 Good news! Join Knowledge Planet to read the full PDF version of this article in detail
Good news! Join Knowledge Planet to read the full PDF version of this article in detail
Paper Information
Title: EHCTNet: Enhanced Hybrid of CNN and Transformer Network for Remote Sensing Image Change Detection
EHCTNet: Enhanced Hybrid of CNN and Transformer Network for Remote Sensing Image Change Detection
Authors: Junjie Yang, Haibo Wan, Zhihai Shang
Innovations of the Paper
- Dual-Branch Hybrid Architecture: The paper proposes adual-branch hybrid architecture that combinesCNN and Transformer blocks to effectively integratelocal and global features.
- Novel Module Design: The authors designed novel modules such asHead Residual Fast Fourier Transform (HFFT),KAN-based Channel and Spatial Attention Block (CKSA), andTail Residual Fast Fourier Transform (BFFT).
- Enhanced Token Mining: The paper introduces aTransformer module based on enhanced token mining, which generatessemantic tokens throughKAN layers and capturesglobal semantic relationships usingTransformer encoders and decoders.
- Frequency Component Refinement: ThroughRefinement Modules I and II, the paper proposes asymmetrical FFT structure forrefining frequency components of feature images and semantic maps.
Abstract
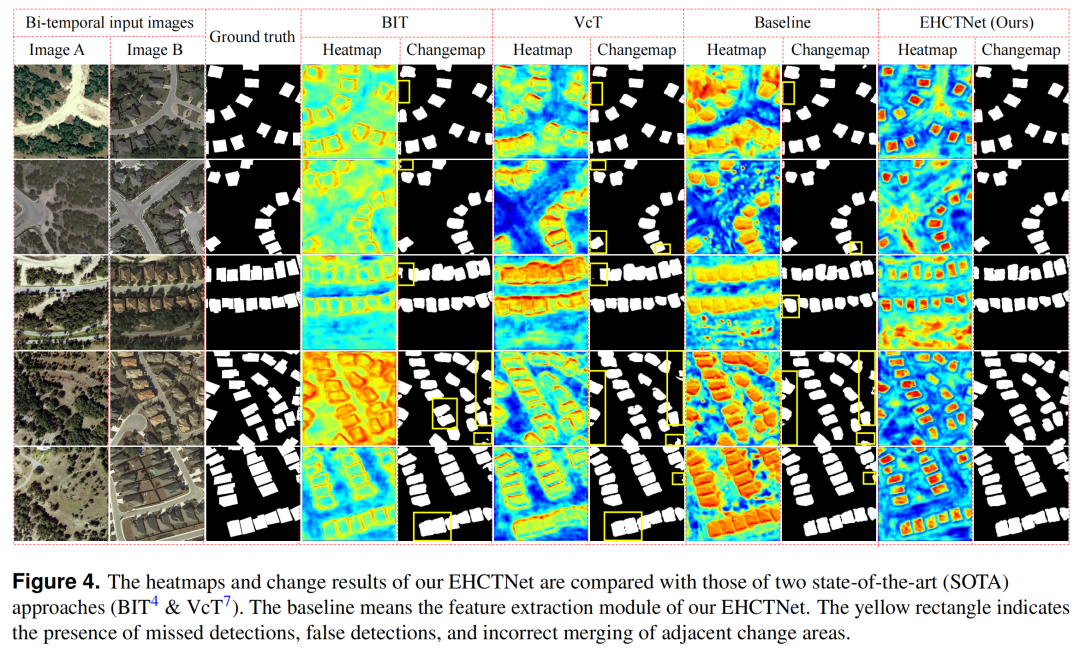
Remote sensing (RS) change detection faces challenges due to the high cost of false negatives, which is often greater than that of false positives. Existing frameworks have limitations in improving precision metrics to reduce false positive costs, making it difficult to focus on changes of interest, resulting in missed detections and discontinuities. This paper addresses these issues by enhancing feature learning capabilities and integrating feature information through frequency components, proposing a strategy to gradually improve recall values. The authors propose an enhanced CNN and Transformer hybrid network (EHCTNet) to effectively mine change information of interest. First, a dual-branch feature extraction module extracts multi-scale features from RS images. Second, frequency components of these features are utilized through the improved Module I. Third, an enhanced token mining module based on Kolmogorov-Arnold networks is used to extract semantic information. Finally, frequency components of semantic change information beneficial for final detection are mined from the improved Module II. Extensive experiments validate the effectiveness of EHCTNet in understanding complex changes. Visualization results show that EHCTNet can detect more complete and continuous change areas and is more accurate than existing state-of-the-art models in distinguishing adjacent areas.
