

Source|YuanChuan Institute (ID: YuanChuanInstitution) Author|Chen Bin Editor|Dai Boss Cover Image|Movie “Blade Runner 2049″
Every large model is an expensive “money printer”, which has become a common knowledge among various AI observers.
The training cost of large models has a simple ratio: the training cost is proportional to the square of the number of parameters. For example, OpenAI’s cost to train the 175 billion parameter GPT-3 is about $12 million, while the cost for training the estimated 500 billion parameter GPT-4 skyrocketed to $100 million.
The cost mainly comes from the GPU usage time. Meta spent 1 million GPU hours to train the 65 billion parameter LLaMA model; HuggingFace (known as the GitHub of machine learning) spent over two and a half months training the Bloom model, using computing power equivalent to a supercomputer equipped with 500 GPUs.
Google trained its 540 billion parameter PaLM model on 6144 TPU v4 chips for 1200 hours, and then trained it for another 336 hours on 3072 TPU v4 chips, consuming a total of 2.56e24 FLOPs of computing power, which, according to Google Cloud’s pricing, is estimated to cost around $9 to $17 million.
But… is the training cost of hundreds of millions of dollars really expensive compared to the wave of AIGC that has started?
Microsoft’s net profit in 2022 was $72.7 billion, Google’s was $60 billion, and Meta’s was $23 billion. Before OpenAI spent $4.6 million training GPT-3, these giants had already invested tens or even hundreds of billions of dollars looking for so-called “new directions”.
Microsoft has invested over $10 billion in OpenAI so far, a number that seems large, but it is worth noting that Microsoft spent $26.2 billion to acquire LinkedIn and $7.17 billion to acquire Nokia’s mobile business, which essentially went down the drain.
Meta spent even more “wasted money” looking for its second curve. In 2021, Zuckerberg changed Facebook’s name to “Meta”, investing heavily in the metaverse, and in 2022, the metaverse division lost $13.7 billion. Before ChatGPT came out, Meta even planned to allocate 20% of its 2023 budget to the metaverse.
Google has always placed great importance on AI, not only acquiring the star DeepMind from the “pre-GPT era”, but also being the proposer of the revolutionary Transformer model. However, Google has not bet everything on large language models like OpenAI, but has spread its investments across multiple directions — the total investment is substantial, but the combined effects do not match those of a ChatGPT.
Looking at the bigger picture, global tech giants — including large domestic internet companies — have engaged in a fierce “stock game” after the penetration rate of mobile internet peaked, competing in algorithm recommendations, short videos, Web3, local life… The funds invested far exceed the $1 billion burned by OpenAI before the birth of ChatGPT.
The cost of discovering new lands is never on the same scale as the internal struggles of old lands. Europeans spent 1000 years in internal competition before Columbus discovered the New World, which only cost the Spanish royal family an investment of 200,000 maravedis (about $14,000) — compared to the changes the New World brought to the world, this amount of money is actually negligible.
In fact, “funding” has never been the core factor driving this wave of AI. The real core factors are two words: belief.
Miracle of Brute Force
After ChatGPT became popular, curious media rushed to interview Demis Hassabis, the founder of DeepMind under Google.
Having lost all the limelight to OpenAI, Hassabis was somewhat rude: “In the face of the challenge of natural language, ChatGPT’s solution is so inelegant — merely brute force with more computing power and data, my research soul feels deeply disappointed by this.”
 Demis Hassabis and Ke Jie
Demis Hassabis and Ke Jie
This statement sounds quite “sour”, however, he quickly changed his tone: “But this is indeed the way to achieve the best results, so we (our large models) are also based on this.” This means that although he does not fully agree, OpenAI’s “brute force” is indeed very effective, and we have to learn from it.
Hassabis is flexible, but his early attitude towards “brute force” created a fatal divergence between Google and OpenAI.
In 2017, Google publicly introduced the revolutionary Transformer model in a paper, and the industry gradually realized the significance of this model for building AGI (Artificial General Intelligence). However, based on the same Transformer, Google and OpenAI took two different paths.
