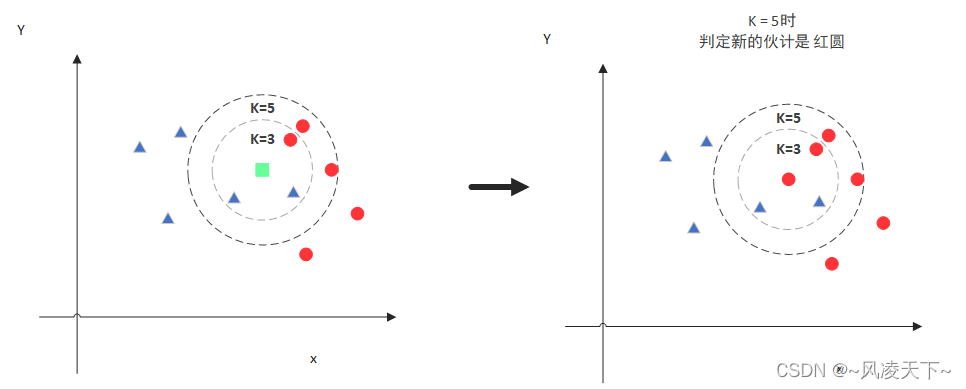
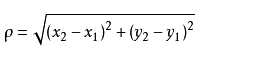
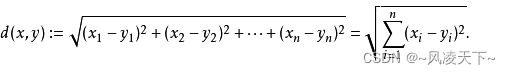
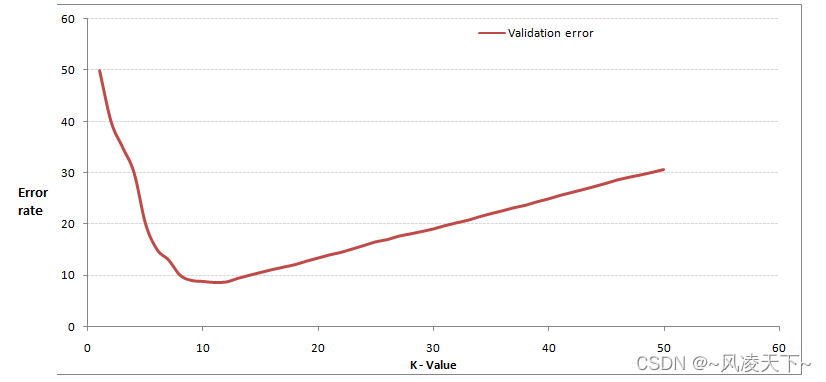
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <math.h>
#include <stdint.h>
#include <stdbool.h>
/* A handwritten number structure */
typedef struct {
int pixel[1024];
int number;
} SampleData;
/* A distance structure with label */
typedef struct {
float distance;
int number;
} CalculationData;
/* File path + name */
static const char* TrainingFilePath = "./my-digit-training.txt";
static const char* TestingFilePath = "./my-digit-testing.txt";
static const char* CalculationFilePath = "./my-digit-predict.txt";
/* Number of digits in each dataset */
#define TRAINING_SIZE 943
#define TRAINING_COUNT 10
#define TEST_SIZE 196
#define CALCULATION_SIZE 9
/* Calculate distance */
float CalculateDistance(SampleData sample_01, SampleData sample_02) {
int i, square_sum=0.0;
for(i=0; i<1024; i++) {
square_sum += pow(sample_01.pixel[i]-sample_02.pixel[i], 2.0);
}
return sqrtf(square_sum);
}
/* Load data from file into memory */
int DataLoading(SampleData *pSampleDate_t, FILE *fp, int *pNumber) {
int index=0;
for(index = 0; index<1024; index++) {
if(!fscanf(fp, "%d", &pSampleDate_t->pixel[index])) {
printf("FILE already read finish.\n");
return -true;
}
}
fscanf(fp, "%d", &pSampleDate_t->number);
*pNumber = pSampleDate_t->number;
return true;
}
/* Display a Digit structure */
void ShowSampleDate(SampleData SampleData_t) {
int i, j, id;
for(i=0;i<32;i++) {
for(j=0;j<32;j++) {
printf("%d", SampleData_t.pixel[i*32+j]);
}
printf("\n");
}
printf(" %d \n", SampleData_t.number);
}
/* Swap two items in a string */
void IndexExchange(CalculationData *in, int index1, int index2) {
CalculationData tmp = (CalculationData)in[index1];
in[index1] = in[index2];
in[index2] = tmp;
}
/* Selection sort */
void SelectSort(CalculationData *in, int length) {
int i, j, min;
int N = length;
for(i=0; i<N-1; i++) {
min = i;
for(j=i+1;j<N;j++) {
if(in[j].distance<in[min].distance) min = j;
}
IndexExchange(in,i,min);
}
}
/* Predict a digit using training data */
int DataForecast(int K, SampleData in, SampleData *train, int nt)
{
int i, it;
CalculationData distance[nt];
/* Calculate the distance between the input digit and the training data */
