Author: Wei Xiucan, PhD student at the Institute of Machine Learning and Data Mining (LAMDA), Nanjing University. He has published academic papers in top international journals and conferences, and his “Must Know Tips in Deep Neural Networks” was invited for publication in the well-known data mining forums KDnuggets and Data Science Central. Selected from “Programmer,” reprinted with permission from CSDN.
Computer Vision (CV) is a field that studies how to enable machines to “see.” In 1963, Larry Roberts from MIT published the first doctoral thesis in this field, titled “Machine Perception of Three-Dimensional Solids,” marking the beginning of CV as a new direction in artificial intelligence research. Over 50 years later, let’s discuss some interesting attempts that have recently given computer vision the ability to create something from nothing:
-
Image Super-Resolution;
-
Image Colorization;
-
Image Captioning;
-
Sketch Inversion;
-
Image Generation.
It can be seen that these five attempts are progressively layered, with increasing difficulty and interest. Due to space limitations, this article will only discuss visual problems without delving into overly specific technical details. If anyone is interested in a particular part, we can write a separate article for discussion later.
◆ ◆ ◆
Image Super-Resolution
Last summer, an application called “waifu 2x” gained significant popularity in animation and computer graphics. Waifu 2x utilizes deep Convolutional Neural Network (CNN) technology to double the resolution of images while also denoising them. In simple terms, it allows the computer to “create” additional pixels that were not present in the original image, making the comics appear clearer and more vivid. Take a look at Figure 1 and Figure 2; this is how high-definition Dragon Ball should have looked when we were kids!


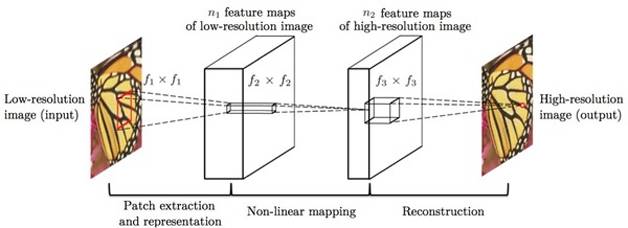
However, it should be noted that research on image super-resolution began around 2009, and it was only with the development of deep learning that waifu 2x could achieve better results. During the specific training of CNN, the input image is of original resolution, while the corresponding super-resolution image serves as the target, forming an “image pair” for training. After model training, a super-resolution reconstruction model can be obtained. The deep network prototype of waifu 2x is based on the results of Professor Tang Xiaou’s team at the Chinese University of Hong Kong (as shown in Figure 3). Interestingly, this research indicates that traditional methods can be used to provide qualitative explanations for deep models. In Figure 3, the low-resolution image undergoes convolution and pooling operations through CNN to obtain an abstract feature map. Based on the low-resolution feature map, non-linear mapping from low-resolution to high-resolution feature maps can also be achieved using convolution and pooling. The final step is to use the high-resolution feature map to reconstruct the high-resolution image. In fact, these three steps are consistent with the three processes of traditional super-resolution reconstruction methods.
◆ ◆ ◆
Image Colorization
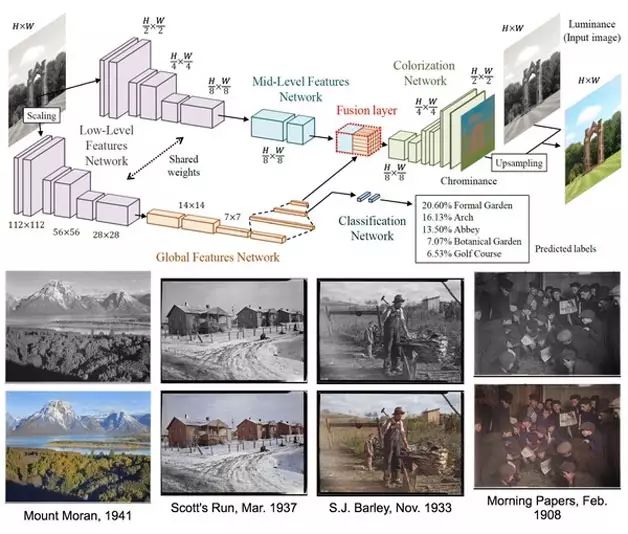
As the name suggests, image colorization involves filling in color for originally “colorless” black-and-white images. Image colorization also relies on convolutional neural networks, where the input consists of pairs of black-and-white and corresponding color images. However, simply contrasting black-and-white pixels with RGB pixels to determine the fill color yields subpar results. This is because the results of color filling must align with our cognitive habits; for example, painting a “dog’s fur” bright green would seem very odd. Recently, a work published by Waseda University at the top international conference SIGGRAPH in 2016 added a “classification network” to the original deep model to pre-determine the categories of objects in the image, using this as a basis for color filling. Figure 4 shows the model structure and color recovery examples, which are quite realistic. Additionally, such work can also be used for color recovery of black-and-white films, where the operation simply involves coloring frame by frame.
◆ ◆ ◆
Image Captioning
People often say “a picture is worth a thousand words,” where text serves as another way to describe the world besides images. Recently, a study called “Image Captioning” has gained traction, aiming to automatically generate human natural language descriptions for an image using computer vision and machine learning. Generally, in Image Captioning, CNN is used to extract image features, which are then input into a language model LSTM (a type of RNN) along with the image features, forming an end-to-end structure for joint training, ultimately outputting a language description of the image (as shown in Figure 5).
◆ ◆ ◆
Sketch Inversion
Just earlier in June, Dutch scientists published their latest research on arXiv, which involves “restoring” facial contour images through deep networks. As shown in Figure 6, during the model training phase, the real facial images are first processed using traditional offline edge detection methods to obtain the corresponding facial contour images, forming an “image pair” with the original image as input for deep network training, similar to super-resolution reconstruction. During the prediction phase, the input is the facial contour (second from the left, Sketch), which undergoes successive abstractions through the convolutional neural network and subsequent “restoration” operations to gradually restore a photo-like facial image (far right). Comparing it with the real facial image on the far left, it is convincingly realistic. The model flowchart also displays some restoration results, with the left column showing real faces, the middle column showing manually drawn facial contour images used as network input for restoration, and the right column showing the restoration results.

