

▐ Installation
Please refer to the installation guide for SD WebUI: https://github.com/AUTOMATIC1111/stable-diffusion-webui/wiki/Install-and-Run-on-NVidia-GPUs
SD WebUI uses the Gradio component package. When configuring share=True, it creates an FRPC tunnel and connects to AWS. For details, please refer to https://www.gradio.app/guides/sharing-your-app. Therefore, when starting the SD WebUI application, please consider whether to disable the share=True configuration or remove the FRPC client based on your safety production or privacy protection requirements.
▐ Models
https://civitai.com/ is an open-source SD model community that provides rich models for free download and use. Here’s a brief description of the model classifications, which can help improve the use of SD WebUI. The SD model training methods are mainly divided into four categories: Dreambooth, LoRA, Textual Inversion, and Hypernetwork.
-
Dreambooth: A large model obtained through the Dreambooth training method based on the SD base model. It is a complete new model, with slower training speed and larger model file sizes, generally several gigabytes, and the model file format is safetensors or ckpt. Its characteristic is good output effect, with significant improvement in certain artistic styles. As shown in the figure below, this type of model can be selected in SD WebUI.
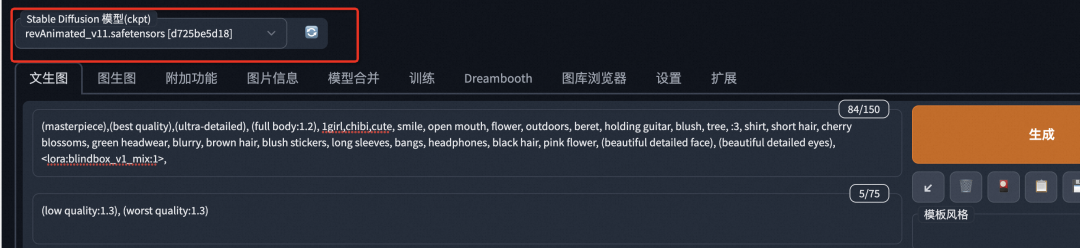
-
LoRA: A lightweight model fine-tuning training method that fine-tunes the existing large model to output fixed features of people or things. It is characterized by good output effects for specific styles, fast training speed, small model files, generally tens to over a hundred MB, and cannot be used independently. It needs to be used in conjunction with the original large model. SD WebUI provides a LoRA model plugin and the method for using LoRA models, which can be seen in the “Operation Process -> LoRA Model” section of this article.
-
Textual Inversion: A method of fine-tuning the model using text prompts and corresponding style images. The text prompts are usually special words, and once the model training is complete, these words can be used in text prompts to control the style and details of the generated images, requiring the original large model to be used together.
-
Hypernetwork: A method similar to LoRA for fine-tuning large models, needing to be used in conjunction with the original large model.

▐ Prompt Derivation
-
Upload an image in SD.
-
Reverse derive keywords using two models: CLIP and DeepBooru. As shown in Figure 1:

