
Click the


◎ Guan Chunyan
Abstract: Whether training generative artificial intelligence can fall under fair use is crucial for its long-term development, attracting widespread attention from various countries. The United States broadens the scope of fair use based on “transformative use”; the European Union establishes conditional copyright exceptions relying on a “opt-out” mechanism; Japan forms a flexible copyright exception centered on “non-enjoyment”. Conversely, China faces both practical needs and challenges. On one hand, this can alleviate algorithmic discrimination and value bias, promoting international knowledge flow and technological innovation; on the other hand, it risks existing models being relatively closed and infringing on copyright holders’ interests. In the future, fair use should serve as an interface to construct reasonable use provisions for generative artificial intelligence, expanding the subject requirements to “any entity that can legally obtain works”; defining the purpose as “use for scientific research or promoting knowledge innovation”; and including actions not limited to “copying” but excluding “distribution”; while adding safety measures.
Keywords: Generative Artificial Intelligence, Fair Use, Text Data Mining, Opt-out Mechanism, Benefit Compensation Mechanism
Classification Number: D923.41
Generative Artificial Intelligence (GAI) relies on a large amount of text data for its training. Whether data acquisition and training necessarily constitute copyright infringement, and whether fair use can be invoked for exemption, directly relates to the future of GAI. The legal applicability of generative artificial intelligence training and text and data mining (TDM) has continuity. Scholars have studied the dilemmas of applying fair use to TDM, foreign practices and references, and the design of institutional systems, laying the groundwork for constructing a fair use system for generative artificial intelligence training. From an international perspective, many countries have recognized the positive role of copyright exemptions in the development of GAI and hope to gain a competitive edge in a new round of international competition. In contrast, China has yet to establish fair use provisions for artificial intelligence at the legislative level; the judicial system’s attention to this issue is also insufficient.[1]In light of this, the author intends to start from the international trend of incorporating generative artificial intelligence training into fair use, summarizing distinctive models and common pursuits; analyzing the practical needs and challenges of incorporating generative artificial intelligence training into fair use in China; and based on this, exploring localized applicable provisions and rule construction.
1. International Trends in Incorporating Generative Artificial Intelligence Training into Fair Use
(1) Distinctive Models of Incorporating Generative Artificial Intelligence Training into Fair Use
1. United States: Broadening Fair Use Based on “Transformative Use”
As a common law country, the United States has affirmed the fair use of text data mining in several judicial rulings. The case of Williams & Wilkins Co. v. United States is the first case in the U.S. where a research institution copied another’s work without permission for research purposes.[5]In this case, researchers copied photos from the publisher’s scientific journals (“Medicine”, “Journal of Immunology”, “Gastroenterology”, and “Pharmacological Reviews”) for personal use in their research work, without selling or distributing the articles. Furthermore, the research institution limited the copied text to one copy, with a length restriction of 50 pages. The court noted that the defendant’s copying did not cause serious adverse effects on the plaintiff and ruled that the research institution’s usage did not constitute infringement.
In the Google Books case (Authors Guild, Inc. v. Google, Inc.), the court allowed Google to create digital copies of copyrighted works without authorization to implement search functions and display excerpts. The court found this action transformative and in line with the requirements for “transformative use”.[7]Similarly, in the HathiTrust case (Authors Guild, Inc. v. Hathi Trust), the court permitted libraries to digitize copyrighted works for full-text searchability. Creating a full-text search database is also a transformative use. Both cases were adjudicated by the Second Circuit Court of Appeals, which incorporated their usage into fair use due to its sufficient transformative nature. It is noteworthy that Google is a profit-oriented commercial company, while HathiTrust is a nonprofit educational entity. This indicates that the U.S. does not impose strict requirements on the commercial and non-commercial nature of TDM; as long as it meets the transformative use requirements, it can be included in the fair use scope. These cases demonstrate the U.S.’s emphasis on promoting technological innovation while strengthening copyright protection, laying the foundation for the development of artificial intelligence technology.