◆ ◆ ◆
Image Generation
Looking back at the previous four works, they all rely on some “material” to create something from nothing; for instance, “sketch inversion” still requires a contour drawing to restore the portrait. The next work can generate an image that closely resembles a real scene from any random vector.
“Unsupervised learning” can be considered the Holy Grail in the field of computer vision. A groundbreaking work in this direction is the “Generative Adversarial Networks” (GAN) proposed by Ian Goodfellow and Yoshua Bengio. The inspiration for this work comes from zero-sum games in game theory. In a binary zero-sum game, the sum of the interests of the two players is zero or a constant; if one party gains, the other must lose. In GAN, the two players are represented by a “discriminative network” and a “generative network,” as shown in Figure 7.
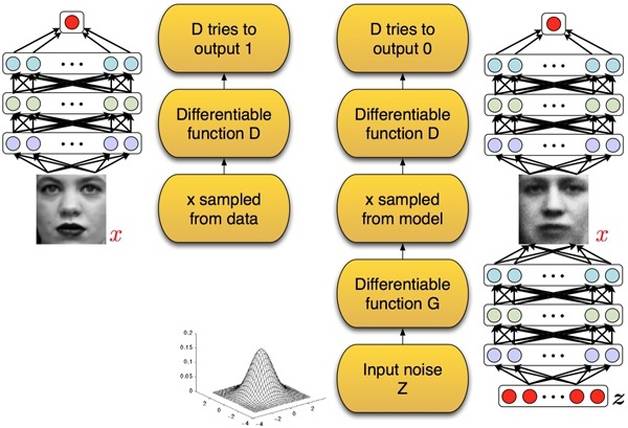
In this setup, the input to the “discriminative network” is an image, and its role is to determine whether an image is real or generated by a computer; the input to the “generative network” is a random vector, which can be used to “generate” a synthetic image. This synthetic image can also serve as input to the “discriminative network,” ideally being recognized as generated by a computer.
Next, the zero-sum game in GAN occurs between the “discriminative network” and the “generative network”: the “generative network” tries to make its generated images approach real images to “fool” the “discriminative network”; meanwhile, the “discriminative network” remains vigilant to prevent the “generative network” from succeeding… This back-and-forth continues iteratively, resembling a “mutual combat” scenario. The ultimate goal of the GAN process is to learn a “generative network” that can approximate the distribution of real data, thereby mastering the overall distribution of real data, hence the name “Generative Adversarial Network.” It is important to emphasize that GAN no longer requires a massive amount of labeled images like traditional supervised deep learning; it can be trained without any image labels, thus performing deep learning under unsupervised conditions. In early 2016, based on GAN, Indico Research and Facebook AI Research implemented GAN using deep convolutional neural networks (called DCGAN, Deep Convolutional GAN), with work published at the important international conference ICLR 2016, achieving the best results at that time in unsupervised deep learning models. Figure 8 shows some bedroom images generated by DCGAN.

Interestingly, DCGAN can also support image “semantic” addition and subtraction similar to word2vec (as shown in Figure 9).

Additionally, recently, the renowned professor Song-Chun Zhu’s team from UCLA published their latest work based on generative convolutional networks called STGConvNet: it can not only automatically synthesize dynamic textures but also synthesize sounds, marking a significant advancement in unsupervised computer vision.
◆ ◆ ◆
Conclusion
Today, riding the wave of “deep learning,” the performance of most tasks in computer vision has been significantly improved, even enabling tasks like “portrait restoration” and “image generation” to achieve a quality reminiscent of “creating something from nothing,” which is truly exciting. However, despite this, we are still quite far from the so-called AI “singularity” that could revolutionize humanity, and it is foreseeable that, at this stage and for a considerable time to come, computer vision or artificial intelligence will not be able to truly achieve “creating something from nothing”—that is, possessing “self-awareness.”
Nevertheless, we are fortunate to witness and experience this revolutionary wave in computer vision and artificial intelligence, and I believe many more “miracles of creating something from nothing” will occur in the future. Standing at the crest of the wave, I am thrilled and sleepless.
◆ ◆ ◆
Check out previous exciting articles; click the image to read.
[Heavyweight] Chinese version of the video is online | Stanford CS231n Deep Learning and Computer Vision – 1

The complete video of the Stanford CS231n course will be released on the NetEase Cloud Classroom Big Data Digest channel, with updates every Tuesday morning. Please click the “Read the original” link at the bottom left to follow updates. Reply “Stanford” in the Big Data Digest backend to download the original PPT of this course.