Figure 1: High-definition photo taken with the original camera of iPhone 14 Pro Max
A baby is laying on a blanket surrounded by balloons and balls in the air and a cake with a name on it, Bian Jingzhao, phuoc quan, a colorized photo, dada
1boy, ball, balloon, bubble_blowing, chewing_gum, hat, holding_balloon, male_focus, military, military_uniform, open_mouth, orb, solo, uniform, yin_yang
The CLIP reverse derivation result is a sentence, while the DeepBooru reverse derivation result consists of keywords.
You can modify the positive prompt or add a reverse prompt. The reverse prompt is used to restrict the model from adding elements that appear in the reverse prompt when generating images. The reverse prompt is not mandatory and can be left empty.
▐ LoRA Model
The LoRA model has a strong intervention or enhancement effect on the style and quality of images generated by the large model, but the LoRA model needs to be used in conjunction with the corresponding large model and cannot be used alone. There are mainly two ways to use the LoRA model in SD WebUI:
-
Method One
*/stable-diffusion-webui/extensions/sd-webui-additional-networks/models/loradirectory. New models need to restart SD WebUI, and after the plugin and model are loaded correctly, “Optional Additional Networks (LoRA Plugin)” will appear in the lower left corner of the WebUI operation interface. To trigger LoRA when generating images, select the LoRA model in the plugin and add Trigger Words in the positive prompt. In the figure below, the selected LoRA model is blindbox_v1_mix, and the trigger words are full body, chibi. Each LoRA model has its unique Trigger Words, which will be noted in the model’s introduction.
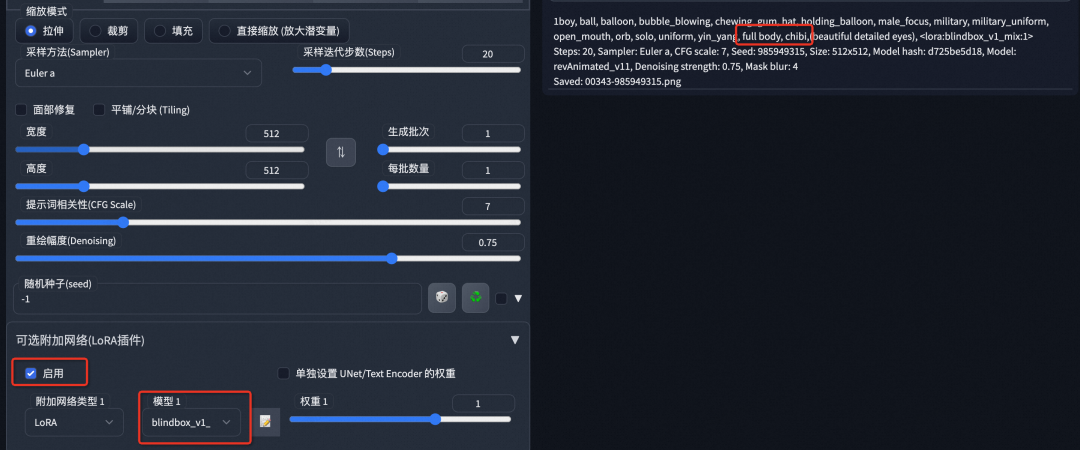
If the plugin does not respond after clicking install or shows an error due to a flag, it is because the setting for allowing extension plugins during web UI startup is disabled. You need to add the startup parameter: –enable-insecure-extension-access when starting the web UI.
./webui.sh --xformers --enable-insecure-extension-access-
Method Two
Do not use the additional-network plugin; use the default supported method for LoRA models in SD WebUI. You need to place the LoRA model in
*/stable-diffusion-webui/models/Loradirectory. Restart SD WebUI, and the model will be automatically loaded.
In the positive prompt, add the LoRA model activation statement to trigger the LoRA model when generating images:

WebUI provides an auto-fill function for LoRA prompts. Clicking the icon shown in the figure can open the LoRA model list, and then clicking the model area will automatically fill the statement into the positive prompt area:

Either of the above two methods can effectively enable the LoRA model in content production. Using both methods simultaneously will not cause any issues.
▐ ControlNet
ControlNet attempts to control the pre-trained large model, such as Stable Diffusion, by supporting additional input conditions. Purely text control methods make content production feel like a gamble, where the results are uncontrollable and difficult to achieve expected effects. The emergence of ControlNet has brought content generation of the Stable Diffusion large model into a controllable era, making creation more manageable and advancing AIGC in industrial applications.
-
Install ControlNet
In SD WebUI, click on Extensions, go to the plugin installation page, find the ControlNet plugin, and click install to complete the plugin installation.
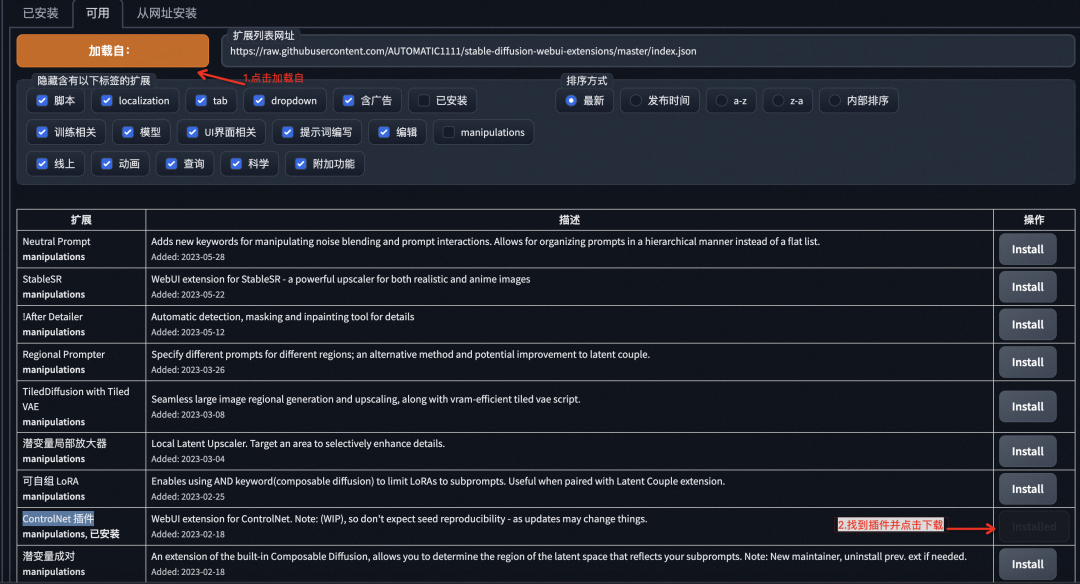
Download the open-source ControlNet model
Download link: https://huggingface.co/lllyasviel/ControlNet-v1-1/tree/main
A model consists of two files: .pth and .yaml, both need to be downloaded. The letter after “V11” in the filename indicates its status: p: available, e: experimental, u: incomplete. Place the downloaded model in the following directory and restart SD WebUI to complete the loading of the ControlNet model.
*\stable-diffusion-webui\extensions\sd-webui-controlnet\models▐ Image-to-Image Example
-
Model Selection
4. Use the source image from Figure 1, generate positive prompts using the DeepBooru model, add specific prompts for revAnimated_v11, remove some positive prompts, and add reverse prompts. The final prompt used is as follows:
Positive:
(masterpiece),(best quality), (full body:1.2), (beautiful detailed eyes), 1boy, hat, male, open_mouth, smile, cloud, solo, full body, chibi, military_uniform, <lora:blindbox_v1_mix:1>
(low quality:1.3), (worst quality:1.3)
The generated image is:

Figure 1: Original image


▐ Text-to-Image Example
-
Model Selection
-
Choose stable diffusion large model: revAnimated_v11 (https://civitai.com/models/7371?modelVersionId=46846)
-
Choose LoRA model: blind_box_v1_mix (https://civitai.com/models/25995?modelVersionId=32988)
-
Sampling method: Euler a
Example 1
(masterpiece),(best quality),(ultra-detailed), (full body:1.2), 1girl, youth, dynamic, smile, palace, tang dynasty, shirt, long hair, blurry, black hair, blush stickers, (beautiful detailed face), (beautiful detailed eyes), <lora:blindbox_v1_mix:1>, full body, chibi
(low quality:1.3), (worst quality:1.3)

Example 2
(masterpiece),(best quality),(ultra-detailed), (full body:1.2), 1girl, chibi, sex, smile, open mouth, flower, outdoors, beret, jk, blush, tree, :3, shirt, short hair, cherry blossoms, blurry, brown hair, blush stickers, long sleeves, bangs, black hair, pink flower, (beautiful detailed face), (beautiful detailed eyes), <lora:blindbox_v1_mix:1>
(low quality:1.3), (worst quality:1.3)

