


The domestic AI video generation model Vidu enhances subject consistency based on reference functionality.
The AI video generation model Dream Machine 1.6 adds camera motion control features.
Beihang University and Aishi Technology jointly released a flexible and efficient controllable video generation method called TrackGo.
Google proposed “Generative Image Dynamics” to simulate the periodic dynamics of natural scenes.
【Key Insight】
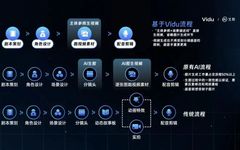
Controllable Video Generation focuses on precise control over the generated subject, object motion, and scene transitions, ensuring that the generated content maintains high coherence, stability, and integrity across different contexts. Currently, the industry commonly adopts the “text-to-image” to “image-to-video” technical route, but challenges arise in complex scenes, such as inconsistencies in subjects, disjointed motion trajectories, and violations of physical laws. Additionally, due to the numerous scenes and shots involved in video production, the generation workload is enormous.
In response, existing video generation tools have achieved certain applications in subject consistency and motion control; academic research based on diffusion models, combined with traditional image processing methods, tracks, characterizes, and predicts motion trajectories, thereby achieving fine control over complex scenes.
Enhanced generation control will comprehensively improve user personalization and precision in content generation, reducing errors and irrelevant information in multimodal, cross-scene, and complex logical tasks, ensuring the accuracy, controllability, and relevance of the output content, making AIGC practically applicable in film production, and fully unleashing the tremendous potential of modern intelligent technology.
01
The domestic AI video generation model Vidu enhances subject consistency based on reference functionality.
The domestic AI video generation model Vidu recently added a subject consistency feature. Users can upload an image of any subject, and Vidu can lock in that subject’s image, ensuring that even when switching scenes using descriptive terms, the output video maintains the subject’s consistency.
This feature is not limited to humans; whether it is a person, animal, product, anime character, or fictional subject, it can ensure consistency and controllability in video generation. If the subject is a person, users can choose to maintain facial consistency or overall character consistency.
Vidu eliminates the traditional storyboard generation steps by combining the uploaded subject image with input scene descriptions to generate video material directly, significantly reducing workload and breaking the limitations of storyboard images on video content, allowing creators to unleash greater imagination based on text descriptions and directly control the model to generate high-quality videos.
02
The AI video generation model Dream Machine 1.6 adds camera motion control features.
Dream Machine is a video intelligence generation tool launched by the AI technology company Luma AI, capable of generating 5-second/120fps videos from text or static images. Recently, Luma AI released a new version, Dream Machine 1.6, which adds camera motion control features to enhance the precision of camera movements.
Dream Machine 1.6 introduces 12 types of camera motion control features, allowing users to input specific instructions in text prompts, including Pull Out, Pan Left, Pan Right, etc., enabling more intuitive manipulation of video visual effects and generating more cinematic imagery.
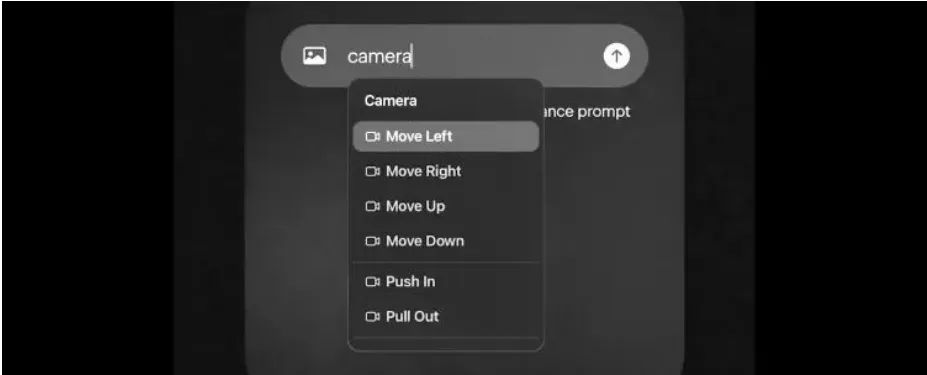
Dream Machine 1.6 has also made corresponding improvements to the user interface. When users input the word “Camera” in the prompts, the system will automatically pop up a dropdown menu listing all available camera motion options, providing a small 3D animation demonstration for each action, visually showcasing the action’s actual effect in the video.
The new features significantly enhance the fine-tuning effects of specific phrases, improving user control over the generated images. Meanwhile, the new version has greatly enhanced the range and intensity of camera movements, making the dynamic effects of generated videos more pronounced.
03
Beihang University and Aishi Technology jointly propose a flexible and efficient controllable video generation method called TrackGo.
Beihang University and Aishi Technology jointly proposed the AI video generation method TrackGo, allowing users to flexibly and precisely control video content using custom-drawn masks and arrows..

▲The first column shows the initial frame, the second column shows the user-input masks and arrows, and the third to sixth columns show the subsequent video frames generated by TrackGo.