2. European Union: Conditional Copyright Exceptions Based on the “Opt-out” Mechanism
In 2019, the European Union introduced the Directive on Copyright in the Digital Single Market (DSM Copyright Directive), which stipulates two mandatory exceptions for TDM.[10]First, Article 3 targets TDM for scientific research, allowing research institutions and cultural heritage institutions to legally access works or other subjects for scientific research purposes, and to make copies and extractions. This article specifies numerous limitations on TDM, presenting the following characteristics: First, the subject of action is directed toward scientific research institutions and cultural heritage institutions. The former includes universities, research institutes, and other research institutions aimed at scientific research; the latter includes publicly accessible libraries, museums, archives, or heritage institutions for films, audio, etc.[12]Here, the standard of “for scientific research purposes” includes three types: one is based on non-profit nature; two is profit-oriented but reinvests earnings into research; and three is activities approved by the government of member states for public welfare purposes. Thus, the copyright exception for text and data mining does not apply to the general public, meaning non-affiliated individuals or researchers are excluded from the DSM Copyright Directive. Second, from the manner of action, the legal usage is limited to “copying” and “extracting”, without extending to the transformation and processing of the results of copying and extraction. The copyright exception rules do not apply to subsequent stages of use. After copying or extracting text or data content, the subjects must also fulfill an accompanying obligation, which is to take safety measures for the copied or extracted content or to preserve copies based on research purposes. Third, TDM targets “legally accessible content”, meaning content that is accessed with the rights holder’s authorization or publicly available content, including content obtained through subscription agreements and content freely available through internet searches. This requires that the action itself must have the qualification to legally access relevant copyright materials.
Second, Article 4 provides for the “opt-out” mechanism for works. This article fully allows the copying and extraction of legally accessible works or other subjects for TDM purposes, provided that the rights holder has not made a reservation regarding the aforementioned works or other subjects. The introduction of the “opt-out” mechanism in the DSM Copyright Directive means that rights holders can reserve their rights through agreements or unilateral declarations. In other words, rights holders can disallow the copying and extraction of their works for TDM purposes, including publicly available content (such as reserving rights through metadata or website service terms).
3. Japan: Flexible Copyright Exceptions Centered on “Non-enjoyment”
Japan’s fair use principle is composed of Articles 30-4, 47-4, and 47-5 of the Copyright Law, forming a flexible copyright exception centered on “non-enjoyment”. Article 30-4 points to “non-enjoyment” usage behaviors, listing three specific exceptions for “non-enjoyment” purposes: one is technical development experiments; two is text and data mining; three is uses not involving human sensory perception.[15]Article 30-4(2) allows any use of works for text and data mining (TDM).[16]Japan’s TDM copyright exception is very broad, reflected in the following aspects: First, Japan’s TDM copyright exception does not have the restriction of “non-commercial purposes”. In other words, research institutions such as libraries and museums can apply, as can commercial companies with profit motives. Second, a rights holder’s reservation statement cannot counter the TDM copyright exception, meaning the “opt-out” mechanism fails in the field of text and data mining. Third, the 2018 amendment to the Japanese Copyright Law (Article 30-4(2)) removed the requirement of “using a computer” and added the provision of “using in any way”.[17]According to this provision, both digital and analog reproduction are allowed; not only can works be copied, but they can also be distributed and disseminated to the public. For example, for the purpose of “machine learning”, generative artificial intelligence can copy a large amount of text content and distribute the training data of the text content to others engaged in machine learning. Finally, Japan’s TDM copyright exception does not have requirements regarding “legal access”. This means that even content downloaded from illegal websites is permitted for copying for TDM purposes. For instance, an actor can copy a work for “machine learning” to develop artificial intelligence without the copyright holder’s permission and can generate “new” works that resemble the original work’s style. Based on Article 30-4, Japan’s Copyright Law allows artificial intelligence research entities to provide the public with databases formed by copying others’ works, adapting to the needs of the artificial intelligence industry.
(2) Common Pursuits in Incorporating Generative Artificial Intelligence Training into Fair Use
Looking at the regulations of various countries regarding generative artificial intelligence training, there are several commonalities. First, most provisions regarding text and data mining address the subjects of use, purposes, methods of use, and limitations, without involving fundamental changes to the legal system. This is mainly due to considerations of the stability of existing systems and legal orders. Second, the degree of inclusivity regarding generative artificial intelligence training in different countries is closely related to their emphasis on technological development. Overall, countries that have established exceptions for text and data mining generally have a relatively high level of technological advancement and place significant importance on the role of technological development, while the formulation of rules aims to promote technological progress. Currently, many countries and economies have introduced “text and data mining exceptions” to attempt to balance promoting technological progress and protecting copyright holders’ interests.