Prompt Analysis
-
(masterpiece),(best quality),(ultra-detailed), (full body:1.2), (beautiful detailed face), (beautiful detailed eyes) These words in parentheses are prompts for the revAnimated_v11 model to improve the quality of generated images.
-
<lora:blindbox_v1_mix:1> is the prompt to trigger the blind_box_v1_mix model.
-
full body, chibi are trigger words for the blind_box_v1_mix model.
-
The remaining prompts describe the content of the image.
-
The revAnimated_v11 model is sensitive to the order of prompts; prompts placed at the beginning have a greater impact on the results than those placed later.
▐ VAE
In practical use of SD, the VAE model acts as a filter and fine-tuning tool. Some SD models come with their own VAE and do not require separate mounting of VAE. The VAE model that accompanies the model is usually provided with a download link on the model release page.
-
Model Installation
/stable-diffusion-webui/models/VAE
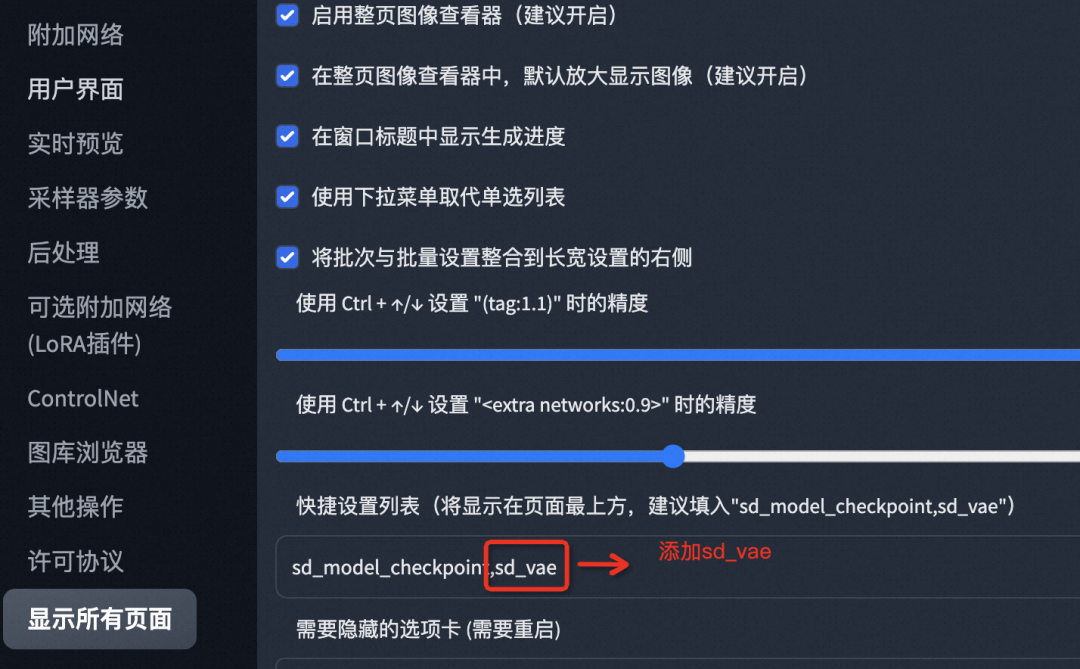
If you do not see this selection box on the web UI, go to Settings -> User Interface -> Quick Settings List to add the configuration “sd_vae”, as shown below:
-
Effect



Conclusion
-
The learning curve for SD WebUI is relatively steep. Having some knowledge in the field of image processing can help users better choose and combine models. -
Users with no foundation may randomly choose models and mix them up, resulting in output effects that are completely different from expectations after a series of operations on the SD WebUI interface. It is recommended to understand the characteristics of each model before making selections based on actual goals. -
SD is open-source, and SD WebUI is a toolbox, not a commercial product. There are many excellent models in the community, with high upper limits for output, but also low lower limits. Open-source does not mean no cost, as SD WebUI requires high hardware configurations for deployment. To save learning costs, achieve relatively stable output effects, and have a simple and convenient user experience without hardware configuration requirements, Midjourney is currently the first choice, but it requires a subscription fee.