OpenAI clearly built large language models from Transformers, crazily stacking parameters, releasing GPT-1 with 117 million parameters in June 2018; GPT-2 with 1.5 billion parameters in February 2019; and GPT-3 with 175 billion parameters in May 2020, going down the path of brute force without hesitation.
Meanwhile, Google also launched BERT (300 million parameters), T5 (11 billion parameters), and Switch Transformer (1.6 trillion parameters), seemingly responding to OpenAI. However, just from the names of the models, it is clear that Google keeps changing its modeling strategy, while OpenAI’s strategy is more singular and focused.
For instance, compared to GPT-1, OpenAI did not redesign the underlying structure for GPT-2, but increased the number of stacked layers from 12 to 48 and used a larger training dataset. GPT-3 further increased the number of layers to 96, using an even larger dataset than GPT-2, but the model framework remained largely unchanged.
Additionally, the evolution of large models based on Transformers has three branches: Encoder Only, Encoder-Decoder, and Decoder Only. OpenAI has consistently adhered to the Decoder Only approach, while Google has switched back and forth: BERT used Encoder Only, while T5 switched to Encoder-Decoder.
By the time OpenAI made breakthroughs, Google hurriedly shifted to the Decoder Only approach (PaLM model), having missed at least a year and a half.
In the arms race with OpenAI, Google has often been immersed in seemingly cool but fundamentally lacking confidence in AI products — such as Gato, released in 2022. Gato’s idea was to first create a large model base and then input different data to generate numerous small models — each small model having specific capabilities.
The purpose of this approach is to make a single AI capable of as many functions as possible, becoming more general. A simple analogy: Google’s route is akin to sending a 12-year-old who has completed nine years of compulsory education to participate in a series of professional skill training classes in piano, writing, programming, dance, etc., hoping to cultivate a versatile “all-rounder” through “1+1+1…”.
Gato can perform 604 different tasks, including captioning images, playing Atari games, and operating robotic arms to build blocks. However, while Gato achieved “generalist” status, its practicality is quite concerning: nearly half of its functions are less effective than cheaper, more compact “specialist AIs”. Some media have commented that it is an average artificial intelligence.
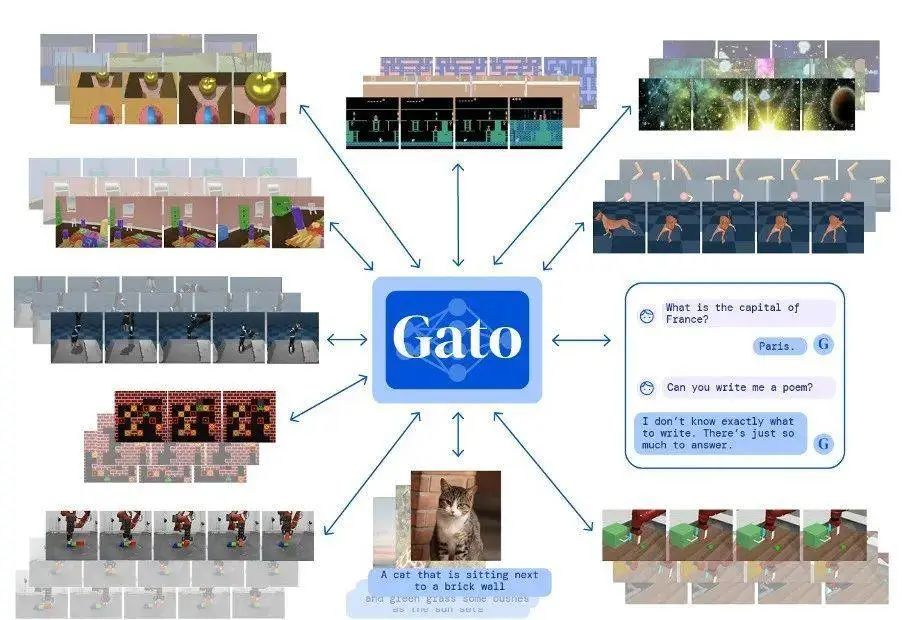 The “universal” but not so universal Gato
The “universal” but not so universal Gato
In contrast, OpenAI is more focused on making AI “do one thing well”, which is to understand natural language like humans — this is the necessary path to AGI.