Keywords
Remote sensing images, change detection, convolutional neural networks, Transformer, Kolmogorov-Arnold networks, frequency components
III. Proposed Method
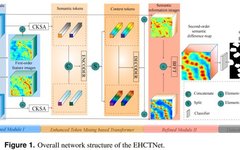
The overall architecture of EHCTNet includes five modules: 1) Feature extraction module, 2) Refinement Module I, 3) Transformer module based on enhanced token mining, 4) Refinement Module II, and 5) Detection head module, as shown in Figure 1. The feature extraction module consists of a dual-branch hybrid architecture (HCT) of CNN and Transformer, aimed at extracting raw multi-scale features from dual-temporal images. HCT combines the local feature extraction capability of CNN with the global contextual feature learning ability of Transformer, significantly enhancing the representation of raw features. Refinement Module I is located after the feature extraction module and is a frequency attention module designed to refine the frequency details of the raw multi-level features and generate first-order features. The Transformer module based on enhanced token mining takes the first-order refined features as input to obtain semantic information. Refinement Module II is located deeper in EHCTNet and is symmetrical to Refinement Module I, also being a frequency attention module, aimed at refining the frequency components of semantic information in the Transformer module based on enhanced token mining to generate second-order semantic difference information. Refinement Module I primarily helps the model acquire refined frequency features for each image, which is beneficial for change detection, while Refinement Module II is used to learn high-level semantic difference information from the semantic difference map. Finally, the detection head is used to generate change maps.
Feature Extraction Module
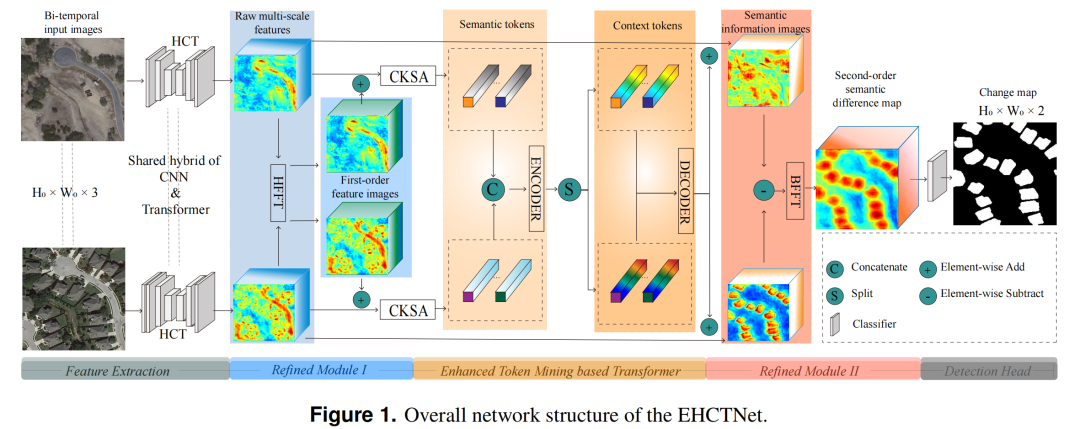
Inspired by the hybrid idea and the CMTFNet model, the authors construct a dual HCT block, called the feature extraction module, to fuse local and global features. The two branches of the feature extraction module share learnable parameters and have the same structure. Each branch is an HCT, with the structure of HCT shown in Figure 2. The encoder part uses ResNet50 to encode hierarchical features, while the decoder part consists of three Transformer blocks to decode multi-scale global contextual features. To fuse local hierarchical features and global contextual features, fusion operations are performed after the first three decoder blocks. The first two fusion operations capture rich local features and global contextual information, but lack spatial details. Therefore, the third fusion is crucial for integrating spatial features from the first CNN module (such as radiance intensity, edges, corners, and textures). The decoder generates multi-scale global contextual information and gradually restores feature resolution through fusion of hierarchical features obtained from the CNN module. Additionally, a learnable variable is used to weigh the importance of local features and global contextual information during the fusion process. Thus, the contributions of the two elements to the output are formulated as:where represents the fused output, is the learnable variable, is the local feature output from the encoder part, is the global contextual information output from the decoder part.