Countries are increasingly incorporating generative artificial intelligence training into the scope of fair use, with two common pursuits behind the policies. First, to promote technological freedom and self-reliance, driving rapid development of artificial intelligence technology. In the context of the digital economy, innovation increasingly relies on massive data analysis. Excessive protection of copyright holders’ interests may overly constrain usage behaviors and even hinder the development of generative artificial intelligence. Countries have recognized this issue and are attempting to provide support for artificial intelligence development through fair use. Second, to avoid being passive in a new round of international competition. Currently, the development of science and technology is reshaping the new pattern of international competition, and the key role of artificial intelligence in major power competition has become prominent, with strategic competition among countries already underway. In response to new issues brought about by technological development, countries and regions represented by the United States, the European Union, and Japan are improving fair use systems, allowing the unauthorized use of copyrighted works under specific circumstances, aiming to clear obstacles for artificial intelligence development.[19]In contrast, China lacks clear regulations regarding generative artificial intelligence training, and there is still controversy over whether data acquisition and training can fall within the scope of fair use, which somewhat limits the pace of generative artificial intelligence development in China.
2. Local Development of Incorporating Generative Artificial Intelligence Training into Fair Use
(1) Practical Needs: Dual Motivation of Technological Development and International Competition
1. Alleviating Algorithmic Discrimination and Value Bias in Generative Artificial Intelligence
GAI data acquisition and training have obvious efficiency-oriented and algorithmically opaque characteristics, directly affecting judgments regarding data sources and utilization methods. Influenced by the GAI network architecture model and the nature of capital seeking profit, designers and users prioritize efficiency, but are powerless to construct quantifiable rules beyond efficiency principles.[20]Moreover, the high specialization and complexity of artificial intelligence algorithms determine that the vast majority of society cannot understand their algorithmic logic, coupled with the fact that artificial intelligence algorithms possess a certain degree of autonomous learning ability, resulting in unpredictability in machine learning.
Furthermore, if the cost of licensing works for use is too high or there are no effective channels for acquisition, users will resort to low-risk but biased works data (Biased Low-friction Data), which will induce algorithmic bias.[21]Massive data acquisition entails high copyright licensing fees. When developers cannot afford the exorbitant licensing costs, they can only choose to abandon development or use works that have surpassed their protection period. Technologies developed on this basis may not be practically applicable. Due to the influence of underlying algorithm settings and architecture, algorithmic bias naturally exists. At this point, if the selection of training data also has biases, it can lead to biases being amplified in multiple rounds of data model training, affecting subsequent algorithmic decisions.
From a practical perspective, completely eliminating data bias is extremely challenging. The quality of basic data in the internet world is uneven, requiring GAI to completely eliminate discrimination and bias is akin to a fantasy. However, this does not mean that this issue should be ignored. By absorbing diverse data and expanding the scale of pre-training data, the aforementioned issues can be effectively alleviated.
2. Actively Promoting Knowledge Flow and Technological Innovation on an International Scale
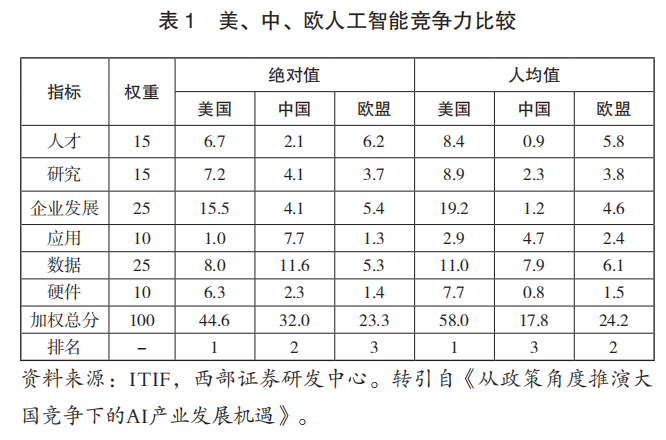
The development of artificial intelligence technology is supported by computing power, algorithms, and data, and the comparative advantages of these three elements influence the policy orientations of various countries. Specifically, countries with a comparative advantage in computing power usually adopt policy levers (such as export controls) to maintain their core competitiveness; countries with an advantage in algorithms typically take various measures to attract and retain talent to drive continuous updates and iterations of algorithms; while countries with a comparative advantage in data must focus on resolving derivative issues in data collection and use, leveraging market scale advantages to provide favorable conditions for the transformation of generative artificial intelligence outcomes.[22]As shown in Table 1, compared to the United States and the European Union, China does not have significant advantages in computing power and algorithms, but has a relative advantage in data. From an efficiency perspective, adopting fair use rules to allocate data resources is the path to maximizing public interest in reality. Therefore, China should timely improve the fair use provisions for generative artificial intelligence, creating a favorable environment for its development.