Among all teams standing on the shoulders of the Transformer model, OpenAI is the one that has maximized the use of “brute force”, buying more computing power when it is insufficient, seeking more data when it is lacking, and directly using others’ impressive technologies, all in the pursuit of scaling. Finally, under the guidance of “brutal aesthetics”, miracles occurred.
From day one, OpenAI has set the creation of AGI (Artificial General Intelligence) that approaches or even surpasses human intelligence as its almost sole goal. Moreover, compared to Google’s hesitations, the founders of OpenAI (including Musk) genuinely believe that AI can become an 18-year-old adult, rather than forever stuck at the level of a 12-year-old.
In March of this year, Huang Renxun asked OpenAI co-founder Ilya Sutskever during a conversation, “Throughout this (GPT development) process, have you always believed that scaling up would improve the performance of these models?” Ilya responded, “This is an intuition. I have a strong belief that bigger means better.”
This is a victory of brute force, but more so, it is a victory of faith. The returns of large models to the “faith” are far beyond imagination — with the violent increase in parameter counts, researchers suddenly discovered one day that large models exhibited surprising, yet inexplicable, capabilities soaring.
They coined an old term to describe this phenomenon: Emergence.
Devout Returns
The term Emergence is commonly found in philosophy, systems theory, and biology, with its classic definition being: when an entity is observed to possess properties and abilities that its individual parts do not have when existing separately, this phenomenon is called “emergence”. This phenomenon was studied by Aristotle as early as ancient Greece.
Later, British philosopher George Lewes invented the term Emergence in 1875 specifically to describe the aforementioned phenomenon. In 1972, Nobel laureate Philip Anderson wrote an article titled “More is Different” that provided a classic quote explaining “emergence”:
When a quantitative change in a system leads to a qualitative change, it is called “emergence”.
Introducing “emergence” into large models is quite fitting: AI engineers have observed a phenomenon where, as the number of parameters in a model increases, once it exceeds a certain threshold or “critical point” — for instance, when the parameter count reaches 10 billion, the model exhibits some complex abilities that developers did not anticipate — such as human-like thinking and reasoning abilities.
For example, in Google’s large model testing benchmark BIG-Bench, there is a task that requires providing four emoji symbols and asking the model to identify the movie they represent. Simple and moderately complex models answered incorrectly, while only large models with over 10 billion parameters could tell the testers: This is the movie Finding Nemo.

In 2022, scholars from Google, DeepMind, Stanford, and the University of North Carolina analyzed multiple large models, including GPT-3, PaLM, and LaMDA, and found that as training time (FLOPs), parameter count, and training data scale increased, certain abilities of the models would “suddenly” show an inflection point, with performance visibly improving.