Refinement Module I
Combining spectral layers and multi-head attention mechanisms, the model can achieve state-of-the-art performance. Therefore, the authors design a joint module consisting of Refinement Module I, the Transformer module based on enhanced token mining, and Refinement Module II, which are located after the feature extraction module. Refinement Module I generates first-order features that help represent detailed information in each raw feature image. In this paper, Refinement Module I mainly consists of a Fast Fourier Transform (FFT) layer, a weighted gating mechanism, and an inverse FFT layer, which can be expressed as:where is, and are the outputs of operations, is the raw feature image,,, and represent the FFT, weighted gating mechanism, and inverse FFT processes in Refinement Module I, respectively.The FFT layer in Formula 2 transforms the feature map from physical space to frequency space. The weighted gating mechanism, as a learnable weight parameter in neural networks, can adjust its weights through backpropagation during the training process, effectively identifying frequency domain features in the feature map and determining the importance of each frequency component in feature representation. The inverse FFT converts the feature map from frequency space back to physical space, thereby generating refined frequency features with enhanced details, referred to as first-order features.Finally, the output of Refinement Module I retains features from the original feature image through a residual connection. The above process can be represented as:where is the output of Refinement Module I.
Transformer Module Based on Enhanced Token Mining
The feature extraction module extracts and fuses multi-scale features from dual-temporal RS images in the first two steps. The authors then utilize Refinement Module I to obtain first-order features. At this step, the Transformer module based on enhanced token mining is used for semantic token extraction and semantic information perception. The Transformer module based on enhanced token mining consists of two units: a KAN-based Channel and Spatial Attention (CKSA) block and a Transformer unit.
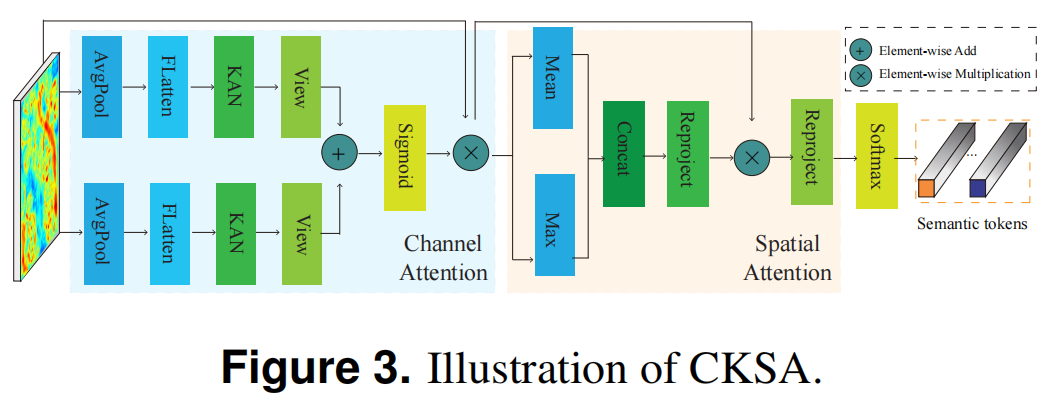
The semantic token operation helps interact with change information in remote sensing change detection tasks. Semantic tokens represent high-level concepts of changes of interest. They are one of the key elements in change detection. Furthermore, the ability of the KAN layer to promote customized activation learning and calculate the contribution of each input channel has been validated in the fields of computer vision and RS. Inspired by the capability of the KAN layer, the authors first design the CKSA block (Figure 3) to generate two sets of condensed tokens for precise learning of semantic tokens in this module. The CKSA block mainly consists of channel and spatial attention units. Specifically, the authors replace the fully connected layer with the KAN layer. In CKSA, the process of converting the feature image into tokens can be represented as:where is the output token of CKSA, CKA represents the KAN-based channel attention operation, and SA represents the spatial attention operation.CKSA obtains tokens of image features that contain rich details of changes in the feature image but lack semantic information regarding the interaction relationships between tokens. The Transformer can fully utilize high-level