
Recently, Alibaba algorithm expert Kun Cheng participated in the ICASSP 2017 conference with the paper titled Improving Latency-Controlled BLSTM Acoustic Models for Online Speech Recognition.

Author Kun Cheng communicating with attendees
The research of this paper is based on the premise that to achieve better speech recognition accuracy, the Latency-controlled BLSTM model was used in acoustic model building.
See also 95188: The first industrial application of BLSTM-DNN hybrid speech recognition acoustic model
https://yq.aliyun.com/articles/2308?spm=5176.100240.searchblog.7.zWq29M
Unlike standard BLSTM, which uses full sentences for training and decoding, Latency Control BLSTM uses an update method similar to truncated BPTT and has its own characteristics in handling intermediate states in cells and data usage, as shown in the figure below:
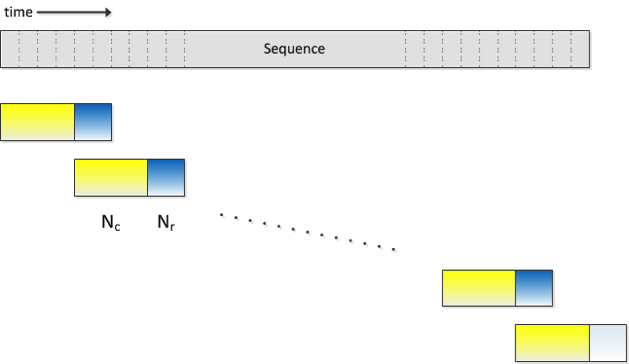
During training, a small segment of data is used for updates each time, consisting of a central chunk and a rightward additional chunk, where the rightward additional chunk is only used for calculating the intermediate state of the cell, and errors are propagated only in the central chunk. The network moves forward on the time axis, where the intermediate state of the cell at the end of the previous data segment is used as the initial state for the next data segment. In the reverse direction on the time axis, the intermediate state of the cell is reset to 0 at the start of each data segment. This method can significantly accelerate the convergence speed of the network and help achieve better performance. The data processing during decoding is essentially the same as during training, except that the dimensions of the central chunk and rightward additional chunk can be adjusted as needed and do not have to match the training configuration. The advantage of LC-BLSTM is that it can maintain the recognition accuracy of the BLSTM acoustic model with acceptable decoding latency, making the BLSTM applicable for online speech recognition services.
The aforementioned advantage of LC-BLSTM comes at the cost of increased computational load. To achieve better recognition accuracy, a longer rightward additional chunk is usually required during decoding, which increases the consumption of computational resources and raises costs. As shown in the figure below, the rightward additional chunk is also computed using BLSTM, and with Nc=30, Nr=30, the computational load will be twice that of traditional BLSTM.
The main contribution of this paper is the proposal of two improved LC-BLSTM models, which can reduce the computational load during decoding while maintaining recognition accuracy. This can lower computational costs, allowing a single server to support 1.5 to 2 times the original concurrency.
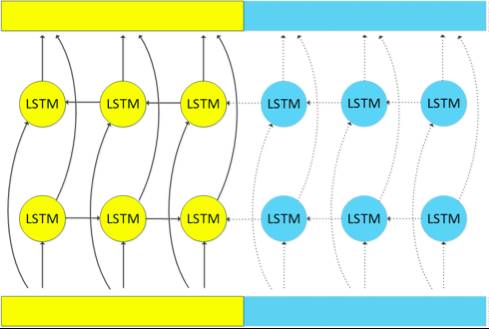
The first improvement method we proposed is illustrated in the figure below, with the main improvement focusing on the computation of the rightward chunk.
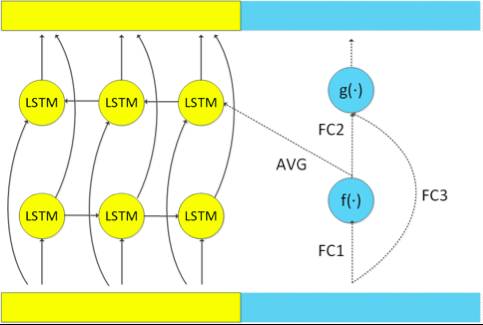
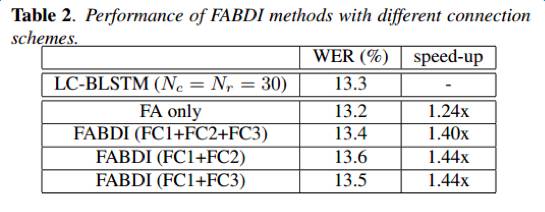
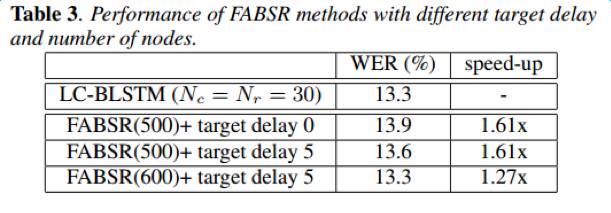