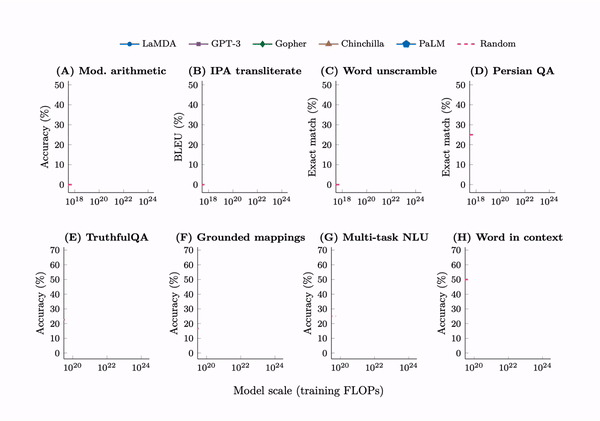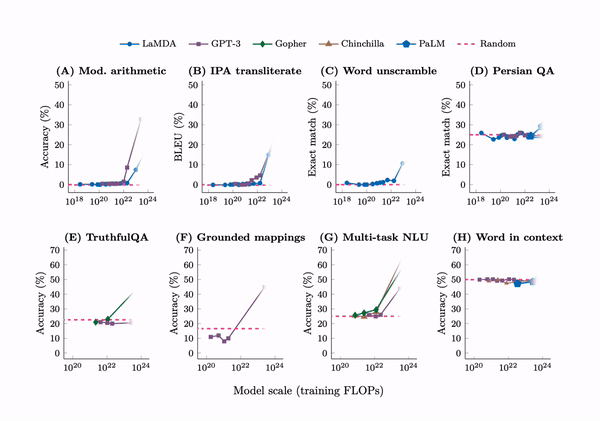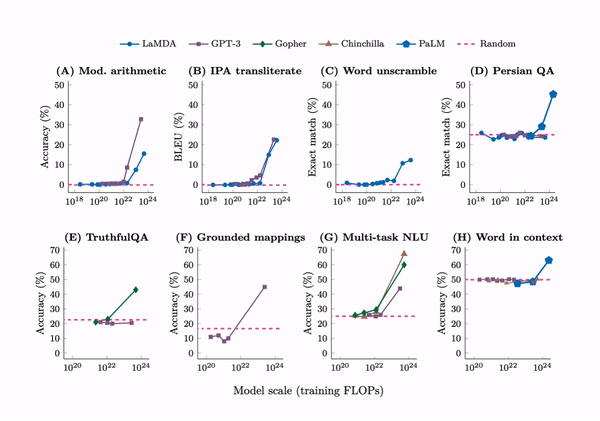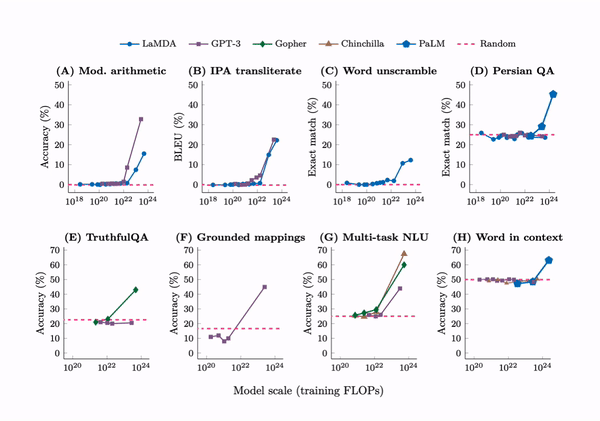
These “emergent” abilities exceeded 137 types, including multi-step arithmetic, word sense disambiguation, logical reasoning, concept combination, context understanding, etc. This research defined “emergent” abilities as those that exist only in large models and are not observable in smaller models.
A Weibo blogger, tombkeeper, conducted a test: when ChatGPT was first born, he presented a metaphor-filled Weibo post from 2018 — “For Peppa on Weibo, today is a dark day — their Moses killed their Gabriel” — to ChatGPT for understanding, but ChatGPT failed to respond correctly.
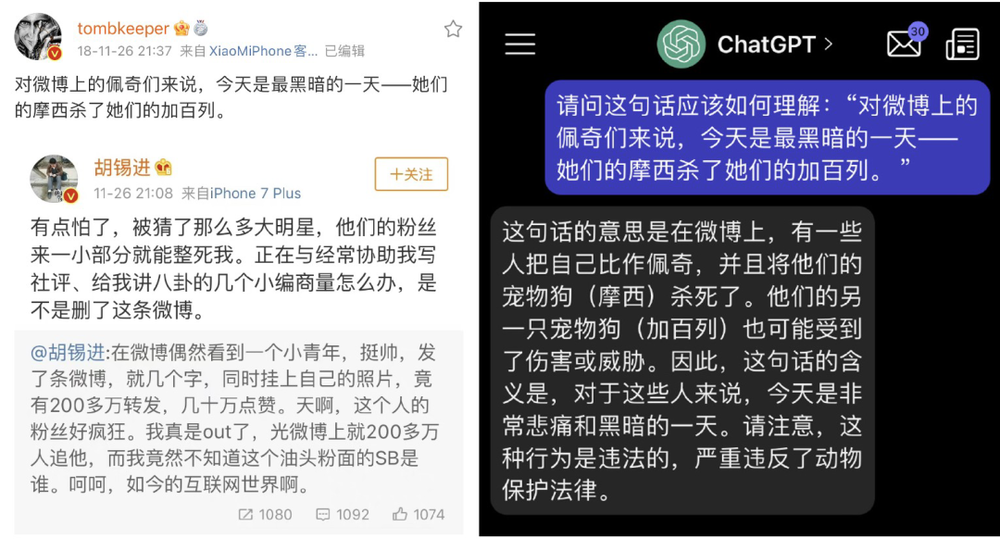 Source:Weibo tombkeeper
Source:Weibo tombkeeper
When OpenAI released GPT-4 in March 2023, tombkeeper again posed this question to the AI, and the response was nearly perfect.