global semantic relationships in the token space. Therefore, the authors introduce a Transformer block in the subsequent stage of the Transformer module based on enhanced token mining. First, the two token sets from CKSA are concatenated to form a token aggregation, which is then input into the encoder of the Transformer to capture the global semantic context among these tokens. Since the token aggregation involves concatenating semantic token sets along the second dimension, it can be likened to binding two bundles of token strips together. Thus, the Transformer encoder can extract internal relationships within a set of tokens and the interrelationships between two sets of semantic tokens. As a result, the output of the Transformer encoder is rich in high-level semantic information within the tokens and global semantic information between tokens.The authors divide high-level semantic context into two groups of contextual tokens, each with the same dimension as the CKSA tokens. These two groups of contextual tokens encapsulate condensed semantic context and represent high-level information of hotspots. Subsequently, the Transformer decoder is deployed to restore these two groups of contextual tokens into dual-semantic pixel maps in pixel space. The dual-branch pixel maps are rich in high-quality semantic information, allowing each pixel to be represented by two groups of contextual tokens. This representation effectively highlights the pixel values of interest in the semantic map.The semantic pixel map effectively reveals semantic hotspots in the feature space. Subsequently, the semantic pixel maps are subtracted to obtain a semantic difference map, which represents the semantic information of changes. The subtraction between semantic pixel maps may lead to positive and negative results. To ensure all values are non-negative, the authors convert any negative results to their absolute values, defined as:where and represent the pixel values of the semantic pixel maps, and represents the pixel values of the semantic difference map generated by taking the absolute value of the subtraction.
Refinement Module II
HFFT of Refinement Module I and BFFT of Refinement Module II are symmetrically placed at the early and late stages of the EHCTNet model, as shown in Figure 1. Similar to HFFT, BFFT also includes FFT layers, weighted gating, inverse FFT layers, and residual connections. BFFT is used to refine the semantic difference map and generate second-order semantic difference maps. Refinement Module II can be expressed as:where is the output of Refinement Module II.In this subsection, the semantic difference map is first resized to match the dimensions of the original RS image. BFFT transforms the physical space of the resized semantic difference map into frequency space, where the details of the semantic difference map are depicted. It is then restored to physical space, generating second-order semantic difference information in the refined semantic difference map.
Detection Head
The second-order semantic difference information in the refined semantic difference map represents the final stage of semantic information. It is directly used in the detection head module to distinguish change areas from background areas. A fully convolutional network is employed in the detection head to generate change maps with dimensions, where and represent the height and width of the original dual-temporal RS image.
