

Introduction
In the previous article, we introduced the concept of Agentic RAG, emphasizing how it extends traditional retrieval-augmented generation (RAG) frameworks by integrating autonomous agent capabilities. In this issue, we delve deeper into LangGraph, an innovative framework for coordinating logical workflows. LangGraph enables the creation of multi-agent systems with complex reasoning capabilities, making it an ideal tool for building Agentic RAG architectures.
Why Choose LangGraph for Agentic RAG?
LangGraph provides a powerful environment for creating stateful workflows where agents can intelligently interact between nodes, tools, and tasks. Its compatibility with LangChain and other advanced AI frameworks enables seamless integration with retrieval and generation pipelines, making it highly suitable for the dynamic demands of Agentic RAG.
Main Advantages:
-
1. Workflow Orchestration: Define and manage multi-step workflows with conditional logic and state management. -
2. Tool Integration: Easily integrate external tools, APIs, and retrieval systems. -
3. Scalability: Handle complex multi-agent workflows with minimal overhead. -
4. Flexibility: Design workflows that can dynamically adapt to context and input.
LangGraph Architecture for Agentic RAG
A typical LangGraph workflow for Agentic RAG may include components for query rewriting, document retrieval, relevance scoring, and response generation.
Flowchart: LangGraph Workflow in Agentic RAG
[Start Query]
|
v
[Agent Node: Rewrite or Process Query]
|
+--> [Retrieve Documents: Knowledge Sources]
|
+--> [Grade Relevance]
|
+--> [Generate Response]
|
v
[End]-
• Start Query: Receives the user-input query. -
• Agent Node: Determines the next step based on context and conditions. -
• Retrieve Documents: Retrieves relevant documents from the knowledge base. -
• Grade Relevance: Scores documents to assess their relevance to the query context. -
• Generate Response: Generates the final output using the retrieved and processed data.
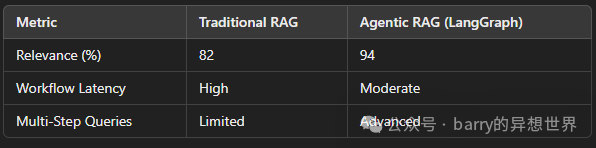
Benchmarking LangGraph with Agentic RAG
Experimental Setup
-
• Dataset: A mix of research papers, articles, and FAQs. -
• Evaluation Metrics: Relevance, accuracy, response time, and workflow efficiency. -
• Benchmark: Traditional RAG vs. Agentic RAG using LangGraph.
Results:
Code Explanation:
The code defines a Document Q&A Assistant that allows users to upload PDF files, provide URLs, or both, and then ask questions about the content of these documents. It leverages the LangChain framework, LangGraph, and Ollama API for embeddings and chat-based responses. The assistant is built using the Gradio library, providing an easy-to-use interface for interacting with the system.
Code Breakdown:
1. Imports
The code first imports the necessary modules:
-
• LangChain and LangGraph: For document loading, vector store creation, embeddings, message handling, and graph-based workflows. -
• Gradio: For building a user-friendly interface. -
• Pydantic: For defining and validating data structures. -
• Validators: For checking the validity of URLs. -
• Tempfile: For creating temporary files to handle PDF uploads.
from langchain_community.document_loaders import WebBaseLoader, PyPDFLoader
from langchain_community.vectorstores import Chroma
from langchain_ollama import OllamaEmbeddings, ChatOllama
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain.tools.retriever import create_retriever_tool
from typing import Annotated, Sequence, Literal
from typing_extensions import TypedDict
from langchain_core.messages import BaseMessage, HumanMessage
from langgraph.graph.message import add_messages
from langchain import hub
from langchain_core.prompts import PromptTemplate
from langchain_core.output_parsers import StrOutputParser
from langgraph.graph import END, StateGraph, START
from langgraph.prebuilt import ToolNode, tools_condition
from pydantic import BaseModel, Field
import gradio as gr
import tempfile
import validators
from io import StringIO2. Data Structure
-
• AgentState: A <span>TypedDict</span>for tracking the state of the agent, particularly a series of messages. This is used to maintain the conversation context during interactions.