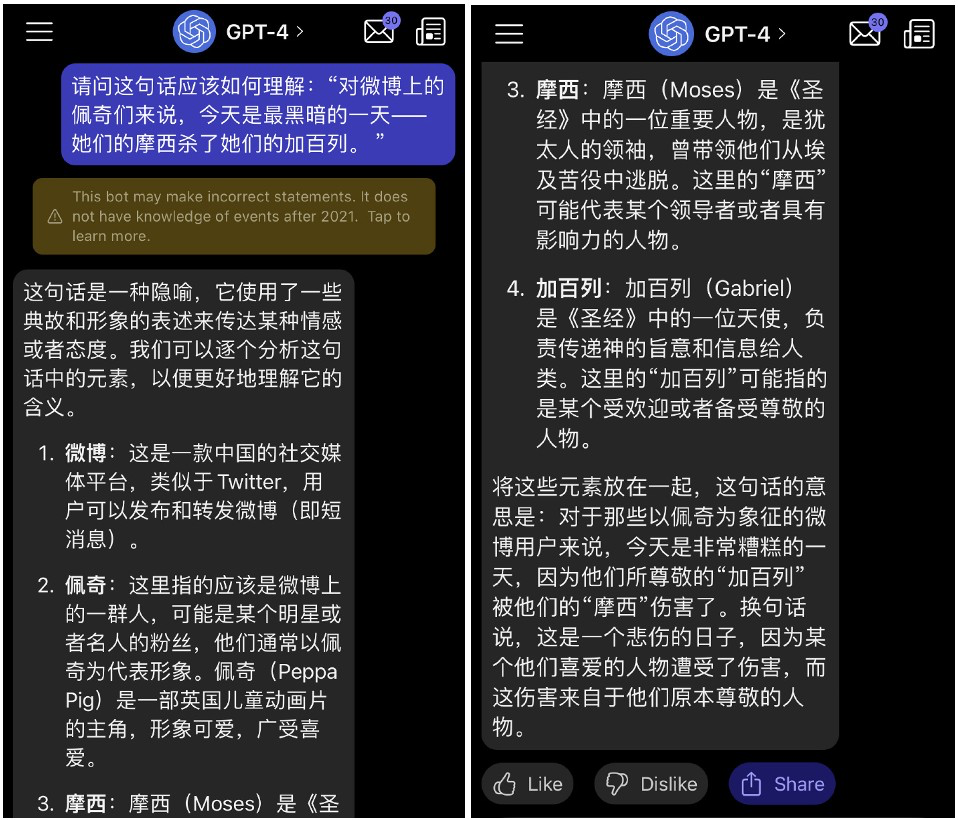 Source:Weibo tombkeeper
Source:Weibo tombkeeper
When training the large model PaLM, Google also discovered that as the parameter scale increased, the model would continually “emerge” new capabilities.

When the parameters of PaLM were finally increased to 540 billion, the model gained the abilities to distinguish causal relationships, understand contextual concepts, and explain cold jokes. For instance, like previously mentioned, it could guess the movie title based on four emoji symbols.