(2) Practical Challenges: Dual Obstacles of Closed Models and Interest Damage
1. Existing Fair Use Cannot Cover Generative Artificial Intelligence Training
The provisions on fair use in China’s Copyright Law adopt a closed legislative approach, listing 12 specific circumstances in Article 24, and GAI data acquisition and training do not fall within the statutory circumstances. If existing provisions are broadly interpreted, the most likely applicable clause would be Article 24(1) (personal learning use) or Article 24(6) (use for teaching or research purposes). However, the current GAI development entities are primarily commercial companies, and GAI data acquisition and training often have commercial characteristics, and are not individual activities, making it difficult to qualify as having “personal learning, research, or appreciation” purposes. Furthermore, even disregarding the subjectivity requirement, the acquisition and use of data is also hard to classify as “limited copying.” Moreover, the third amendment to China’s Copyright Law was completed in 2020, and the likelihood of a fourth amendment in the short term is low, meaning the fair use provisions will continue to maintain the “enumeration + fallback provisions” model, making it difficult for GAI data acquisition and training to be directly incorporated into existing types of fair use.
“Transformative use” can only solve part of the problem. Many courts have broadly interpreted “fair use” based on the clause of “appropriately citing others’ already published works for the purpose of introducing or commenting on a work or explaining an issue,” thereby applying “transformative use.” This indicates that China’s “transformative use” rule is grafted onto the statutory types of “fair use”.[23]Clearly, the use of copyrighted works by GAI does not meet this characteristic. Furthermore, not all AIGC adds new expressions based on copyrighted works, creating a distinction from the original copyrighted work’s new functions or values in terms of purpose or content. In other words, even if “transformative use” is applied, it cannot address all the issues arising from GAI data acquisition and training.
2. Incorporating Fair Use May Lead to Legal Interests Being Damaged
Generative artificial intelligence training may harm the interests of copyright holders in several ways: First, unauthorized use or abuse without the rights holder’s consent may lead to infringement. GAI can retrieve and obtain required works in a very short time and process them.[24]This process involves the disassembly and reorganization of works, which may trigger more complex infringement issues, severely threatening the rights of copyright holders. For example, three comic artists in the U.S. sued Stability AI and three other AIGC commercial application companies for using their images without the original authors’ consent, infringing on the rights of millions of artists.[25]Second, GAI training relies on deep learning processes, and if its learning behavior is incorporated into fair use, it means that authors and copyright holders will not receive benefits, and such uncompensated use will significantly harm the economic interests of authors and copyright holders. GAI development entities can obtain substantial commercial profits based on the use of copyrighted works, while copyright holders suffer losses due to AIGC’s encroachment on the original works’ transaction market.[26]Third, GAI gradually possesses the ability to imitate and even a certain degree of “creation” capability. Although AIGC may not qualify as works in the copyright sense, AIGC, as an emerging commodity, will still have a certain impact or even replace the works created by natural persons. For instance, the AI drawing software Mid Journey generated “Théâtre D’opéra Spatial,” which surpassed natural works to win first place in a digital art competition.[27]Once AIGC reaches the level of “indistinguishable from the real thing,” entering the transaction market will disrupt the existing balance of the market.
