

Paper Link:
https://aclanthology.org/2023.findings-acl.426.pdf
https://github.com/bazingagin/npc_gzip
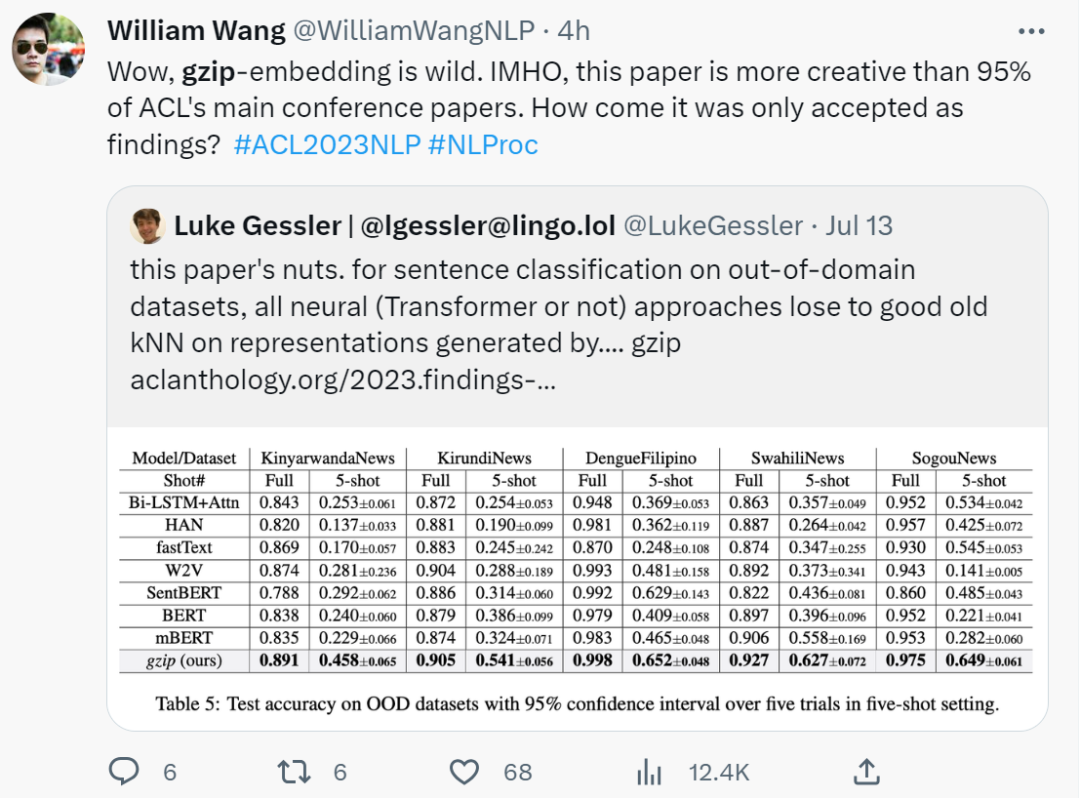
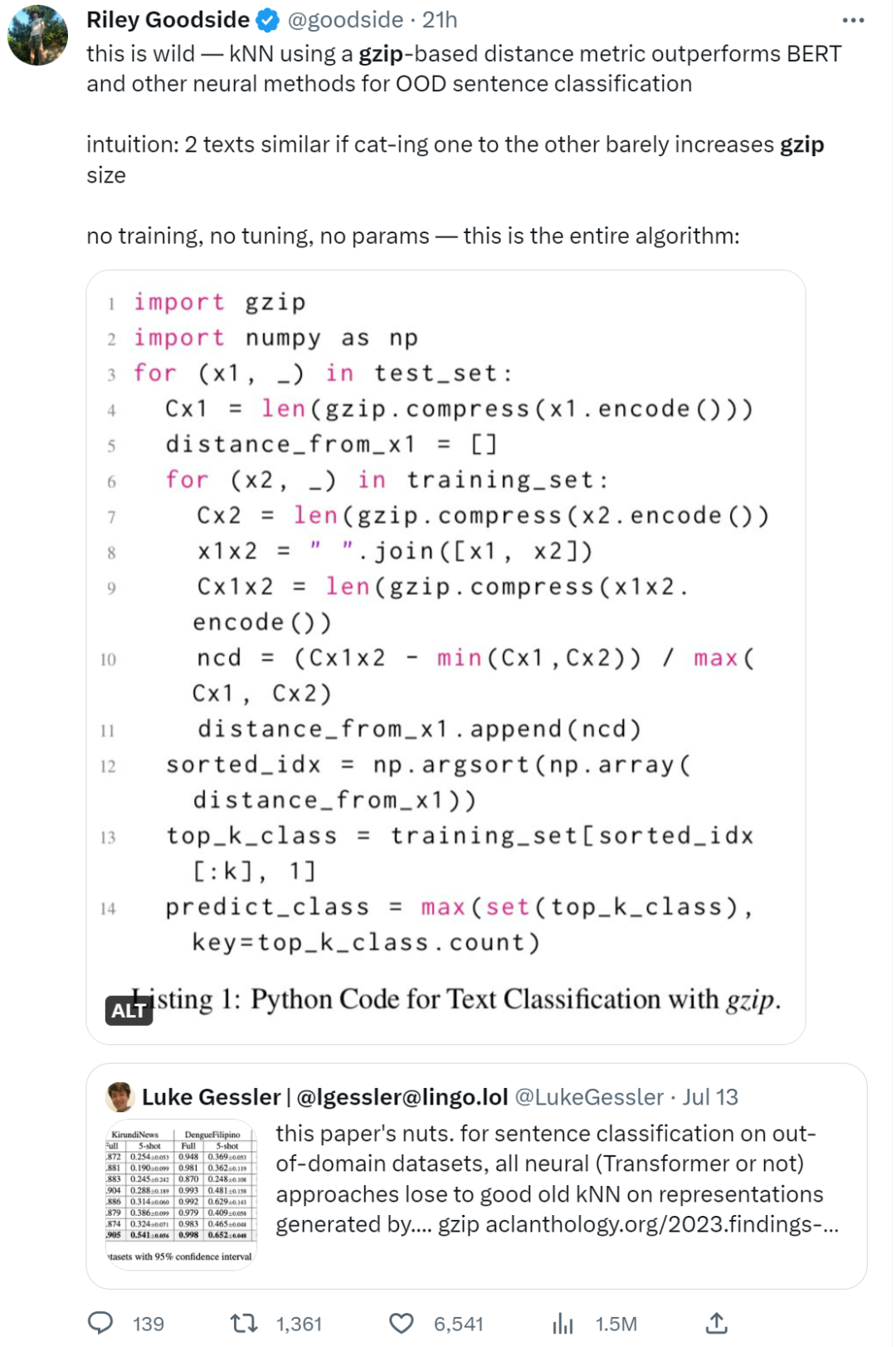

Method Overview

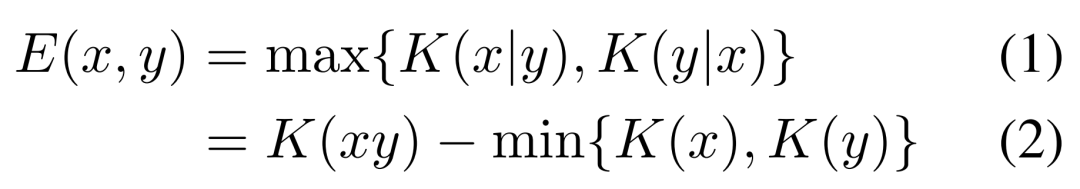
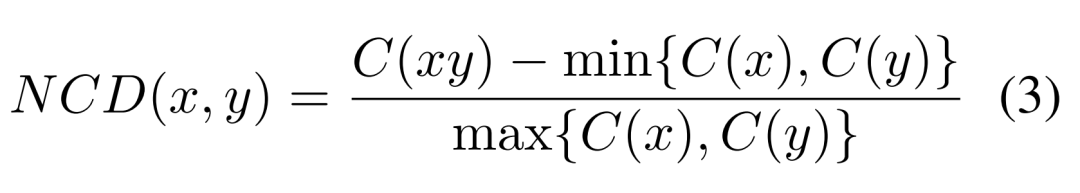


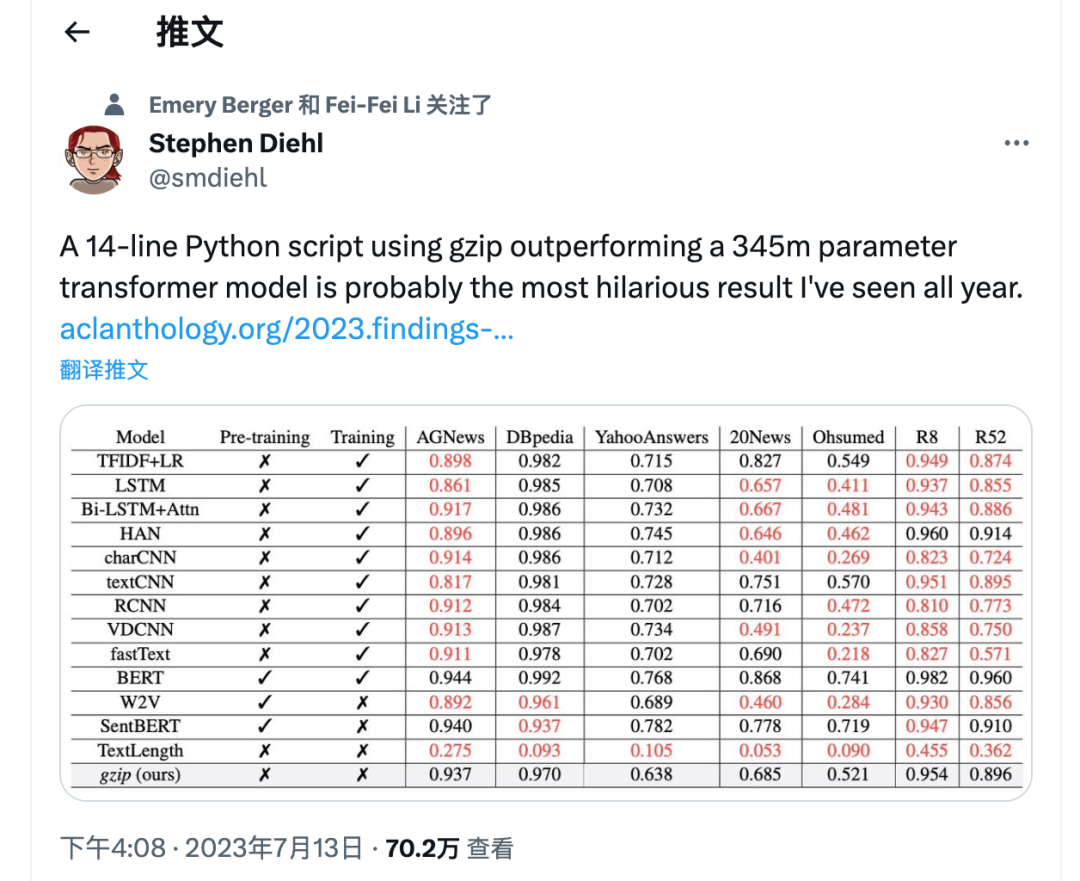
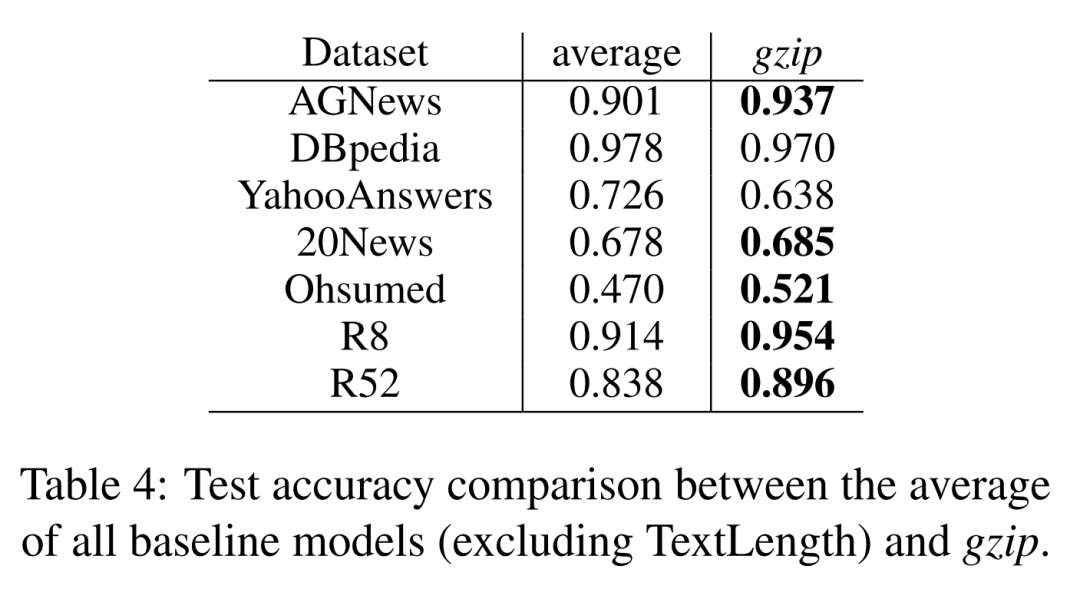
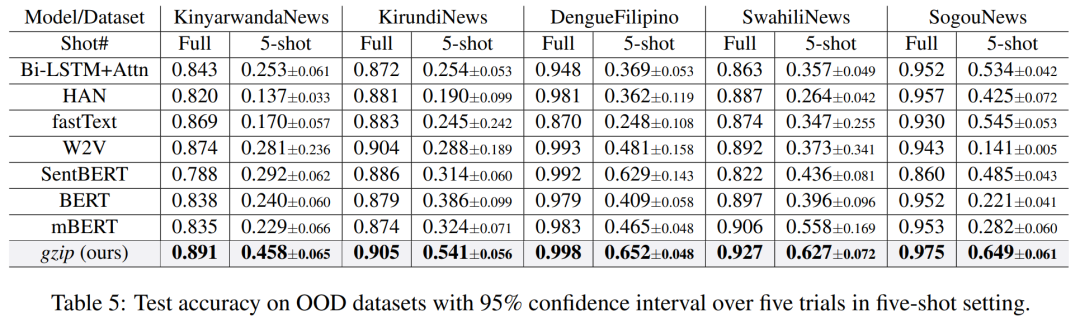
