
Author: Fan Bao et al.

Article link: https://arxiv.org/pdf/2405.04233 Open source address: https://www.shengshu-ai.com/vidu
Vidu is China’s first long video generation AI large model, jointly released by Tsinghua University and Shengshu Technology. Recently, many impressive effect presentations have been released, and this newly published interpretive article introduces the technology used by Vidu, let’s learn together.



This article introduces Vidu, a high-performance text-to-video generator capable of generating 1080p videos lasting up to 16 seconds in a single generation. Vidu is a diffusion model with a backbone of U-ViT, which gives it the scalability and capability to handle long videos. Vidu has strong coherence and dynamics, and can generate realistic and imaginative videos, as well as understand some professional photography techniques, comparable to Sora—the most powerful reported text-to-video generator. Finally, preliminary experiments on other controllable video generation, including edge detection to video generation, video prediction, and subject-driven generation, show promising results.
Introduction
Diffusion models have made breakthrough progress in generating high-quality images, videos, and other types of data, surpassing alternative methods like autoregressive networks. Previously, video generation models mainly relied on diffusion models with U-Net backbones and focused on limited durations like 4 seconds. The model in this paper, Vidu, demonstrates that a text-to-video diffusion model with a U-ViT backbone can break this duration limitation by leveraging the scalability and long-sequence modeling capabilities of transformers. Vidu can generate 1080p videos lasting up to 16 seconds in a single generation, as well as single-frame images as videos.
Furthermore, Vidu has strong coherence and dynamics, capable of generating realistic and imaginative videos. Vidu also has a preliminary understanding of some professional photography techniques, such as transition effects, camera movements, lighting effects, and emotional expressions. To some extent, Vidu’s generation performance is comparable to the currently most powerful text-to-video generator, Sora, far surpassing other text-to-video generators. Lastly, preliminary experiments on other controllable video generation, including edge detection to video generation, video prediction, and subject-driven generation, all demonstrate promising results.
Text-to-Video Generation
Vidu first employs a video autoencoder to reduce the spatial and temporal dimensions of videos for efficient training and inference. After that, Vidu uses U-ViT as a noise prediction network to model these compressed representations. Specifically, as shown in Figure 1 below, U-ViT segments the compressed video into 3D patches, treating all inputs (including time, text conditions, and noisy 3D patches) as tokens, and uses long skip connections between shallow and deep layers of the transformer. By leveraging the transformer’s ability to handle variable-length sequences, Vidu can process videos of different durations.
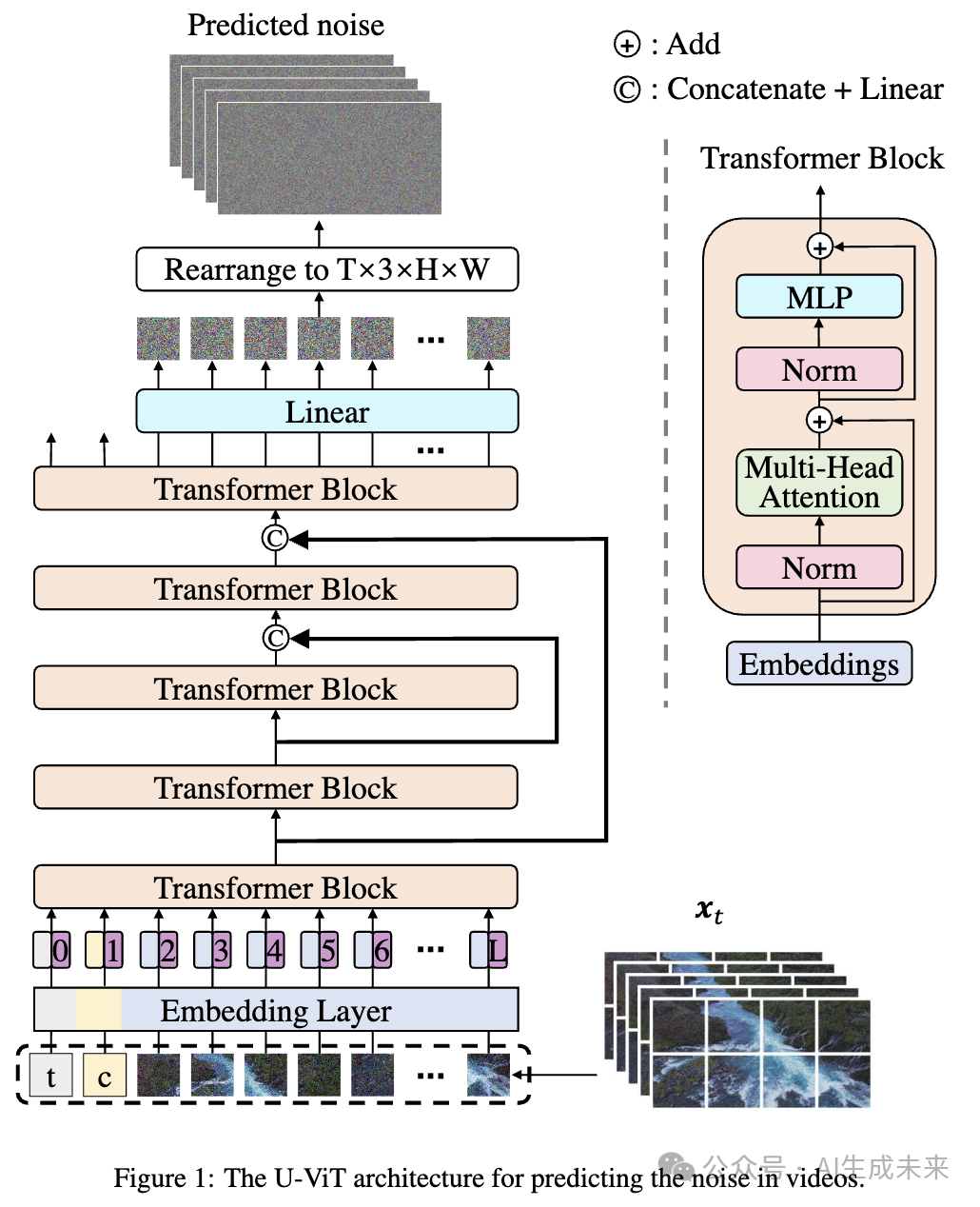
Vidu is trained on a large number of text-video pairs, but it is impractical to have all videos labeled by humans. To solve this problem, a high-performance video captioning generator optimized for understanding dynamic information in videos is first trained, and then this captioning generator is used to automatically label all training videos. During inference, a re-captioning technique is applied to reformulate user input into a form more suitable for the model.
Generating Videos of Different Lengths
Since Vidu is trained on videos of various lengths, it can generate 1080p videos of all lengths up to 16 seconds, including single-frame images as videos. Examples are presented in Figure 2 below.