Applying fair use to generative artificial intelligence training will affect the interests of multiple parties. First, it involves authors and copyright holders. Incorporating this behavior into fair use means obtaining exemptions from copyright law; in other words, copyright holders cannot continue to maintain their rights through litigation but can only tacitly allow the existence of usage behaviors. This is also the main reason for copyright holders’ opposition. Second, incorporating generative artificial intelligence training into fair use may also affect the interests of data holders. Data, as a new factor of production, has become the focus of attention and contention among various parties, and platforms strongly hope to monopolize data. Existing cases show that data obtained through enterprise investment possesses attributes of intangible property.[28]Large enterprises, as vested interests, will also oppose incorporating GAI data acquisition and training into fair use. Finally, incorporating generative artificial intelligence training into fair use raises concerns about “machine creators’ superiority.” In other words, the fair use system intended to benefit society may be misused by large enterprises using artificial intelligence, thereby harming the interests of thousands of relatively weaker authors.[29]
Thus, the key issue lies in how copyright law should respond to the emergence of new technologies, achieving a balance between promoting technological development and protecting copyright holders’ interests, and constructing a fair use system that drives innovation. “While ensuring the interests of copyright holders, we cannot shackle science.”[30]On one hand, it is necessary to protect the competitive rights of enterprises, ensuring their legitimate business interests are not harmed by illegal “data scraping” behaviors; on the other hand, it is essential to guarantee the smooth acquisition and utilization of GAI data, avoiding excessive constraints that limit GAI’s development.
3. Rule Construction for Incorporating Generative Artificial Intelligence Training into Fair Use
(1) Path Selection: Constructing Fair Use Provisions for Generative Artificial Intelligence Based on a Fallback Clause
In the future, fair use provisions for generative artificial intelligence should be constructed based on existing fair use principles to adapt to the rapidly evolving reality of artificial intelligence technology. Overall, there are three paths to construct fair use principles suitable for GAI development needs: one is to borrow from the U.S. approach by broadening the scope of fair use through “transformative use.” However, as a codified law country, this may easily lead to conflicts in judicial rulings and even raise doubts about “judges making law.” Second, through broad interpretation and analogical interpretation, incorporate GAI data acquisition and training into the existing fair use scope. This approach also has obvious shortcomings, as previously analyzed. Third, add specialized provisions in legislative form to directly address the dilemma of applying fair use principles to GAI data acquisition and training, eliminating controversies faced by fair use in GAI and promoting objectivity and consistency in judicial rulings. Each of these three approaches has certain shortcomings or difficulties. Fortunately, the third amendment to the Copyright Law introduced a fallback clause—”other circumstances prescribed by laws and regulations,” which reserves space for establishing exceptions for text and data mining in China. Therefore, the most feasible solution is to use the fallback clause as an interface to introduce fair use provisions for generative artificial intelligence through the Implementation Regulations of the Copyright Law and refine relevant rules.
(2) Specific Rules: Refining Fair Use Provisions for Generative Artificial Intelligence
1. Subject Requirements: Expand to Any Entity That Can Legally Access Works
The subjects of use should not be limited to “research institutions” but should be expanded to include any entity that can legally access works (such as public cultural research institutions and market entities). At this point, it is essential to emphasize the legality of the acquisition method, requiring relevant subjects to “legally access” works and not circumvent relevant technological measures to illegally access works. Legal ways to acquire works include but are not limited to: obtaining based on subscription behavior, obtaining based on licensing agreements, obtaining based on works being provided online for free (except for rights holders making reservation statements), and obtaining based on national development needs or social public interest needs. For data and information obtained via the internet, a restrictive interpretation of the work’s legal source may be applied, requiring users to take measures such as citing sources.
2. Purpose Requirements: Use for Scientific Research or Promoting Knowledge Innovation
The purpose of use should not be limited to “non-commercial use” but should be defined as “use for scientific research or promoting knowledge innovation purposes.” Enterprises have a natural profit motive, and merely having a restriction for “non-commercial purposes” cannot prevent them from constructing training sets, which may damage the transparency of training sets and even create industry monopolies. In the future, attempts can be made to guide the use towards “scientific research purposes or promoting knowledge innovation purposes,” limiting secondary use to the initial market of works and reserving functions outside the initial market for society.[31]
When judging the purpose requirement, two issues should be noted. First, use in a commercial context does not equate to having a commercial purpose. The data acquisition and training of generative artificial intelligence do not inherently possess commercial purposes due to the enterprise’s nature, such as digital libraries and web search engines. Similarly, enterprises initially positioned as “non-profit organizations” may still engage in data acquisition and training that have “commercial purposes.” For example, OpenAI, the organization behind ChatGPT, was initially positioned as a non-profit but began transitioning to a profit-oriented organization in 2019, making its data mining and usage behaviors difficult to classify as “non-commercial use”.[32]Second, it is essential to distinguish whether the use in research contexts possesses the “research purpose.” In practice, most research institutions conduct research activities based on “non-commercial purposes,” but some research institutions may collaborate with enterprises to allow them to use their research results for material support, such as non-profit research institutions collaborating with profit-making enterprises to develop vaccines and other research activities conducted in a university-enterprise cooperation format. In this case, the specific method of use must be considered.
