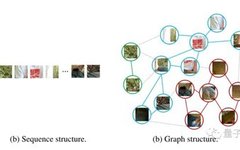
There is considerable research on using Graph Neural Networks (GNN) for computer vision (CV), but it typically revolves around point cloud data, with few directly addressing image data. Compared to CNNs, which treat an image as a grid, and Transformers, which flatten images into sequences, graph methods are more suitable for learning features of irregular and complex objects.Recently, the Chinese Academy of Sciences and Huawei’s Noah’s Ark Lab proposed a novel backbone network that represents images as graph-structured data, enabling GNNs to perform the three classic CV tasks.
This paper has attracted widespread attention from GNN scholars. Some believe that years of accumulated techniques in the GNN field will flood into this new direction, sparking a wave of research enthusiasm.

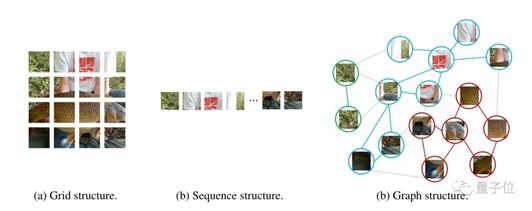
The research team believes that graph structures are a more universal data structure. Even grids and sequences can be considered special cases of graph structures, making visual perception using graph structures more flexible. Graph data consists of nodes and edges; however, treating each pixel as a node would be computationally intensive, so the team adopted a patch method.For images with a resolution of 224×224, each 16×16 pixel block is considered a patch, which corresponds to a node in the graph data, resulting in a total of 196 nodes.For each node, the nearest neighboring nodes are searched to form edges, with the number of edges increasing with network depth.The network architecture is divided into two parts:A Graph Convolutional Network (GCN) that handles graph data and aggregates features from neighboring nodes.A Feedforward Neural Network (FFN) that has a simpler structure consisting of two fully connected layers in an MLP, responsible for feature transformation.
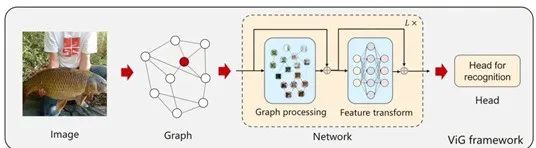
Traditional GCNs can suffer from over-smoothing. To address this issue, the team added a linear layer before and after the graph convolutional layer, and an activation function after the graph convolutional layer.
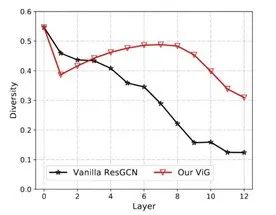
Experiments show that using the new method, when the number of layers is high, the features learned by ViG are more diverse than those learned by traditional ResGCN.To more accurately evaluate the performance of ViG, the research team designed two ViG networks with isotropic and pyramid structures, commonly used in ViT and CNN, respectively, for comparative experiments.The isotropic architecture of ViG is divided into three specifications.
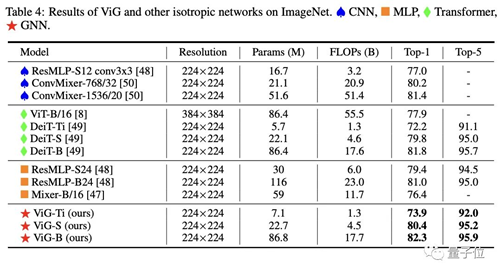
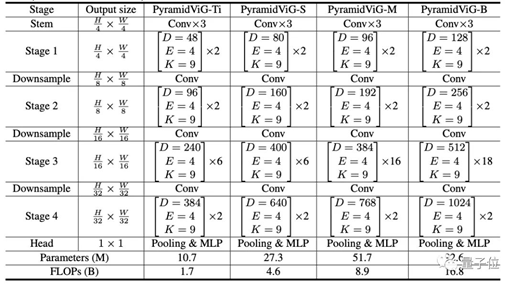
Compared to common isotropic CNN, ViT, and MLP networks, ViG performs better in ImageNet image classification under the same computational cost.The specific settings of the pyramid structure ViG network are as follows.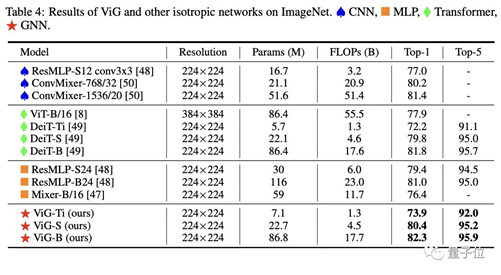 Under the same computational cost, ViG also outperforms or matches the performance of state-of-the-art CNN, ViT, and MLP.
Under the same computational cost, ViG also outperforms or matches the performance of state-of-the-art CNN, ViT, and MLP.
In object detection and instance segmentation tests, ViG performs comparably to the Swin Transformer of similar scale.

Finally, the research team hopes that this work will serve as a foundational architecture for GNNs in general visual tasks, with both Pytorch and Mindspore versions of the code being open-sourced.Paper link: http://arxiv.org/abs/2206.00272Open-source link: https://github.com/huawei-noah/CV-Backbones https://gitee.com/mindspore/modelsThis article is contributed by the CAAI Cognitive Systems and Information Processing Committee.
Long press the QR code to follow CAAI for more media matrix

Official WeChat

Membership Number

English Official WeChat