3D Consistency
The videos generated by Vidu exhibit strong 3D consistency. As the camera rotates, the video presents projections of the same object from different angles. For example, as shown in Figure 3 below, the generated cat’s fur is naturally occluded as the camera rotates.

Generating Transitions
Vidu is capable of generating videos that include transitions. As shown in Figure 4 below, these videos present different perspectives of the same scene by switching camera angles while maintaining the consistency of the subjects in the scene.

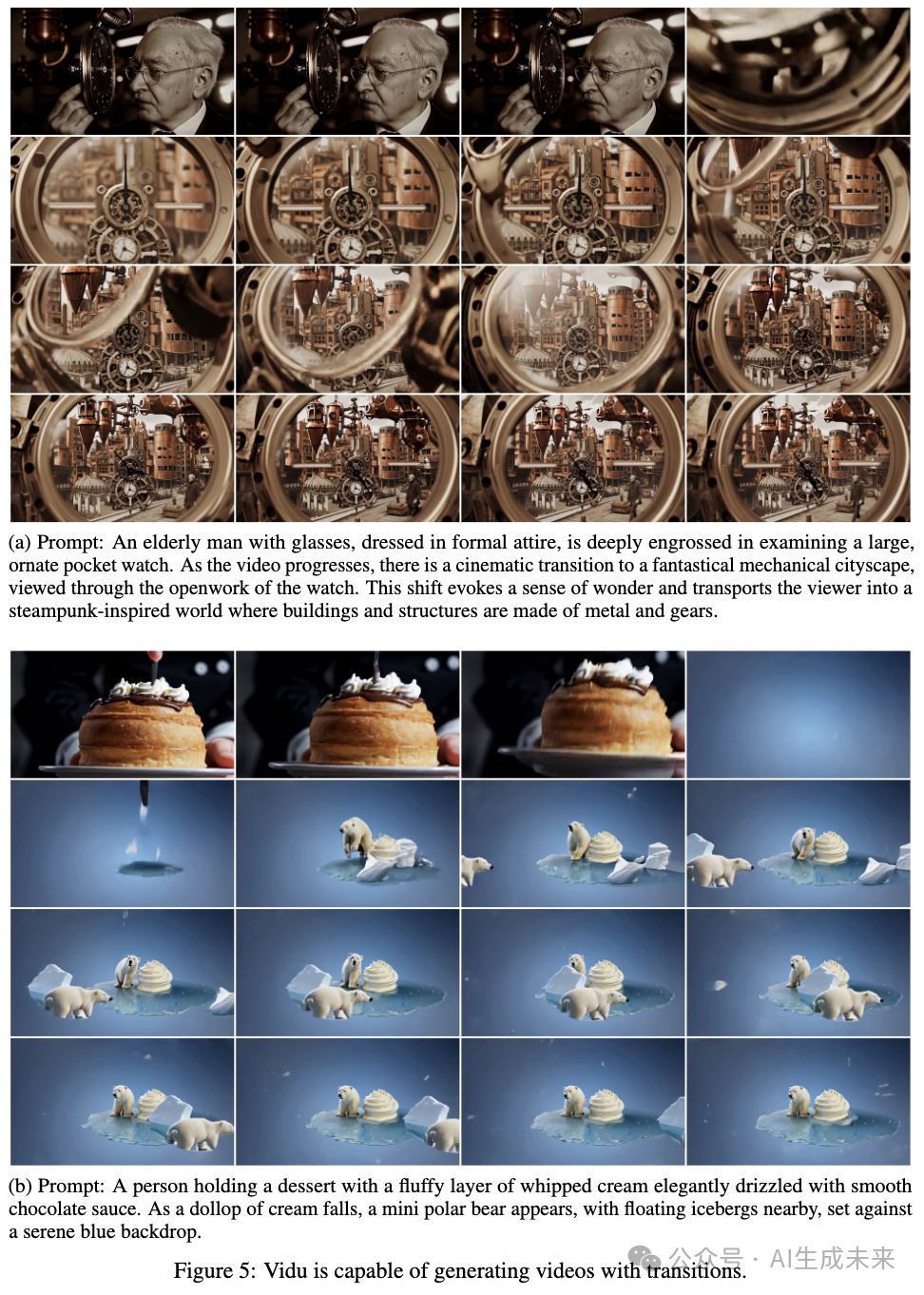
Generating Transition Effects
Vidu is capable of generating videos with transition effects in a single generation. As shown in Figure 5 below, these transition effects can connect two different scenes in an engaging way.
Camera Movements
Camera movements involve physical adjustments or movements of the camera during shooting, enhancing visual storytelling and conveying different perspectives and emotions within the scene. Vidu learned these techniques from the data, enhancing the viewer’s visual experience. For example, as shown in Figure 6, Vidu is capable of generating videos that include camera movements such as zooming, panning, and tilting.