3. Action Requirements: Not Limited to Copying, but Excluding Distribution
The action requirements should not be limited to “copying” but must exclude “distribution.” From the perspective of actions, copying and extracting text data are fundamental steps in GAI data acquisition and training. When constructing fair use provisions for artificial intelligence, the action requirements should not be limited to “copying” but can include subsequent analysis and research actions, including electronic transcoding, compiling, extracting, parsing, analyzing, and reorganizing. At the same time, “distribution” actions should be strictly excluded. The purpose of GAI data acquisition and training is analysis and learning, ultimately outputting generated products. The copyright holders’ tolerance for individuals lies in allowing them to “learn, research, or appreciate”; similarly, for generative artificial intelligence, if the action requirements are expanded to information network dissemination, it would objectively create a “superhuman treatment”.
4. Safety Measures
The French Copyright Law requires that for technical copies made during text and data mining, they should be handled by specific institutions after the research is completed. Germany has similar provisions: “Once the research work is completed, subsequent copies of the source materials should be deleted, and the public should not have access.”[33]This practice is worth emulating. When constructing fair use provisions for artificial intelligence in China, safety measures can also be added to prevent leakage and dissemination of works.
(3) Supporting Measures: Improving Benefit Compensation Mechanisms and Work Exit Mechanisms
1. Benefit Compensation Mechanism Based on Copyrighted Work Utilization
There is no consensus on whether payment should be made for using others’ works in generative artificial intelligence training. Opposing opinions focus on two aspects: first, when natural persons learn relevant works, copyright holders do not have an expectation of charging fees. Generative artificial intelligence learning is an extension of natural person learning, and claiming fees based on copyright protection does not align with reasonable expectations. Second, during the training process of generative artificial intelligence, the contribution of individual authors is often negligible. Although high-frequency and large-scale data acquisition amplifies the appearance of infringement, whether the damage to individual subjects is severe enough remains debatable. Some scholars have pointed out that when “rights management information” can achieve low-cost statistics on the scope and frequency of work utilization, payment should replace fair use.[34]Allowing enterprises to conduct generative artificial intelligence training for profit is acceptable, but it is necessary to transform the requirements of fair use rules to replace “free trial” with “paid usage” and establish a copyright market based on “pay-per-use”.[35]This viewpoint is reasonable, but it is essential to clarify whether the copyright infringement involved in generative artificial intelligence training is based on copyright use or data rights compensation.
2. Work Exit Mechanism Based on Copyright Licensing
To avoid excessive infringement of copyright holders’ interests, the work exit mechanism can be improved, appropriately enhancing the bargaining power of copyright holders. The “work exit” should at least include two forms: first, when copyright holders upload their works to the internet, they should clearly state that they do not allow their works to be used for GAI training. In this case, development entities should respect the copyright holders’ statements and actively avoid using copyrighted works. Second, when copyright holders receive notifications or learn that their copyrighted works are being used through a public platform or copyright work retrieval channel set up by the development entity, they should be able to choose to retain, delete, or block their works within a specified time. If copyright holders do not make a clear refusal within the specified period, it is assumed that they allow GAI training based on copyrighted works; if copyright holders make a clear refusal within the specified period, the development entity should promptly delete or block the infringing content.
4. Conclusion
As Minsky said: Artificial intelligence is humanity’s “intelligent child” or “new offspring,” and we should view the development of artificial intelligence from a new perspective of alliance and create a better future for humanity. With the rapid development of generative artificial intelligence, new ways of using works will continuously emerge, making the principles of fair use under traditional copyright rules urgently need reform. For generative artificial intelligence, we should adhere to the attitude of “no restrictions on learning, but caution in expression” to promote the standardized development of generative artificial intelligence data acquisition and training. In the future, China should use the Implementation Regulations of the Copyright Law as an interface to introduce fair use provisions for generative artificial intelligence, clarifying the specific rules for incorporating generative artificial intelligence training into fair use principles. At the same time, attention should be paid to improving supporting systems, constructing benefit-sharing mechanisms, and work exit mechanisms to achieve a balance between promoting technological development and protecting copyright holders’ interests.