for(it=0; it<nt; it++) {
distance[it].distance = CalculateDistance(in, train[it]);
distance[it].number = train[it].number;
}
/* Sort the calculated distances (selection sort) */
int predict = 0;
SelectSort(distance, nt);
for(i=0; i<K; i++) {
predict += distance[i].number;
}
return (int)(predict/K);
}
/* Test the dataset with testing data */
void KnnDatasetClassification(int K)
{
printf(".KnnDatasetClassification.\n");
int i;
FILE *fp;
/* Read training data */
int trainLabels[TRAINING_SIZE];
int trainCount[TRAINING_COUNT] = {0};
SampleData *pSampleTrain_t = (SampleData*)malloc(TRAINING_SIZE*sizeof(SampleData));
fp = fopen(TrainingFilePath,"r");
if (fp < 0) {
printf("..Open %s Error.\n", TrainingFilePath);
exit(0);
}
printf("..load training digits.\n");
for(i=0; i<TRAINING_SIZE; i++) {
DataLoading(&pSampleTrain_t[i], fp, &trainLabels[i]);
trainCount[pSampleTrain_t[i].number]++;
}
fclose(fp);
printf("..Done.\n");
/* Read testing data */
int testLabels[TEST_SIZE];
int testCount[TRAINING_COUNT] = {0};
SampleData *pSampleDataTest_t = (SampleData*)malloc(TEST_SIZE*sizeof(SampleData));
fp = fopen(TestingFilePath,"r");
if (fp < 0) {
printf("..Open %s Error.\n", TestingFilePath);
exit(0);
}
printf("..load testing digits.\n");
for(i=0;i<TEST_SIZE;i++) {
DataLoading(&pSampleDataTest_t[i], fp, &testLabels[i]);
testCount[pSampleDataTest_t[i].number]++;
}
fclose(fp);
printf("..Done.\n");
/* Calculate the distance between testing data and training data */
printf("..Cal CalculationData begin.\n");
CalculationData Distance2Train[TRAINING_SIZE];
int CorrectCount[TRAINING_COUNT] = {0};
int itrain, itest, predict;
for(itest=0; itest < TEST_SIZE; itest++) {
predict = DataForecast(K, pSampleTrain_t[itest], pSampleTrain_t, TRAINING_SIZE);
//printf("%d-%d\n",predict, Dtest[itest].number);
/* Count the correctly predicted ones */
if(predict == pSampleDataTest_t[itest].number) {
CorrectCount[predict]++;
}
}
/* Output the accuracy of testing data */
printf(" Correct radio: \n\n");
for(i=0;i<10;i++) {
printf("%d: ( %2d / %2d ) = %.2f%%\n",
i,
CorrectCount[i],
testCount[i],
(float)(CorrectCount[i]*1.0/testCount[i]*100));
}
}
/* Predict data */
void KnnPredict(int K) {
int i;
FILE *fp = NULL;
/* Read training data */