Lighting Effects
Vidu is capable of generating videos with impressive lighting effects, which helps enhance the overall atmosphere. For example, as shown in Figure 7 below, the generated video can evoke a sense of mystery and tranquility. Thus, in addition to the entities within the video content, Vidu also has a preliminary ability to convey some abstract emotions.

Emotional Portrayal
Vidu can effectively depict the emotions of characters. For example, as shown in Figure 8 below, Vidu can express emotions such as happiness, loneliness, awkwardness, and joy.

Imagination
In addition to generating scenes from the real world, Vidu also possesses rich imagination. As shown in Figure 9 below, Vidu can generate scenes that do not exist in the real world.

Comparison with Sora
Sora is currently the most powerful text-to-video generator, capable of generating high-definition videos with high consistency. However, since Sora is not publicly accessible, comparisons were made by directly inserting the example prompts released by Sora into Vidu. Figures 10 and 11 describe the comparison between Vidu and Sora, indicating that to some extent, Vidu’s generation performance is comparable to Sora.


Other Controllable Video Generation
Several preliminary experiments on other controllable video generation have also been conducted at a resolution of 512, including edge detection to video generation, video prediction, and subject-driven generation. All these demonstrate promising results.
Edge Detection to Video Generation
Vidu can add additional control using techniques similar to ControlNet, as shown in Figure 12 below.

Video Prediction
As shown in Figure 13 below, Vidu can generate subsequent frames based on input images or several input frames (marked with red boxes).

Subject-Driven Generation
Surprisingly, we found that Vidu can perform subject-driven video generation by fine-tuning only on images rather than videos. For example, we used DreamBooth technology to specify the learned subject as a special symbol <V> for fine-tuning. As shown in Figure 14 below, the generated video faithfully reproduces the learned subject.

Conclusion
Vidu, a high-definition text-to-video generator, demonstrates strong capabilities in various aspects, including the duration, coherence, and dynamics of the generated videos, comparable to Sora. In the future, Vidu still has room for improvement. For instance, there are occasional defects in details, and interactions between different subjects in the video sometimes deviate from physical laws. It is believed that with further expansion of Vidu, these issues can be effectively resolved.
References
[1] Vidu: a Highly Consistent, Dynamic and Skilled Text-to-Video Generator with Diffusion Models
Join the AIGC Technology Exchange Group, please add the assistant with a note

Previous Recommendations
SAM-Lightening is 30 times faster than SAM! It takes only 7 milliseconds to infer an image (Beihang University)
Tsinghua & VAST propose CharacterGen: generating high-quality 3D characters from a single image
From Adversarial Training to Diffusion Networks: Where Should Image Restoration Go in the Diffusion Era?
LLM and Autonomous Driving Join Forces | DriveDreamer-2: Custom Video Generation World Model for Autonomous Driving!