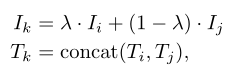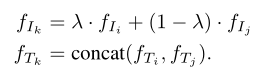Follow our public account to discover the beauty of CV technology
This article shares the paper「MixGen: A New Multi-Modal Data Augmentation」, how to perform data augmentation on multi-modal data? The Amazon Li Mu team proposed a simple and effective MixGen, significantly improving performance across multiple multi-modal tasks!
Details are as follows:

Abstract
Data augmentation is a necessary condition to improve data efficiency in deep learning. For visual-language pre-training, data augmentation has only been performed on images or text in previous works. In this paper, the authors proposeMixGen: a joint data augmentation for visual-language representation learning to further improve data efficiency. It generates new image-text pairs with semantic relationships by inserting images and concatenating texts. It is simple and can be plug-and-play into existing pipelines.
The authors evaluate MixGen on four architectures, including CLIP, ViLT, ALBEF, and TCL, across five downstream visual-language tasks to demonstrate its versatility and effectiveness. For example, adding MixGen during ALBEF pre-training leads to absolute performance improvements in downstream tasks: image-text retrieval (COCO fine-tuning +6.2% and Flicker30K Zero-shot +5.3%), visual grounding (+0.9% RefCOCO+), visual reasoning (+0.9% on NLVR2), visual question answering (+0.3% on VQA2.0), and visual entailment (+0.4% on SNLI-VE).
Motivation
In recent years, there has been an explosive growth in research on visual-language representation learning. In joint modality learning, models extract rich information across modalities to learn better latent representations. However, these models typically train on thousands of GPUs with a large number of image-text pairs.
For instance, CLIP achieves ResNet-50 accuracy on ImageNet with zero-shot, but it was trained for 12 days on 400M image-text pairs using 256 V100 GPUs. Furthermore, most of these large-scale datasets are not publicly accessible. Even when they are available, replicating and further improving existing methods is challenging for researchers with limited computational resources.
Data augmentation is widely used in deep learning to improve data efficiency and provide clear regularization during model training in computer vision (CV) and natural language processing (NLP). However, applying existing data augmentation techniques to visual-language learning is not straightforward. In image-text pairs, both images and texts contain rich information that matches each other.
Intuitively, we hope that their semantics still match after data augmentation. For example, consider an image with the paired sentence ‘A white dog is playing in the right corner of a green lawn’. Applying data augmentation techniques like cropping, color changes, and flipping to this image may require simultaneously changing the color and positional words in its paired sentence.
To preserve semantic relationships, previous works have performed mild data augmentation on either the visual or textual modality. ViLT and subsequent works use RandAugment for image augmentation without color inversion. CLIP and ALIGN only use random resized cropping without other image augmentations. On the linguistic side, most literature leaves text data augmentation to be handled by masked language modeling. There are also works using collaborative augmentation, but they are designed only for specific downstream tasks rather than general visual-language pre-training.
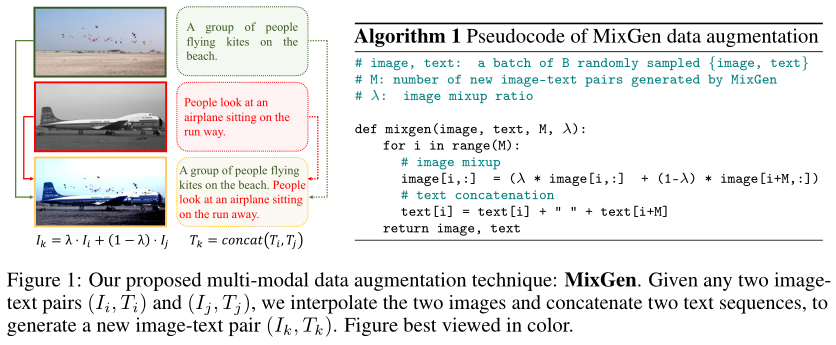
In this work, the authors propose a multi-modal joint data augmentation method for pre-training: MixGen. As shown in the above figure, MixGen generates new training samples by linearly interpolating images and concatenating text sequences from two existing image-text pairs.
It can be seen that most object and scene layouts are preserved in the mixed image, while the textual information is completely retained. In most cases, the semantic relationships within the newly generated image-text pairs are matched. Therefore, augmented data can be used to improve model training.
Despite its simplicity, using MixGen on top of strong baselines (e.g., ALBEF) consistently improves state-of-the-art performance across five downstream visual-language tasks: image-text retrieval (COCO fine-tuning +6.2% and Flicker30K Zero-Shot +5.3%), visual grounding (+0.9% on RefCOCO+), visual reasoning (+0.9% on NLVR2), visual question answering (+0.3% on VQA2.0), and visual entailment (+0.4% on SNLI-VE).
MixGen also enhances data efficiency; for example, during pre-training with 1M/2M/3M samples, the performance of ALBEF using MixGen matches that of ALBEF pre-trained on 2M/3M/4M samples. Additionally, the authors conducted extensive ablation studies to understand the impact of various design choices in MixGen. Finally, with just a few lines of code, MixGen can be integrated into most methods.