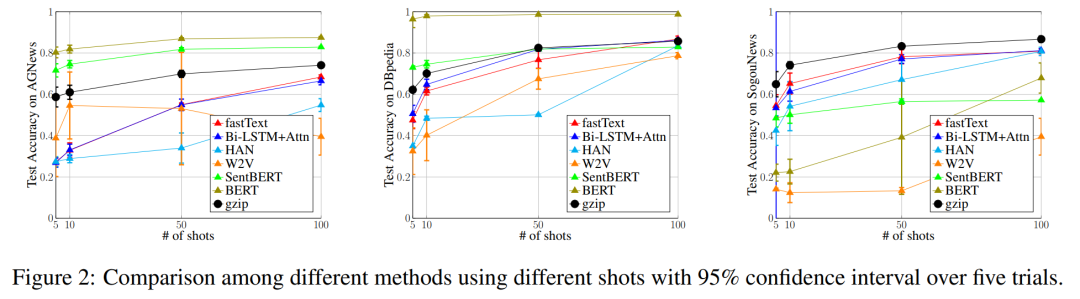
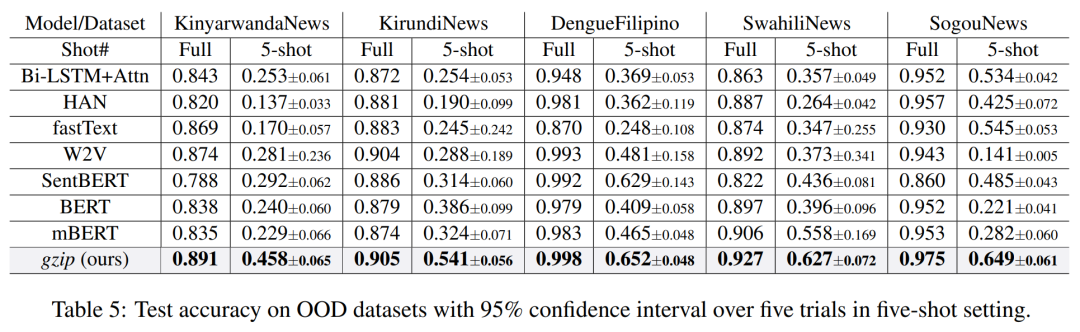
Experimental Results
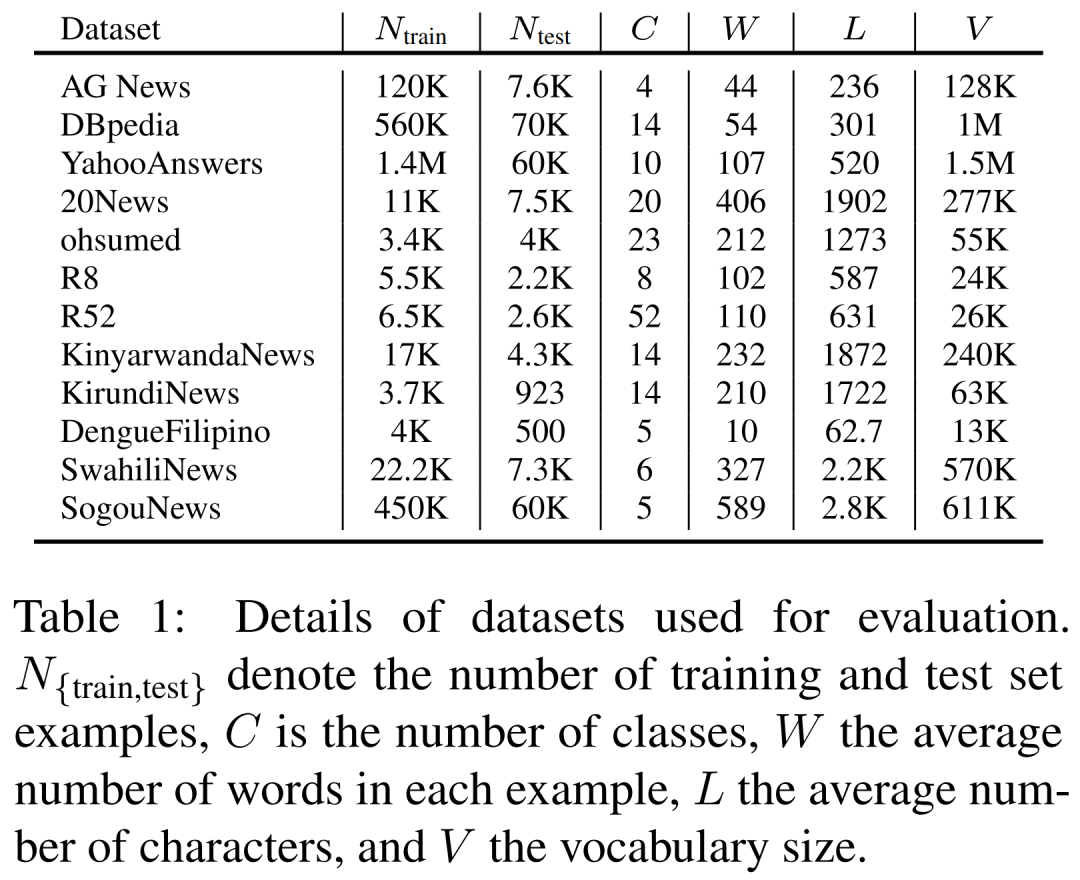
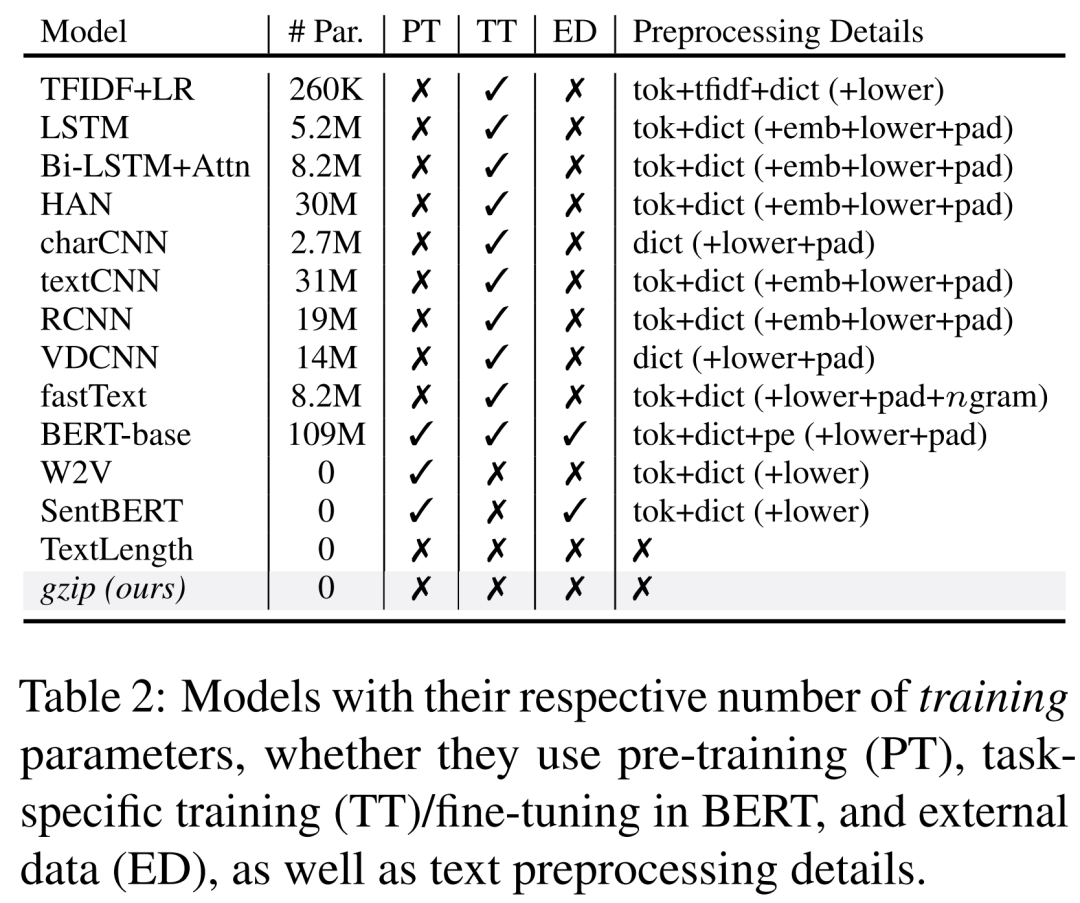
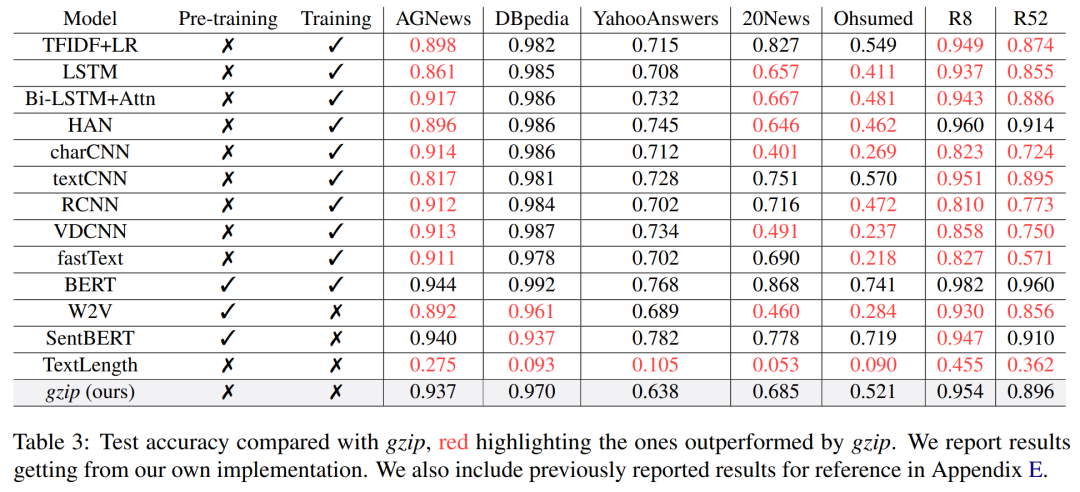
More Reading




#Submission Channel#
Let Your Words Be Seen by More People
How can more quality content reach the reader group through a shorter path, reducing the cost for readers to find quality content? The answer is: people you don’t know.
There are always some people you don’t know who know what you want to know. PaperWeekly may serve as a bridge, facilitating the collision of different backgrounds and academic inspirations, sparking more possibilities.
PaperWeekly encourages university labs or individuals to share various quality content on our platform, which can be latest paper interpretations, academic hotspot analyses, research insights, or competition experience explanations, etc. Our only goal is to make knowledge flow.
📝 Basic Requirements for Submissions:
• The article must indeed be a personal original work that has not been published in public channels. If it has been published or is pending publication on other platforms, please clearly indicate.
• Manuscripts are suggested to be written in markdown format, with accompanying images sent as attachments, requiring clear images without copyright issues.
• PaperWeekly respects the original author’s right to attribution and will provide competitive remuneration for each accepted original first publication, specifically calculated based on article view counts and quality.
📬 Submission Channel:
• Submission Email:[email protected]
• Please include immediate contact information (WeChat) in your submission so we can contact the author as soon as the manuscript is selected.
• You can also directly add the editor’s WeChat (pwbot02) for quick submission, with a note: name – submission.

△ Long press to add PaperWeekly editor
🔍
Now, you can also find us on Zhihu
Search for “PaperWeekly” on Zhihu’s homepage
Click “Follow” to subscribe to our column
