Abstract
GPT (Generative Pre-trained Transformer) is a neural network model based on the Transformer architecture, which has become an important research direction in the field of natural language processing. This article will introduce the development history and technological changes of GPT, outlining the technical upgrades and application scenarios from GPT-1 to GPT-3, exploring the applications of GPT in natural language generation, text classification, language understanding, and the challenges it faces, as well as future development directions.
Timeline
GPT-1: A Pre-trained Model Based on Unidirectional Transformer
-
High-quality labeled data is difficult to obtain;
-
Models are limited to their training, lacking generalization ability;
-
They cannot perform out-of-the-box tasks, limiting the practical application of the models.
GPT-2: A Multi-task Pre-trained Model

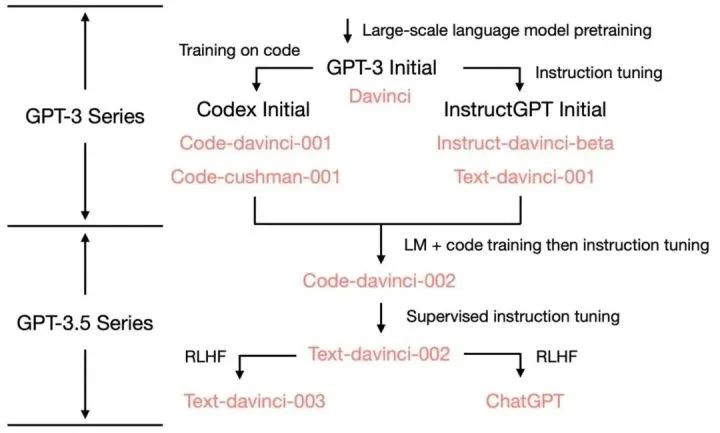
GPT-3: Creating New Natural Language Generation and Understanding Capabilities
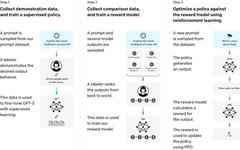
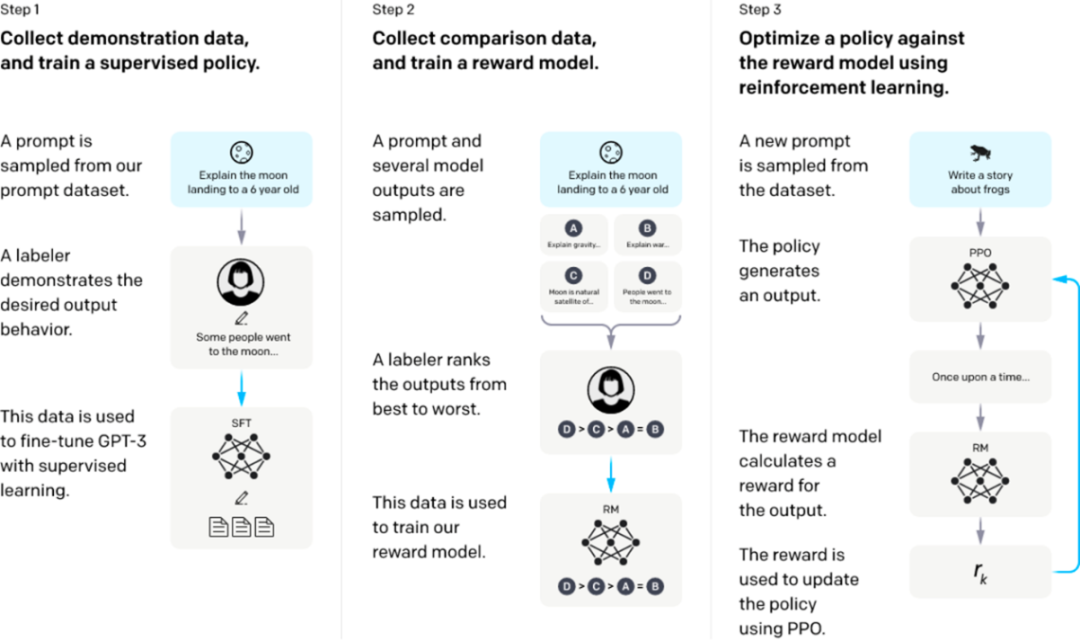
InstructGPT & ChatGPT
Appendix:

References
1. Dissecting the Origins of GPT-3.5’s Capabilities: https://yaofu.notion.site/GPT-3-5-360081d91ec245f29029d37b54573756
2. The Most Comprehensive Timeline! From the Past and Present of ChatGPT to the Current Competitive Landscape in AI: https://www.bilibili.com/read/cv22541079
3. GPT-1 Paper: Improving Language Understanding by Generative Pre-Training, OpenAI.
4. GPT-2 Paper: Language Models are Unsupervised Multitask Learners, OpenAI.
5. GPT-3 Paper: Language Models are Few-Shot Learners, OpenAI.
6. Jason W, Maarten B, Vincent Y, et al. Finetuned Language Models Are Zero-Shot Learners[J]. arXiv preprint arXiv: 2109.01652, 2021.
7. How OpenAI “Devil Trained” GPT? — InstructGPT Paper Interpretation: https://cloud.tencent.com/developer/news/979148
China Confidential Association
Science and Technology Branch
Long press to scan the code to follow us

Author: Zhang Wanyue, University of Chinese Academy of Sciences
Editor: Vision
Top 5 Highlights of 2022
Cross-network attacks: An introduction to breakthrough physical isolation network attack techniques
Introduction to LaserShark Contactless Attack Implant Technology
Exciting Article Review of the Period
Overview of Searchable Encryption Technology
Security Analysis of Electric Vehicle Charging Station Management Systems
Summary of Common Cybersecurity Threats and Their Protective Technologies
Analysis of Security Algorithm and Protocol Verification Issues
Analysis of IoT Security Issues in Blockchain