To accurately describe and control target motion, TrackGo proposes a point trajectory generation method: selecting control points within the user-drawn masks, following the clear directions indicated by the arrows, and using video pixel tracking methods (Co-Tracker) to obtain point motion trajectories.
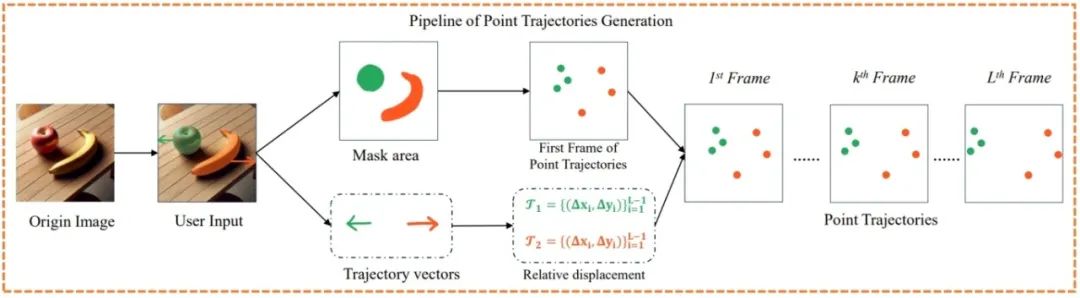
▲Point trajectory generation method technical route.
TrackGo uses Stable Video Diffusion as its infrastructure, seamlessly embedding a lightweight and efficient adapter (TrackAdapter) into the time self-attention layer of the generation model. TrackAdapter extracts temporal features from point motion trajectories and integrates them into motion conditions, calculating attention maps for each frame and setting thresholds to convert them into attention masks. The attention masks activate motion areas corresponding to specified objects, guiding the generation process.
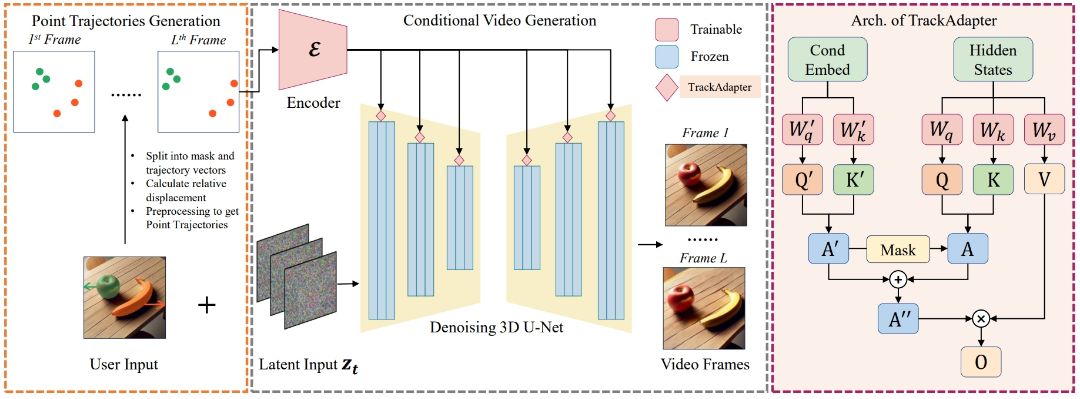
▲TrackGo model algorithm framework.
Additionally, TrackGo uses a lightweight encoder to extract temporal features and introduces attention loss to accelerate model convergence, significantly shortening inference time.
04
Google proposes “Generative Image Dynamics” to simulate periodic dynamics of natural scenes.
Google proposed a method for modeling generative priors for image spatial scene motion, targeting natural micro-vibrations such as swaying leaves, flickering candles, and animal breathing. This method consists of two modules: a motion prediction module and an image rendering module.
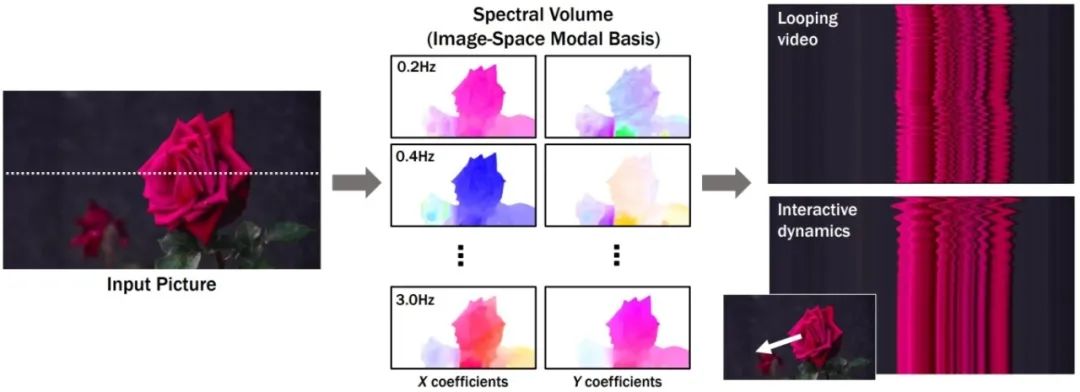
▲The left side shows the given image, the middle shows the spectral volume representation, and the right side shows the output video along the given image’s “X-axis displacement – time” slice.
