —–
Shuffling the dataset…
—– Step 11900 — Loss 2.64 — Perplexity 13.97
—– Step 12000 — Loss 2.71 — Perplexity 15.01
—– Step 12100 — Loss 2.67 — Perplexity 14.42
—– Step 12200 — Loss 2.73 — Perplexity 15.32
—– Step 12300 — Loss 2.81 — Perplexity 16.64
—– Step 12400 — Loss 2.73 — Perplexity 15.36
Epoch finished in 0:26:17.595209
—– Epoch 30/30 ; (lr=0.002) —–
Shuffling the dataset…
—– Step 18100 — Loss 2.14 — Perplexity 8.47
—– Step 18200 — Loss 2.24 — Perplexity 9.44
—– Step 18300 — Loss 2.29 — Perplexity 9.84
—– Step 18400 — Loss 2.35 — Perplexity 10.49
—– Step 18500 — Loss 2.33 — Perplexity 10.25
—– Step 18600 — Loss 2.30 — Perplexity 9.93
—– Step 18700 — Loss 2.31 — Perplexity 10.07
Epoch finished in 0:26:17.225496
Checkpoint reached: saving model (don’t stop the run)…
Model saved.
The End! Thanks for using this program
Training on GPU is similar to that on CPU, with only performance differences.
2019-10-09 01:36:22.502878: I tensorflow/core/platform/cpu_feature_guard.cc:137] Your CPU supports instructions that this TensorFlow binary was not compiled to use: SSE4.1 SSE4.2 AVX AVX2 FMA
2019-10-09 01:36:28.059786: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1030] Found device 0 with properties:
name: Tesla K80 major: 3 minor: 7 memoryClockRate(GHz): 0.8235
pciBusID: 0000:06:00.0
totalMemory: 11.17GiB freeMemory: 11.11GiB
2019-10-09 01:36:22.059809: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1120] Creating TensorFlow device (/device:GPU:0) -> (device: 0, name: Tesla K80, pci bus id: 0000:06:00.0, compute capability: 3.7)
2019-10-09 01:36:22.062862: I tensorflow/core/common_runtime/direct_session.cc:299] Device mapping:
/job:localhost/replica:0/task:0/device:GPU:0 -> device: 0, name: Tesla K80, pci bus id: 0000:06:00.0, compute capability: 3.7
… (further details omitted)
After training, a model file directory will be generated, as shown below, located in the save/model directory. The model directory is shown in Figure 8.10:

Figure 8.10 DeepQA Code Directory
Once the model is trained, we do not need to retrain it every time. Instead, we can load the model file into memory to create an HTTP web service interface. Below, we will look at the code for the web engineering HTTP protocol interface.
4. Web Engineering HTTP Protocol Interface
We will use Python’s Flask lightweight web framework for this. Based on the model directory, we can load the model file during the web project initialization, allowing for real-time predictions in the interface. The project code is as follows:
[Code 8.9] chatbot_predict_web_chongdianleme.py
import sysimport loggingfrom flask import Flaskfrom flask import requestfrom chatbot import chatbot#Your program directory
chatbotPath = “/home/hadoop/chongdianleme/DeepQA”
sys.path.append(chatbotPath)
#Model loading initialization
chatbot = chatbot.Chatbot()
chatbot.main([‘–modelTag’, ‘server’, ‘–test’, ‘daemon’, ‘–rootDir’, chatbotPath])
app = Flask(__name__)
@app.route(‘/predict’, methods=[‘GET’, ‘POST’])
def prediction():
#User input
sentence = request.values.get(“sentence”)
#Log user access information and process it
device = request.values.get(“device”)
userid = request.values.get(“userid”)
#Real-time prediction of the question to be answered,sentenceneeds to be a string of Chinese words segmented and joined by spaces, ensuring consistency with the segmentation tool and algorithm used during training
answer = chatbot.daemonPredict(sentence)
#Since Chinese words are treated as words, the returned sentence needs to remove spaces and concatenate into a sentence
answer = answer.replace(” “,“”)
return answer
if __name__ == ‘__main__’:
#Specify IP address and port number
app.run(host=‘172.17.100.216’, port=8820)
Next, we will look at how to deploy and start the Flask-based dialogue web service. The script code is as follows:
# Create shell script file vim qaService.sh
# Input:
python3 chatbot_predict_web_chongdianleme.py
# Then :wq to save
# Grant executable permissions to qaService.sh
sudo chmod 755 qaService.sh
# Then create a shell script to run in the background:
vim nohupqaService.sh
# Input:
nohup /home/hadoop/chongdianleme/qaService.sh > tfqaweb.log 2>&1 &
# Then :wq to save
# Similarly, grant executable permissions to nohupqaService.sh
sudo chmod 755 nohupqaService.sh
# Finally, run the script sh nohupqaService.sh to start the Flask-based dialogue web service interface.
Once started, you can enter the URL in the browser to access our service. This HTTP interface supports both GET and POST access, allowing direct access through the browser.
http://172.17.100.216:8820/predict?sentence=欢迎 多 一些 这样 的 文章
This is an interface service that other systems or PHP, Java web sites can call. It is important to note that the sentence needs to be a string of Chinese words segmented and joined by spaces, ensuring consistency with the word segmentation tool and algorithm used during training.


In addition to chatbots implemented based on TensorFlow ☞https://ke.qq.com/course/482274?flowToken=1028972, other deep learning frameworks also have good open-source implementations, such as MXNet. Please stay tuned for more content from the Charging App, courses, WeChat groups, and the new book “Distributed Machine Learning Practice (Artificial Intelligence Science and Technology Series)”.
“Distributed Machine Learning Practice” This book corresponds to the Tsinghua University Press JD self-operated link:
https://item.jd.com/12743009.html
Python Programming Zero Basics Quick Start Course
https://ke.qq.com/course/package/29782?flowToken=1028733