class AgentState(TypedDict):
messages: Annotated[Sequence[BaseMessage], add_messages]3. Processing Sources
-
• <span>process_sources(urls=None, pdf_files=None)</span>: -
• Accepts URLs and/or PDF files as input. -
• For URLs: -
• Validates the format. -
• Uses <span>WebBaseLoader</span>to load documents from the web. -
• For PDFs: -
• Temporarily saves the uploaded files. -
• Uses <span>PyPDFLoader</span>to parse PDFs into documents. -
• Returns a list of processed documents.
def process_sources(urls=None, pdf_files=None):
"""Process both URLs and PDF files"""
docs_list = []
# Handle URLs
if urls and urls.strip():
url_list = [url.strip() for url in urls.split(",")]
for url in url_list:
if validators.url(url):
try:
url_docs = WebBaseLoader(url).load()
docs_list.extend(url_docs)
except Exception as e:
print(f"Error loading URL {url}: {e}")
# Handle PDFs
if pdf_files:
for pdf in pdf_files:
try:
with tempfile.NamedTemporaryFile(delete=False, suffix='.pdf') as tmp:
tmp.write(pdf.read())
loader = PyPDFLoader(tmp.name)
docs_list.extend(loader.load())
except Exception as e:
print(f"Error loading PDF: {e}")4. Grading Document Relevance
-
• <span>grade_documents(state)</span>: -
• Determines whether documents are relevant to the user’s query. -
• Uses <span>ChatOllama</span>and specific prompts to score documents as<span>yes</span>or<span>no</span>. -
• The prompt asks the model to evaluate if the document’s content aligns with the user’s question.
def grade_documents(state) -> Literal["generate", "rewrite"]:
print("---CHECK RELEVANCE---")
class grade(BaseModel):
binary_score: str = Field(description="Relevance score 'yes' or 'no'")
model = ChatOllama(temperature=0, model="llama3.2", streaming=True)
llm_with_tool = model.with_structured_output(grade)
prompt = PromptTemplate(
template="""You are a grader assessing relevance of a retrieved document to a user question.
Document: {context}
Question: {question}
If the document contains keyword(s) or semantic meaning related to the user question, grade it as relevant.
Give a binary score 'yes' or 'no' score to indicate whether the document is relevant to the question.""",
input_variables=["context", "question"],
)
chain = prompt | llm_with_tool
messages = state["messages"]
question = messages[0].content
docs = messages[-1].content
scored_result = chain.invoke({"question": question, "context": docs})
return "generate" if scored_result.binary_score == "yes" else "rewrite"5. Core Agent Functions:
<span>agent(state)</span>:
-
• Processes general queries by calling the agent’s LLM capabilities with the provided tools.
def agent(state):
print("---CALL AGENT---")
messages = state["messages"]
model = ChatOllama(temperature=0, streaming=True, model="llama3.2")
model = model.bind_tools(tools)
response = model.invoke(messages)
return {"messages": [response]}<span>rewrite(state)</span>:
-
• Reformulates the user’s query using semantic reasoning to improve accuracy.
def rewrite(state):
print("---TRANSFORM QUERY---")
messages = state["messages"]
question = messages[0].content
msg = [HumanMessage(content=f"""
Look at the input and try to reason about the underlying semantic intent / meaning.
Initial question: {question}
Formulate an improved question:""")]
model = ChatOllama(temperature=0, model="llama3.2", streaming=True)
response = model.invoke(msg)
return {"messages": [response]}<span>generate(state)</span>:
-
• Answers user queries using relevant document content through pre-built RAG (retrieval-augmented generation) prompts.
def generate(state):
print("---GENERATE---")
messages = state["messages"]
question = messages[0].content
docs = messages[-1].content
prompt = hub.pull("rlm/rag-prompt")
llm = ChatOllama(temperature=0, streaming=True, model="llama3.2")
rag_chain = prompt | llm | StrOutputParser()
response = rag_chain.invoke({"context": docs, "question": question})
return {"messages": [HumanMessage(content=response)]}6. Query Processing Workflow
<span>process_query(urls, pdf_files, query)</span>:
-
• First, processes the provided URLs and PDFs into a list of documents. -
• Uses <span>RecursiveCharacterTextSplitter</span>to split these documents into smaller chunks. -
• Uses <span>OllamaEmbeddings</span>to embed these chunks and stores them in Chroma vector store. -
• Creates a retrieval tool to search within the vector store. -
• Defines a LangGraph-based workflow with nodes: -
• <span>agent</span>: Manages the dialogue flow. -
• <span>retrieve</span>: Searches for relevant documents. -
• <span>rewrite</span>: Reformulates the query. -
• <span>generate</span>: Generates the final answer. -
• Workflow edges define the transitions between these nodes based on conditions. -
• Executes the graph to provide a response to the user for their query.