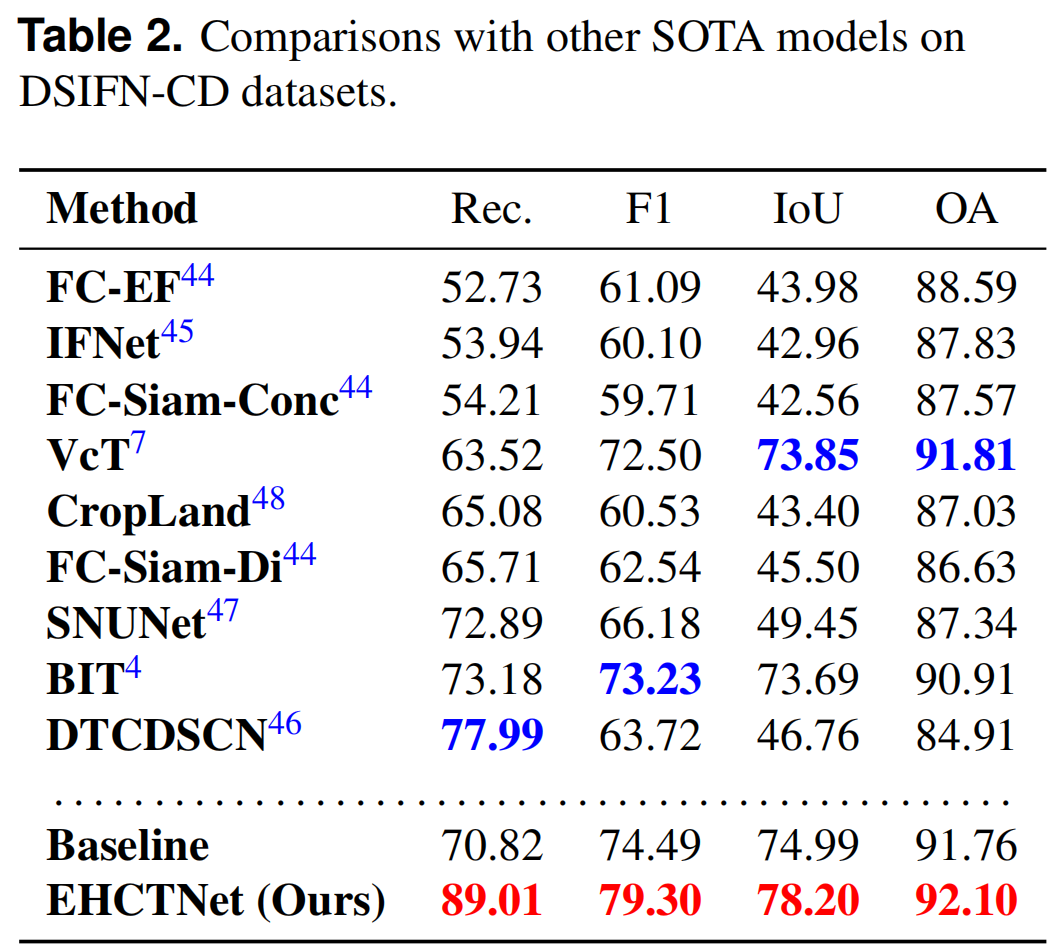
IV. Experiments and Analysis

Statement
This article shares the learning outcomes of the paper. Due to limitations in knowledge and ability, there may be deviations in understanding the original text, and the final content is subject to the original paper. The information in this article aims to promote dissemination and academic exchange, and the content is the responsibility of the authors, not representing the views of this account. If there are any issues regarding copyright and other matters concerning the text, images, etc., please contact us in a timely manner, and we will respond and handle them promptly.
#Paper Promotion#
Let your paper work be seen by more people
Do you have such a frustration: your hard work on the paper has almost no citations. Why is this? Mainly because your work has not been understood by more people.
Computer Book Boy builds a platform for everyone to promote their papers, so that more people understand their work, while promoting collisions of different backgrounds and directions of scholars and academic inspirations, sparking more possibilities.Computer Book Boy encourages university laboratories or individuals to share theirpaper introductions, interpretations, etc., on our platform.
Basic Requirements for Manuscripts:
• The article is indeed aninterpretation of personal papers, not previously marked as original on the public account platform,
• Manuscripts are recommended to be written in markdown format, and images in the text should be clear and have no copyright issues
Submission Channel:
• Add the editor’s WeChat to discuss submission matters, note: name-submission

△ Long press to add PaperEveryday Editor