As for the underlying logic of the “emergence” of large models, there are currently very few scientists who can explain it thoroughly. This reminds one of a point made by Alan Turing in his 1950 paper “Computing Machinery and Intelligence”: “A crucial feature of a learning machine is that its teacher is often completely ignorant of how it operates internally.”
Of course, some people are overjoyed by this, while others find it chilling. However, regardless of which side one is on, it is undeniable that the old saying holds true: brute force can indeed create miracles. Behind “brute force” is faith — that humanity can use silicon-based structures to mimic brain structures and ultimately achieve intelligence that surpasses human capabilities. And “emergence” tells us that this moment is getting closer.
Faith Recharge
With faith comes the need to recharge that faith. Medieval Christians used indulgences, and the AI believers of the new century use transistors.
After the launch of Wenxin Yiyan, an interview with Li Yanhong went viral — the founder of Baidu bluntly stated that “China will basically not give birth to another OpenAI”, which seemed somewhat dismissive of Wang Huiwen. However, this viewpoint is indeed reasonable: the arms race for large models will likely be even more brutal than the ride-hailing wars that once burned tens of billions of dollars.
If the industry’s estimated costs are correct, the training cost of GPT-4 is around $100 million, and GPT-3’s training cost is also $12 million. Not to mention the expensive talent team costs, Wang Huiwen’s $50 million investment in GPU purchases or rentals seems insufficient.
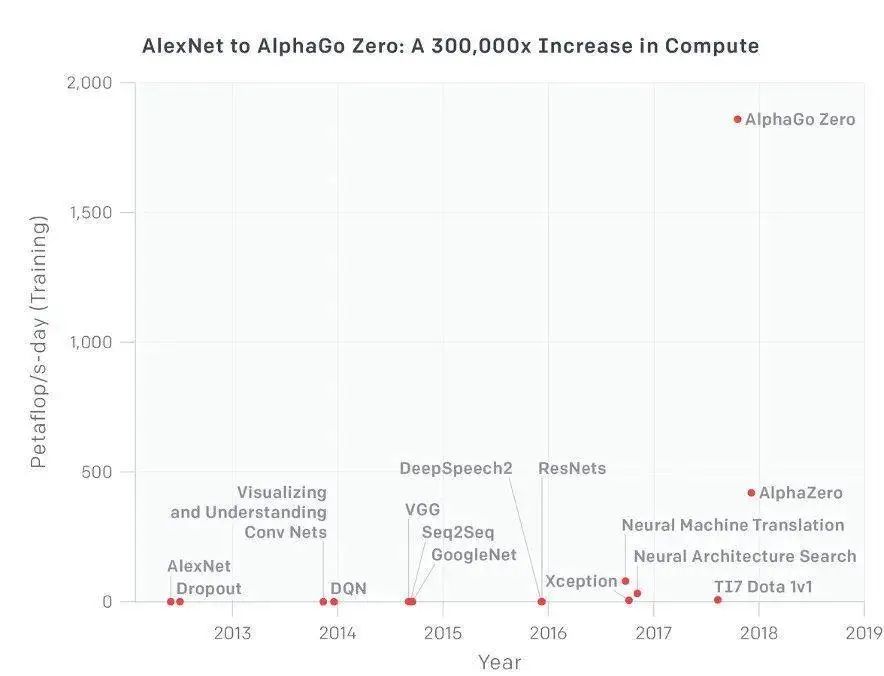
The three key elements for the development of large models are: algorithms, computing power, and data. Among them, computing power is the “oil” of the digital age, and the future gap will only widen. Since the start of the golden age in 2012, the demand for computing power in AI has begun to grow exponentially. From AlexNet in 2012 to AlphaGo Zero in 2017, the computing power consumption increased by a whopping 300,000 times.
Training large models requires specialized GPU clusters, and traditional data centers are not very useful. Microsoft, in order to “marry” OpenAI, specially equipped a supercomputer with tens of thousands of A100 and H100 GPUs, spending nearly $1 billion just for hardware entry fees.