def process_query(urls, pdf_files, query):
docs_list = process_sources(urls, pdf_files)
if not docs_list:
return "No valid documents provided. Please input URLs or upload PDFs."
text_splitter = RecursiveCharacterTextSplitter(chunk_size=100, chunk_overlap=50)
doc_splits = text_splitter.split_documents(docs_list)
vectorstore = Chroma.from_documents(
documents=doc_splits,
collection_name="rag-chroma",
embedding=OllamaEmbeddings(model="nomic-embed-text"),
)
retriever = vectorstore.as_retriever()
global tools
tools = [create_retriever_tool(
retriever,
"retrieve_documents",
"Search and return information from the provided documents."
)]
workflow = StateGraph(AgentState)
workflow.add_node("agent", agent)
workflow.add_node("retrieve", ToolNode(tools))
workflow.add_node("rewrite", rewrite)
workflow.add_node("generate", generate)
workflow.add_edge(START, "agent")
workflow.add_conditional_edges(
"agent",
tools_condition,
{"tools": "retrieve", END: END},
)
workflow.add_conditional_edges(
"retrieve",
grade_documents,
{"generate": "generate", "rewrite": "rewrite"},
)
workflow.add_edge("generate", END)
workflow.add_edge("rewrite", "agent")
graph = workflow.compile()
inputs = {"messages": [HumanMessage(content=query)]}
response = ""
for output in graph.stream(inputs):
for key, value in output.items():
if value.get("messages"):
response = value["messages"][-1].content
return response7. Gradio Interface
<span>create_interface()</span>:
-
• Builds a Gradio interface with two tabs:
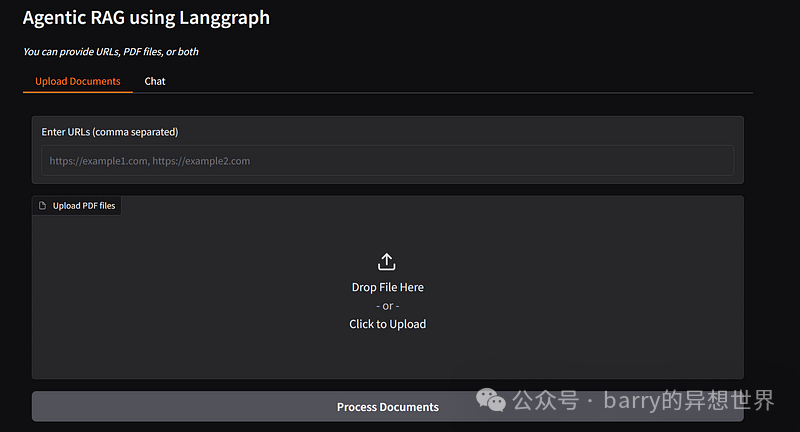
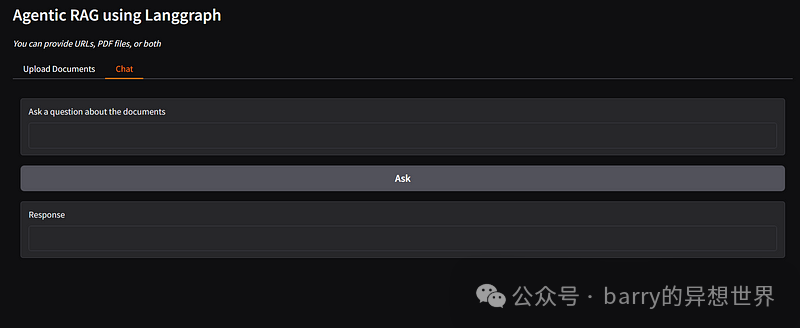
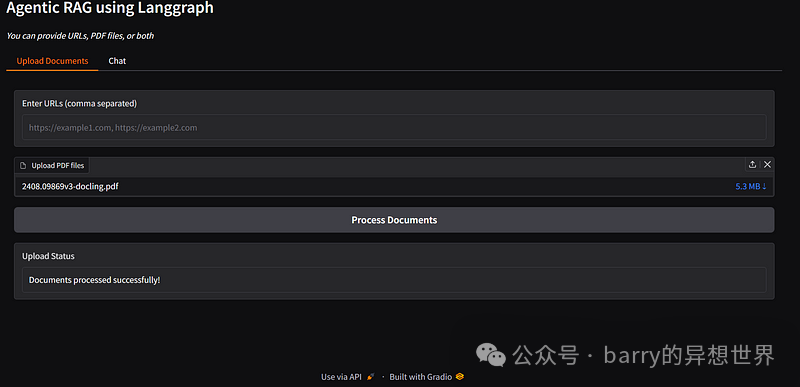
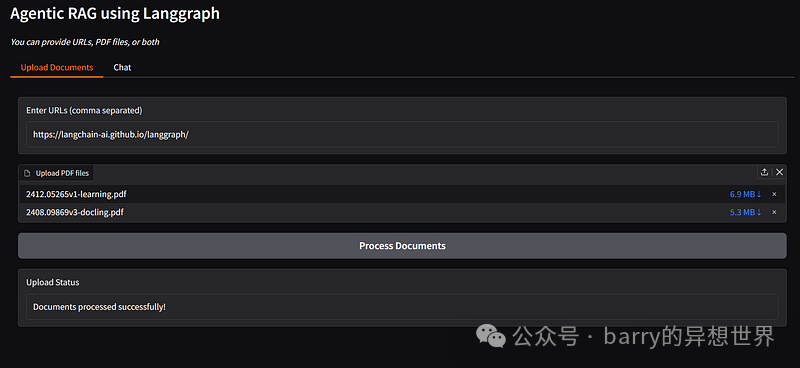
Upload Documents:
-
• A textbox for entering URLs. -
• A file uploader for uploading PDFs. -
• A button to process the documents. -
• A status box to display the processing result.
Chat:
-
• A textbox for user queries. -
• A button to initiate the query. -
• A textbox to display the response.
def create_interface():
with gr.Blocks(title="Document Q&A Assistant") as interface:
gr.Markdown("# Document Q&A Assistant")
gr.Markdown("*You can provide URLs, PDF files, or both*")
with gr.Tab("Upload Documents"):
urls = gr.Textbox(label="Enter URLs (comma separated)", placeholder="https://example1.com, https://example2.com")
pdfs = gr.File(file_count="multiple", label="Upload PDF files", file_types=[".pdf"])
upload_btn = gr.Button("Process Documents")
upload_status = gr.Textbox(label="Upload Status")
def handle_upload(urls, pdfs):
if not urls and not pdfs:
return "Please provide either URLs, PDF files, or both"
docs = process_sources(urls, pdfs)
if docs:
return "Documents processed successfully!"
return "No valid documents provided. Please input valid URLs or PDF files"
upload_btn.click(
fn=handle_upload,
inputs=[urls, pdfs],
outputs=upload_status
)
with gr.Tab("Chat"):
query = gr.Textbox(label="Ask a question about the documents")
chat_btn = gr.Button("Ask")
response = gr.Textbox(label="Response")
chat_btn.click(
fn=process_query,
inputs=[urls, pdfs, query],
outputs=response
)
return interface8. Application Launch
-
• When the script is executed, the Gradio interface is launched.
interface = create_interface()
if __name__ == "__main__":
interface.launch()Key Features Overview:
Multi-modal Document Support:
-
• Supports both URLs and PDFs simultaneously.
Relevance Scoring:
-
• Ensures responses are based on the most relevant documents.
Workflow Graph:
-
• Utilizes <span>StateGraph</span>to dynamically determine actions (e.g., rewrite, retrieve, generate).
Embedding and Vector Search:
-
• Uses <span>OllamaEmbeddings</span>and Chroma vector store for efficient document retrieval.
Interactive User Interface:
-
• Provides an accessible no-code interface using Gradio.
Conclusion
LangGraph is a key tool in advancing Agentic RAG, enabling dynamic multi-agent workflows to adapt to complex scenarios. Its seamless integration with tools like LangChain, Chroma, and ChatOllama ensures developers can efficiently build scalable and intelligent retrieval-augmented systems.