The motion prediction module adopts a spectral volume expression form, where the spectral volume is the time Fourier transform of pixel trajectories extracted from video. For each row of pixels in the image, the motion trajectories in dynamic videos are presented as curves. Discrete Fourier transforms of these curves yield the amplitude and phase of different frequency components, with a few Fourier coefficients sufficing to approximate pixel trajectories. This module selects a latent diffusion model (LDM) as its backbone network and employs a frequency-coordinated denoising strategy to generate Fourier coefficients.

▲Image rendering module technical route.
The image rendering module uses depth image-based rendering technology to generate future frames. First, it encodes the input image to generate multi-scale feature maps, predicts a 2D motion field based on the size of each feature map, and then uses optical flow as pixel depth representation to determine the contribution weights of each source pixel mapped to its destination position. Applying Softmax Splatting to the motion field and weights produces warped features, which are then injected into the corresponding blocks of the image generation decoder to render the final image.
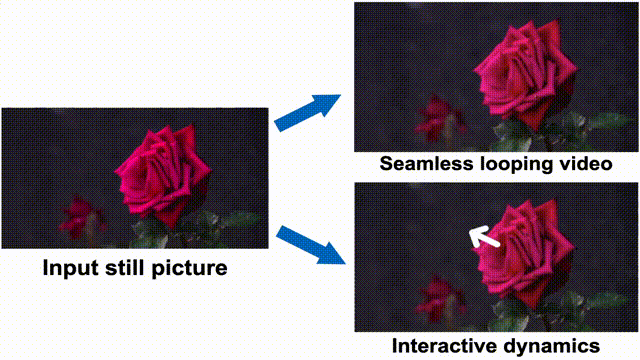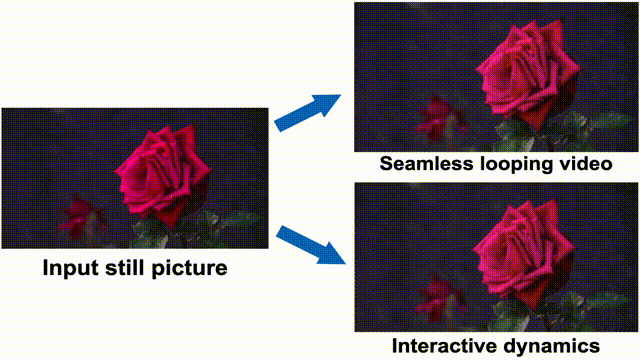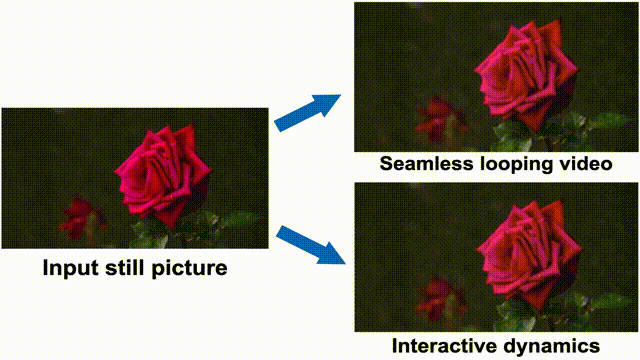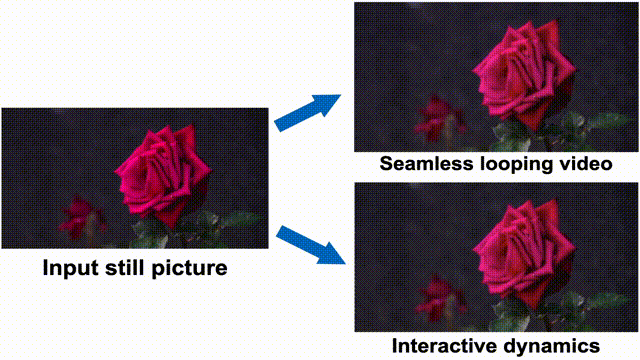
▲Application effects.
The simulated dynamic effects predicted by this method are applicable to various downstream applications, such as converting static images into seamless looping videos, precisely controlling object motion during video generation, and achieving user interaction with objects in real images. Simulating natural dynamic scenes not only promises to enhance video generation controllability and improve the realism and immersion of film works but also opens new dimensions for human-computer interaction in the film field, providing innovative ideas for audience interaction with film content.
(All images in this issue are sourced from the internet)

Edited by丨Xia Tianlin Zhang Xue
Proofread by丨Zhang Xue
Reviewed by丨Wang Cui
Final Review by丨Liu Da