In terms of fine-tuning image-text retrieval on COCO, MixGen brings absolute improvements to four popular and diverse architectures: ViLT (+17.2%), CLIP (+4.1%), ALBEF (+7.0%), and TCL (+3.2%).
Method
The authors propose a multi-modal joint data augmentation technique: MixGen. Assume there is a dataset containing N image-text pairs, where images and texts are denoted by subscripts I and T, respectively. Given two image-text pairs, a new training sample is obtained as follows:
where λ is a hyperparameter between 0 and 1, representing the linear interpolation between the original pixels of two images; the concat operator directly concatenates the two text sequences to best retain the original information. Thus, the semantic relationships within the newly generated image-text pairs remain valid in most scenarios, as shown in the above figure. This random combination of image-text samples also increases the diversity of model training, leading to the provision of rare concepts.
Given a mini-batch of B randomly sampled image-text pairs, MixGen replaces the first M training samples with new generated samples. Thus, the mini-batch size, total training iterations, and total training pipeline remain unchanged. By default, the authors set and in the algorithm. This plug-and-play technique can be easily integrated into most visual-language representation learning methods and tasks: it requires just a few lines of code with minimal computational overhead.
3.1. MixGen variants
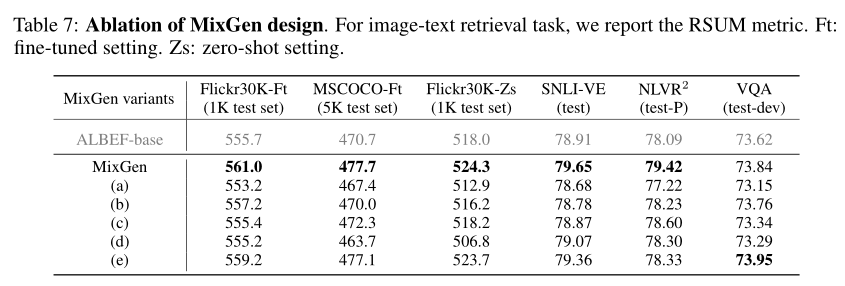
MixGen is very simple in form. However, depending on how image and text augmentations are executed, there may be multiple variants. Theoretically, other augmentations could be applied to images beyond mixing, as well as other text augmentations beyond concatenation, but the design space would be tricky. Therefore, the authors focus on mixing for images and concatenating for texts, selecting five most direct MixGen variants to support the final design choices in this paper.
Since the default MixGen adopts a fixed λ, the authors introduce variant (a) with λ ∼ Beta(0.1, 0.1), following the original mixup of sampling λ from the Beta distribution. To demonstrate the benefits of executing joint image-text augmentation, the authors propose variants (b) and (c). Specifically, variant (b) mixes two images while uniformly selecting one text sequence, and variant (c) concatenates two text sequences while uniformly selecting one image. Finally, the authors investigate whether to use a subset of tokens instead of concatenating all tokens from two text sequences.
Variant (d) obtains tokens from two text sequences proportionally based on λ similar to mixing with images, and then concatenates. Another variant (e) first concatenates all tokens but randomly retains half to generate a new text sequence.
In the table above, more detailed definitions of these five variants can be seen. The authors also conducted extensive ablation studies on them. As shown in the following table, the default MixGen achieves the overall best performance and consistently outperforms other variants across four different visual-language downstream tasks.
3.2. Input-level and embedding-level MixGen
Another design perspective is where to apply data augmentation. The above formula operates directly on the original inputs, such as images and text sequences. Alternatively, the ideas of MixGen can be applied at the embedding level. Specifically, interpolating image features extracted from the image encoder, instead of interpolating the original image pixels.
Similarly, concatenating two sequence features extracted from the text encoder, instead of concatenating two text sequences. Representing training pairs about embeddings as and, the newly generated training pairs in embedding form are:
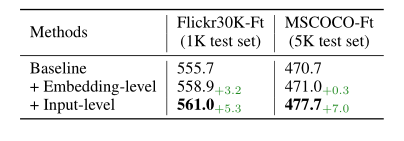
MixGen executed on the original inputs is called input-level MixGen, while that executed at the embedding level is called embedding-level MixGen. As shown in the table below, input-level MixGen consistently performs better than embedding-level MixGen. Additionally, input-level MixGen has the advantage of being easy to implement, as it does not require modifications to the network architecture or changes to the model’s forward.
Experiments
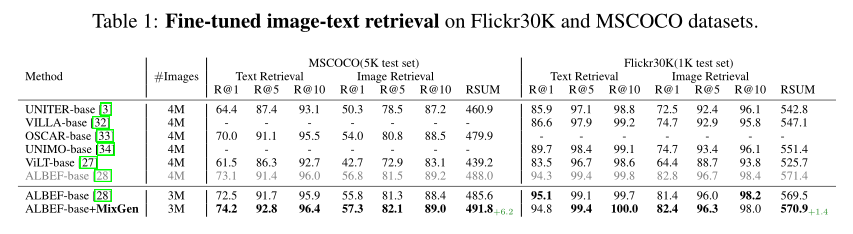
For the fine-tuning results in the table above, it can be seen that MixGen consistently outperforms the ALBEF baseline on both datasets. In the 3M setting, simply adding MixGen without any modifications leads to a 6.2% increase in the RSUM score for COCO and a 1.4% increase for Flicker30K.