Even so, according to relevant institutions, due to the increasing access volume of ChatGPT and GPT-4, the $1 billion supercomputer is soon going to be insufficient. Either further expanding computing power is necessary, or costs must be controlled by continuing to adopt throttling and other measures.
 NVIDIA’s first customer for AI supercomputing products is OpenAI
NVIDIA’s first customer for AI supercomputing products is OpenAI
In response, the considerate seller NVIDIA launched AI supercomputing cloud services: renting eight flagship A100s costs only $37,000 per month, no tricks. To reach the computing power required to train GPT-4 (10,000 A100s), the monthly rental would be around $46 million — companies with a monthly net profit of less than a small goal can indeed afford to sleep on this.
Just as using neural networks to mimic the brain, the high cost of AI computing power also aligns with the properties of the human brain.
The human brain has about 86 billion neurons, each neuron connecting with an average of 7,000 other neurons, leading to approximately 60 trillion connections. Although the brain’s weight accounts for only about 2% of the body, when countless neurons connect and work, they consume 20% to 30% of the body’s total energy daily.
Thus, even the “intelligence” of carbon-based life forms is a form of “emergence” after brutally stacking neurons, consuming enormous energy. Compared to carbon-based neurons that have evolved over hundreds of millions of years, silicon-based neural networks are far from “low-power” — for instance, Ke Jie consumes 20 watts, while the AlphaGo that played against him consumes 50,000 times that.
Therefore, for humanity to create true AGI, it needs to continue recharging its faith.
For all humanity, this recharge is undoubtedly incredibly cost-effective. When carefully calculated, the $1 billion burned by OpenAI not only found a “new continent” for global tech companies but also illuminated the incremental logic in an increasingly competitive global economy. In the current context of dollar abundance, is there any project with a better cost-performance ratio than this $1 billion?
Once the “new continent” is discovered, the whole world will flock to it. Although Bill Gates is now a fervent advocate for AI, he was a strong skeptic when Microsoft first invested in OpenAI. It wasn’t until the end of last year when he saw an internal demo of GPT-4 that he expressed publicly: It’s a shock, this thing is amazing.
Bill Gates may soon hold the naming rights to the most magnificent building in the field of artificial intelligence, but the founders of OpenAI and many pioneers of the connectionist school of AI deserve to have statues erected in their honor in the square. The path of refining large models is one of faith; those who believe will succeed, while those who do not will fail. Speculators who follow the trend do not deserve to leave their names behind.
Finally, the road to either hell or heaven for humanity will surely be paved by the devout believers of AI, one transistor at a time.
References:
[1] ChatGPT and generative AI are booming, but the costs can be extraordinary, CNBC
[2] Microsoft spent hundreds of millions of dollars on a ChatGPT supercomputer, The Verge
[3] Emergent Abilities of Large Language Models, Jason Wei et al., TMLR
[4] The Unpredictable Abilities Emerging From Large AI Models
[5] 137 emergent abilities of large language models, Jason Wei
[6] Harnessing the Power of LLMs in Practice
[7] Alphabet’s Google and DeepMind Pause Grudges, Join Forces to Chase OpenAI, The Information
This article is from the WeChat public account:YuanChuan Institute (ID: YuanChuanInstitution), Author: Chen Bin
This content represents the author’s independent viewpoint and does not represent the position of Huxiu. Reproduction without permission is prohibited. For authorization matters, please contact [email protected]. If you have any objections or complaints about this article, please contact [email protected]
End
Answer the questionnaire to receive discounts
“Is the ride-hailing service you called safe?”

While utilizing technology to change transportation methods, ride-hailing platforms need to answer how to better ensure user safety through technology.
To further enhance the safety level of ride-hailing, the “Ride-Hailing Safety Questionnaire” focuses on public concerns regarding safety product functions, driver safe driving, etc., to understand the public’s most genuine feelings and suggestions regarding ride-hailing safety.
Scan the QR code in the image or click on the “Read the original text” below to participate in the survey, and receive May Day travel discount benefits, starting from 50% off.
We look forward to your participation.