(Author Information: Guan Chunyan, PhD Student at the Intellectual Property Research Center of Zhongnan University of Economics and Law)
References
* This article is a phased research result of the major project of the National Social Science Fund “Research on the Modernization of Industrial Intellectual Property Risk Governance under the Overall National Security Concept” (Project No.: 21&ZD203) and the youth project of the National Social Science Fund “Research on Copyright Filtering Obligations of Network Service Providers in the Algorithm Era” (Project No.: 23CFX026).
[1] Wan Yong. The Dilemma and Solution of Fair Use System in Copyright Law in the Age of Artificial Intelligence [J]. Social Science Journal, 2021 (5): 94-96.
[2] Zhao Li. The Practice and Reference of Copyright Fair Use in Text and Data Mining Abroad [J]. Library, 2022 (3): 64-67.
[3] Wu Gao, Huang Xiaobin. Research on the Design of Fair Use Rules for Text and Data Mining in the Age of Artificial Intelligence [J]. Library and Information Work, 2021, 65 (22): 9-11.
[4] Jiao Heping. Copyright Risks and Solutions in Data Acquisition and Utilization in Artificial Intelligence Creation [J]. Contemporary Law, 2022, 36 (4): 129.
[5] See Williams & Wilkins Co. v. United States, 487 F.2d 1345 (Ct. Cl. 1973), aff’d by an equally divided Court, 420 U.S. 376 (1975).
[6] See Authors Guild, Inc. v. Google, Inc., 804 F.3d 202 (2d Cir. 2015).
[7] The court noted that in text and data mining services, Google’s copying of works and displaying parts of works serves as a scientific research tool for users, benefiting the public interest; moreover, Google did not directly place advertisements on the service webpage. Therefore, Google’s copying and display of works for text data mining analysis serves a “transformative” purpose, constituting fair use.
[8] See Authors Guild, Inc. v. HathiTrust, 755 F.3d 87 (2d Cir. 2014).
[9] Lin Xiuqin. The Restructuring of the Fair Use System in the Age of Artificial Intelligence [J]. Legal Studies, 2021, 43 (6): 184.
[10] See Council directive (EU) 2019/790 of 17 April 2019 on copyright and related rights in the digital single market and amending directives 96/9/EC and 2001/29/EC [2019] OJ L130/92.
[11] Tang Sihui. Research on Copyright Exceptions for Text and Data Mining in the Big Data Environment: A Perspective on the Proposal of the EU DSM Copyright Directive [J]. Intellectual Property, 2017 (10): 113.
[12] Zhang Huibin, Xiao Qixian. The Construction of Copyright Exemption Rules for Text and Data Mining in the Age of Artificial Intelligence [J]. Science and Technology and Law (Chinese and English), 2021 (6): 79.
[13] Si Xiao, Cao Jianfeng. Research on Big Data and Artificial Intelligence Issues in EU Copyright Law Reform [J]. Journal of Northwestern Polytechnical University (Social Sciences Edition), 2019 (3): 100.
[14] “Enjoyment” means accepting and appreciating highly emotional things or material interests, etc. Based on legislative intent and the definition of “enjoyment,” whether a behavior belongs to the behavior of “enjoying the thoughts or emotions expressed in works” should be judged from whether the behavior aims to satisfy the audience’s intellectual or emotional needs through watching or listening to works, etc. See Japan Copyright Office (n 30) 12.
[15] Article 30-4(iii) of the Copyright Law “allows uses that do not involve perceiving the expressions of such works through human senses”; the use in computer data processing falls under this category. See Japan Copyright Office (n 30) 11-12.
[16] UENO T O. The flexible copyright exception for “non-enjoyment” purposes—recent amendment in Japan and its implication [J]. GRUR International, 2021, 70 (2): 148.
[17] See Japan Copyright Office (n 30) 12 (footnote 8).
[18] Zheng Zhong. Japan’s Flexible Fair Use Provisions and Their Enlightenment [J]. Intellectual Property, 2022 (1): 118.
[19] Xu Xiaoben, Yang Yinan. On Fair Use of Copyright in Deep Learning of Artificial Intelligence [J]. Jiaotong University Law, 2019 (3): 33.
[20] Zheng Zhihang. The Ethical Crisis and Legal Regulation of Artificial Intelligence Algorithms [J]. Legal Science (Northwest University of Political Science and Law Journal), 2021, 39 (1): 16.