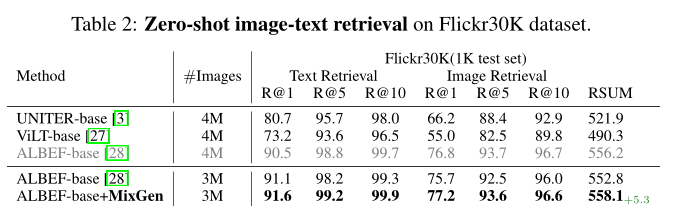
For the zero-shot results in the table above, similar conclusions can be observed. In the 3M setting, MixGen results in a 5.3% increase in the RSUM score on Flicker30K.
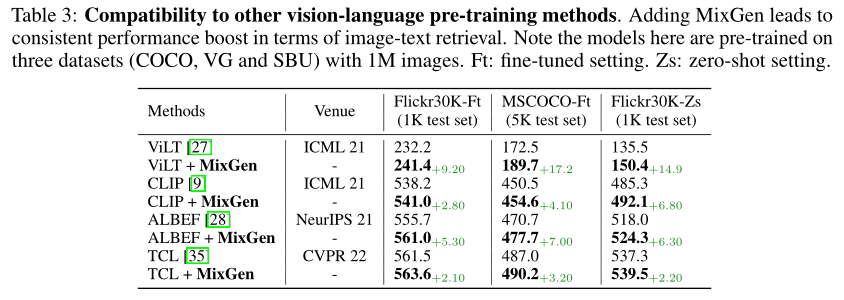
Additionally, the authors demonstrate the compatibility of MixGen with other visual-language pre-training methods, namely CLIP, ViLT, and TCL. Given that ViLT training is very expensive (e.g., requiring 64 V100 GPUs for 3 days), the authors only used three datasets (COCO, VG, and SBU) during the pre-training period of this experiment.
As shown in the table above, simply adding MixGen on top of these strong baselines can continuously improve state-of-the-art performance. In terms of fine-tuning image-text retrieval on COCO, MixGen shows significant absolute accuracy improvements: ViLT (+17.2%), CLIP (+4.1%), ALBEF (+7.0%), and TCL (+3.2%). This demonstrates the versatility of MixGen as an image-text data augmentation method in pre-training.
Finally, the authors investigate how much data efficiency MixGen can achieve. The authors reduce the number of images used for pre-training from 3M to 2M, 1M, and 200K. For 2M, the authors used three datasets plus a random subset from the CC dataset. For 200K, the authors only used two datasets (COCO and VG). The performance of image-text retrieval can be seen in the above figure.
First, note that adding MixGen is always better than not having it. Notably, the improvements in low data regimes are more pronounced. Secondly, the performance of ALBEF using MixGen during training on 1M, 2M, and 3M samples matches that of the baseline ALBEF trained on 2M, 3M, and 4M samples, respectively. This again indicates the data efficiency of MixGen.
The table above reports the performance comparison of different visual-language pre-training baselines on downstream VQA, VR, and VE tasks. Similar to the image-text retrieval task, MixGen consistently improves the performance of these three tasks. In the 3M setting, ALBEF using MixGen outperforms its corresponding baseline by 0.28% on VQA test-std, by 0.89% on NLVR2 test-P, and by 0.36% on SNLI-VE test.
The table above reports the performance of visual grounding on the RefCOCO+ dataset.
In the above figure, the authors demonstrate the visualization of text-to-image retrieval on MSCOCO. Specifically, given a text query, they wish to compare the rankings of retrieved true images among all retrieved images using ALBEF with and without MixGen. It can be seen that MixGen is generally able to locate matching images in the top-3 retrieved images, significantly outperforming the baseline ALBEF.
In the above figure, the authors show Grad-CAM visualizations to help understand why MixGen is beneficial. For the visual grounding task on the RefCOCO+ dataset, it can be seen that models trained with MixGen can more accurately locate image regions based on text queries.
In this work, the authors propose a new visual-language joint data augmentation method called MixGen. Adding MixGen to four recent state-of-the-art models can achieve continuous improvements across five different downstream tasks. Strong empirical results show that MixGen not only enables these models to learn better multi-modal latent representations but also enhances their data efficiency.
References
[1]https://arxiv.org/abs/2206.08358
Research Area: Operator of FightingCV public account, research direction in multi-modal content understanding, focusing on solving tasks that combine visual and language modalities, promoting the practical application of Vision-Language models.
Zhihu/Public Account: FightingCV
Welcome to join the ‘Data Augmentation’ group chat👇 Please note:Data