int trainLabels[TRAINING_SIZE];
int trainCount[TRAINING_COUNT] = {0};
SampleData *Dtrain = (SampleData*)malloc(TRAINING_SIZE*sizeof(SampleData));
fp = fopen(TrainingFilePath,"r");
printf("..load training digits.\n");
for(i=0; i<TRAINING_SIZE; i++) {
DataLoading(&Dtrain[i], fp, &trainLabels[i]);
trainCount[Dtrain[i].number]++;
}
fclose(fp);
printf("..Done.\n");
/* Read the data to be predicted */
int predictLabels[CALCULATION_SIZE];
int predictCount[TRAINING_COUNT] = {0};
SampleData *Dpredict = (SampleData*)malloc(CALCULATION_SIZE*sizeof(SampleData));
fp = fopen(CalculationFilePath,"r");
printf("..load predict digits.\n");
for(i=0;i<CALCULATION_SIZE;i++) {
DataLoading(&Dpredict[i], fp, &predictLabels[i]);
predictCount[Dpredict[i].number]++;
}
fclose(fp);
printf("..Done.\n");
/* Calculate the distance between input data and training data */
printf("..Cal CalculationData begin.\n");
CalculationData Distance2Train[TRAINING_SIZE];
int itrain, ipredict, predict;
for(ipredict=0; ipredict<CALCULATION_SIZE; ipredict++) {
predict = DataForecast(K, Dpredict[ipredict], Dtrain, TRAINING_SIZE);
printf("%d\n",predict);
}
}
int main(int argc, char** argv)
{
int K = 1;
/* Test known data and count the prediction accuracy */
KnnDatasetClassification(K);
/* Predict the location data */
KnnPredict(K);
return 1;
}
The output of the code is as follows:
.KnnDatasetClassification.
..load training digits.
..Done.
..load testing digits.
..Done.
..Cal CalculationData begin.
Correct radio:
0: ( 1 / 20 ) = 5.00%
1: ( 2 / 20 ) = 10.00%
2: ( 4 / 25 ) = 16.00%
3: ( 0 / 18 ) = 0.00%
4: ( 1 / 25 ) = 4.00%
5: ( 3 / 16 ) = 18.75%
6: ( 1 / 16 ) = 6.25%
7: ( 3 / 19 ) = 15.79%
8: ( 3 / 17 ) = 17.65%
9: ( 2 / 20 ) = 10.00%
..load training digits.
..Done.
..load predict digits.
..Done.
..Cal CalculationData begin.
5
2
1
8
2
9
9
1
5
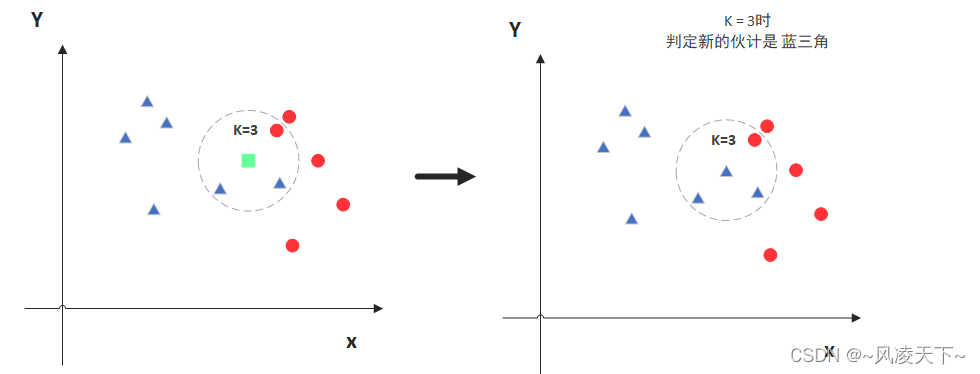
The percentage output indicates the recognition accuracy for each different digit.The final output is the result obtained when inputting a single example, which is completely consistent with the input sample.The code will use three files: one is the training file, one is the testing file, and one is the single instance testing file.Complete code download link:https://rtoax.blog.csdn.net/article/details/80309077