[21] LEVENDOWSKI A. How copyright law can fix artificial intelligence’s implicit bias problem [J]. Washington Law Review, 2018, 93 (2): 610.
[22] Luo Yamei. Deriving Opportunities for AI Industry Development under Great Power Competition from a Policy Perspective [EB/OL]. (2023-07-27) [2023-10-30]. https://baijiahao.baidu.com/s?id=1772552075987762218&wfr=spider&for=pc.
[23] Xiong Qi. The Local Legal Interpretation of Copyright Transformative Use [J]. Jurist, 2019 (2): 126.
[24] Ding Yinan, Lü Dongjuan, Wang Xiandi. Research on the Rights Protection of Content Generated by ChatGPT [J]. Media, 2023, (24): 95.
[25] The legal dispute over AI painting escalates: Huagai Creative and three artists sue Stability AI [EB/OL]. (2023-01-18) [2023-07-30]. https://baijiahao.baidu.com/s?id=1755353208599802189&wfr=spider&for=pc.
[26] See Andersen v. Stability AI Ltd., 700 F. Supp. 3d 853, 2023 U.S. Dist. LEXIS 194324, 2023 U.S.P.Q.2D (BNA) 1288.
[27] Chen Gelei. These AI-generated works have reached the level of artistic creation [EB/OL]. (2022-10-28) [2023-07-15]. http://www.ittime.com.cn/news/news_61222.shtml.
[28] See Shenzhen Intermediate People’s Court (2017) Yue 03 Min Chu 822 No. Civil Judgment.
[29] Zhang Jinping. The Dilemma of Fair Use of Artificial Intelligence Works and Its Resolution [J]. Global Legal Review, 2019, 41 (3): 120-132.
[30] See Cary v. Kearsley, 170 Eng. Rep. 679, 681, 4 Esp. 168, 170 (1802).
[31] Zhang Geng, Lin Nan. The Reconstruction and Localization of Transformative Use Standards under Normative Pathways [J]. Journal of Southwest Minzu University (Humanities and Social Sciences Edition), 2019, 40 (8): 108.
[32] Song Haiyan. Observations on the Regulation of Large Models: How the UK, US, and EU Regulate ChatGPT Training Data? [EB/OL]. (2023-05-08) [2023-07-15]. https://www.sohu.com/a/673866003_116132.
[33] CANELLOPOULOU-BOTTIS M, PAPADOPOULOS M, ZAMPAKOLAS C, et al. Text and data mining in the EU ‘acquis communautaire’ tinkering with TMD & digital legal deposit [J]. Erasmus Law Review, 2019, 12 (2): 197.
[34] BELL T W. Fared use: the impact of automated rights management on copyright’s fair use doctrine [J]. North Carolina Law Review, 1998, 76 (2): 579.
[35] Xiong Qi. On the Scope of Application of the Fair Use System [J]. Jurist, 2011 (1): 94.
Previous Issues Review
Zhu Henan and Wang Pengtao | Research on the Construction and Extension Path of Red Culture Space in Physical Bookstores
Zhang Baoming and Chen Zhenke | “Editor” and “Publication”: A Re-exploration of the Internal Operation Mechanism of “New Youth”
2022-2023 Annual Report on China’s Animation and Game Industry
Wu Shenlun | From Content to Demand: Research on the Empowerment of Interest E-commerce Models in Online Book Retailing
Sun Dehong and Zang Yongqing | Not Only “Going Out”, But Also “Going In”—A Dialogue on the International Dissemination of Chinese Literature Publishing
Wan Anlun and Wang Jinying | Publishing Studies: A New Interdisciplinary Integration of New Liberal Arts
Zhang Wenyan | The Lingering and Self-discipline of Reading: Books on Paper, Books in Pictures, Books in Mirrors, and Artificial Intelligence
Su Heng and Yan Sanjiu | Data Availability: The Logic of Production Factors in the Transformation and Development of the Digital Publishing Industry
Gao Xiaohong et al. | Constructing an Independent Knowledge System of Publishing Studies for Chinese-style Modernization


Editorial Office: 010-52257108
Subscription Hotline (Distribution Department): 010-5225 7109/7110
Online Submission: https://cbfx.cbpt.cnki.net/
Editorial Office Email: [email protected]