For the LSTM moving forward on the time axis, we removed the computation of the rightward chunk. For the LSTM moving backward on the time axis, the computation of the rightward chunk mainly provides the initial state of the center chunk. We simplified this computation by using forward fully connected layers instead of LSTM, taking the average of the outputs of f() as the initial state of the center chunk. These improvements significantly reduce the computational load of the model, and experimental results on the Switchboard dataset are shown in the table below, demonstrating a decoding speed increase of over 40% while maintaining recognition accuracy.
We proposed the second improvement method as shown in the figure below. For the LSTM moving forward on the time axis, we similarly removed the computation of the rightward chunk.
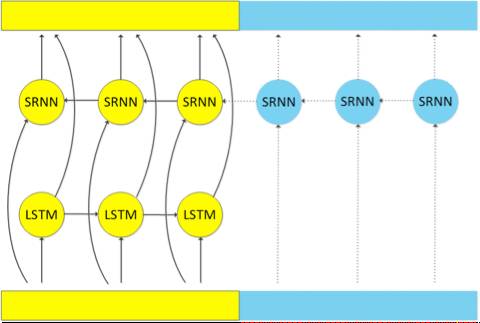
Additionally, we found that for the BLSTM model, the LSTM moving backward on the time axis is less important than the LSTM moving forward on the time axis. Therefore, we used a simple RNN model to replace the LSTM moving backward on the time axis. The computational load of the simple RNN model is much smaller than that of LSTM; thus, after this improvement, the model’s computational speed will also be significantly accelerated. Experimental results on Switchboard indicate that with a slight loss in recognition rate, decoding speed can be increased by over 60%.
Download the full paper for free: http://download.taobaocdn.com/freedom/42562/pdf/p1bbah8vsqfhef711bcs1jqt14k54.pdf
The 2017 Yunqi Conference is now open for registration!
On March 29, 2017, the Yunqi Conference will be held in Shenzhen. According to the official website of the conference, the application of cloud computing and artificial intelligence technologies in healthcare and manufacturing has become a focal point of the conference. Alibaba Cloud President Hu Xiaoming, Intel Executive Vice President Barbara Whye, and Alibaba Cloud Chief Scientist Zhou Jingren will deliver keynote speeches.
The conference website indicates that this year’s theme is “Feitian • Intelligence,” featuring a 2-day ecological exhibition, nearly 40 technical and industry forums, and over 100 sharing guests. The main forum will focus on the topic of “Intelligence.” It is understood that “Feitian” is a large-scale computing operating system independently developed in China, currently providing computing services for more than 200 countries and regions worldwide.
Currently, there is still a chance to obtain a free experience of globally leading gene testing products by registering for the conference.
Click the “Read Original” at the end of the article to register.

Recommended Reading
Click the image below to read

After NASA’s plan, Alibaba revealed its layout in the field of reinforcement learning

[Useful Content] Basic Machine Learning Algorithms

The tool for large-scale team collaborative development: Alibaba Atlas is officially open source!

Long press to recognize the imageQR code ▲ to follow “Alibaba Technology” to not miss any cutting-edge technical content.