GoogleAIvideo generation modelVeo can create videos longer than 60 seconds
Tsinghua University and Shengshu Technology jointly released the domestic video large model Vidu
Domestic AI film production platform FilmAction has entered the internal testing phase
【Highlight】
With the advancement and rapid iteration of AI technology, AI video generation models are continuously improving in terms of video length, image quality, and the richness of cinematic language, with corresponding products increasingly approaching professional film and television needs, and constantly improving in practical applications.
01
Google AI video generation model Veo can create videos longer than 60 seconds
At the recent I/O Developer Conference, Google released the AI video generation model Veo, which can generate 1080p video clips longer than 60 seconds based on text and image prompts, supporting customizable lighting, cinematic language, and video color, and supports various visual and cinematic styles, capable of understanding professional film terms such as “time-lapse” and “aerial photography” in the prompts.

▲ Prompt: A convertible sports car from the 1960s drives towards a Spanish Mediterranean-style place, tracking shot
Veo is built on various research results from Google, including GQN, Phenaki, Walt, VideoPoet, Lumiere, etc., integrating the architectures and technologies used in them, improving consistency, technical quality, and video resolution.
Veo also supports video extension; if you are not satisfied with the length of the existing video, you can let Veo automatically extend the video or add more prompts to generate a longer video, currently with a maximum duration of 1 minute and 10 seconds.

▲ Prompt: A white sailboat elegantly glides across a tranquil surface of water, cinematic fixed shot
Currently, Google has opened a trial channel and expects to provide a beta version to some users in 2024. Google has collaborated with filmmakers to explore the application of Veo in film projects and is preparing to add some functions of Veo to the YouTube short video module.
02
Tsinghua University and Shengshu Technology jointly released the domestic video large model Vidu
At the 2024 Zhongguancun Forum Annual Conference Future Artificial Intelligence Pioneer Forum, Tsinghua University and Shengshu Technology jointly released the domestic video large model Vidu. This model can generate a maximum of 16 seconds of 1080p video in one go, performing well in the application of cinematic language and physical logic consistency.

This model is based on the deep integration of Diffusion and Transformer technologies, using the U-ViT architecture. ViT (Vision Transformer) is a deep learning model proposed by the Google team in 2020 that applies the Transformer architecture to visual tasks, capable of capturing long-range dependencies in images and has good scalability, able to handle images of various sizes.
The U-ViT architecture is an extension and improvement of ViT, combining the Diffusion generation model with the Transformer architecture to achieve efficient processing of long video data, while maintaining video coherence and realism, further enhancing the quality and efficiency of video generation.

Vidu can generate videos with camera movements including zoom, pan, and push-pull, and can present different perspectives of the same scene by switching camera angles, while maintaining the consistency of the subject in the scene, and can achieve complex shot effects such as transitions, follow-focus, and long shots, greatly enriching the cinematic language of the video. As a domestically developed video generation large model, Vidu can fully understand Chinese elements and can generate unique Chinese elements such as pandas and dragons in the video.
03
Domestic AI film production platform FilmAction enters internal testing phase
Our country’s AI film production platform FilmAction has recently entered the internal testing phase. This platform has functions such as film creation, image generation, video generation, and music generation, and will introduce features such as image cutout, video green screen, voice cloning, virtual hosts, music remixing, hand-drawn input, and meme generation in the future.

When creating films, users can first use AI to generate a story outline, then choose the film style, genre, and number of shots, with the selection and insertion of scripts, images, videos, as well as narration and music being completed with one click, where each step can be modified based on AI generation.
In the work settings, users can download all relevant materials, including storyboard videos, storyboard images, storyboard scripts, storyboard narrations, scripts, and dubbing files.
Based on practical testing, since character descriptions were determined during the character setting phase, the main character images generated in different storyboards can remain consistent. When generating storyboard videos, users can choose from three video styles: “smooth,” “default,” and “dynamic,” with the camera movements in the generated results being quite in line with actual film shooting techniques, but the movement amplitude is not large, and cannot yet showcase the dynamic feel of intense action scenes. Currently, dubbing only supports narration generation and cannot create dialogues for different or multiple characters.
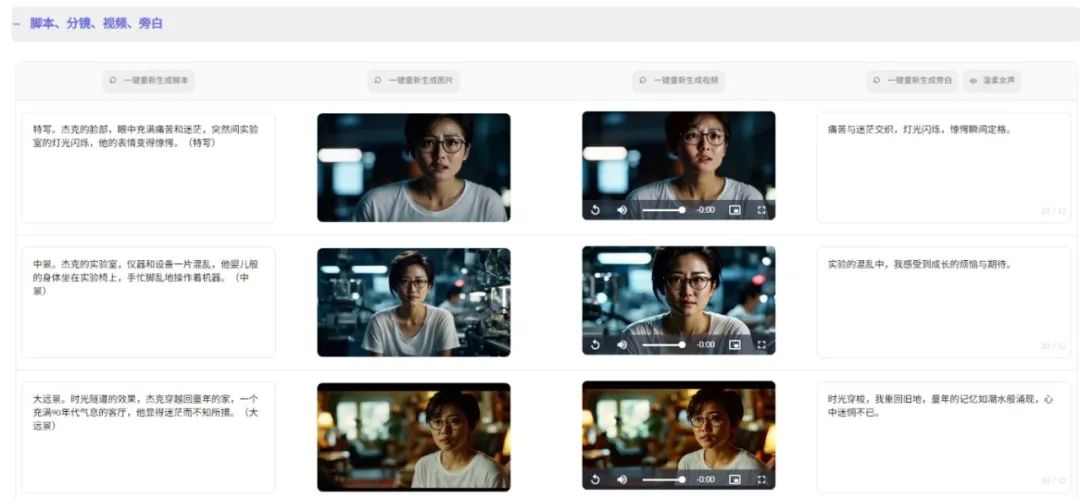
Overall, the platform performs well in character consistency, video style, and ease of use, but the generated films are relatively simple overall, and at this stage can be used for visual previews, or the generated results can be applied to professional film production after manual modification and optimization.
(All images in this issue are from the internet)

Editor: Zhang Xue
Proofreader: Wang Jian
Reviewer: Wang Cui
Final Review: Liu Da