
Source: Contribution Author: Mao Huaqing
Editor: Xuejie
Table of Contents
-
Related Knowledge
-
GPT
-
BERT
-
T5
-
Summary
-
Background Introduction
-
Main Contributions and Innovations
-
GLM 6B
-
Custom Mask
-
Model Quantization
-
1TB Bilingual Instruction Fine-tuning
-
RLHF
-
PEFT
-
Training Strategy
-
Model Parameters
-
Six Metrics
-
Other Evaluation Results
-
Environment Preparation
-
Running Invocation
-
Code Invocation
-
Web Service
-
Command Line Invocation
-
Model Fine-tuning
Introduction
This course comes from Deep Eye’s “Large Models – Cutting-edge Paper Reading Training Camp” open class, and some screenshots are from the course video.
This sharing isa course study note, it is recommended to be used with the video.
Video link: https://ai.deepshare.net/p/t_pc/goods_pc_detail/goods_detail/p_6437a874e4b0b2d1c407396e
Article Title:GLM-130B: AN OPEN BILINGUAL PRE-TRAINED MODELGLM-130B: An Open Bilingual Pre-trained ModelArticle Link:https://arxiv.org/pdf/2210.02414.pdfAuthor:Hugo Touvron et al.Institution:Tsinghua UniversityPublication Date:ICLR 2023
Project Address:https://github.com/THUDM/GLM-130B
This model has a lightweight version GLM-6B
General Reading
This model was proposed by Tsinghua University’s KEG Lab and Zhizhu AI, so the support for Chinese is quite pronounced.
Related Knowledge
To grasp the innovations of this model, it is necessary to understand the advantages and disadvantages of three (types of) models.
GPT
GPT stacks 12 decoder layers. Since there are no encoders in this setup, these decoder layers will not have the encoder-decoder attention sublayers that regular transformer decoder layers possess. However, it still has self-attention layers. It is a self-regressive model, and its main advantage is that it can be used for generation tasks.
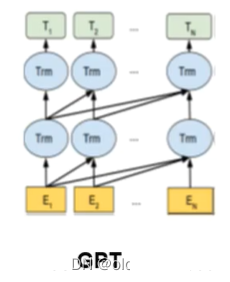
From its model structure diagram, it can be seen that the model can only see the current token and the previous tokens, and then predict the following tokens.
Simply put, it takes in a sentence (input):
Converted into word vectors:
Looped through several Decoders (which are Transformer_blocks):
Finally, through softmax to obtain the probability of the next word:
The above steps represent the contextual vector representation of tokens; the number of Decoder layers of the model; the representation matrix of tokens; and the position representation matrix. The generation method is not suitable for parallel processing.
Why does GPT not use the Transformer Encoder for training?
Because BERT-type models are deep bidirectional predictive language models, there is a problem of seeing itself during the prediction (the next word to be predicted has already appeared in the given sequence), which does not achieve the expected effect.
For example, if the model’s input is four tokens ABCD, taking token B as the perspective, after entering the second layer:
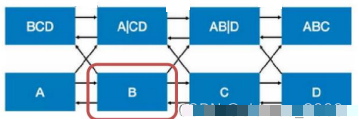
Due to the bidirectional relationship, after the message is propagated (as shown by the arrows), at the corresponding position in the second layer, information can be seen as shown in the figure above.
After entering the third layer, the position corresponding to the red box obtains the information of token B itself from the side, losing the significance of letting the model learn to predict B.
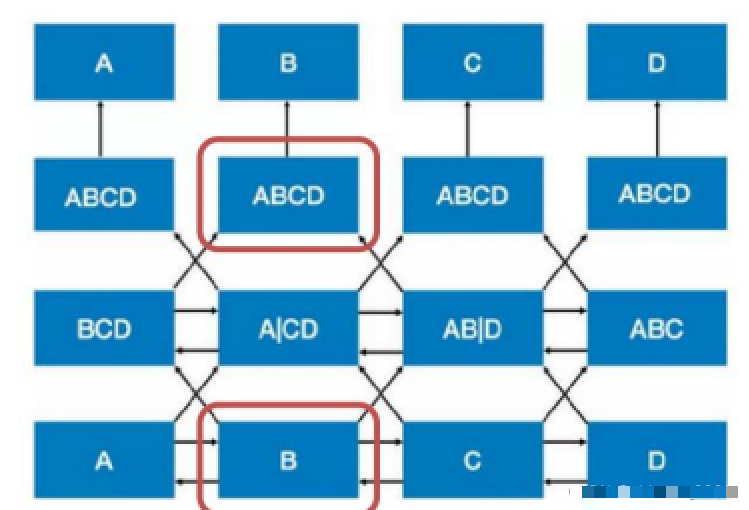
BERT proposes to use the Masked Language Model (MLM) approach for training.
BERT
From the above reasoning, it can be seen that the self-encoding type BERT uses stacked bidirectional Transformer Encoders, which jointly depend on the left and right contexts in all layers.
-
The basic version has 12 Encoders (12 layers); -
The advanced version has 24 Encoders (24 layers)
Due to the training method of MLM, BERT models are better at fill-in-the-blank tasks, which means understanding language.
T5
T5 is a complete Transformer structure that includes an encoder and a decoder, represented by T5 and BART, commonly used for conditional generation tasks (conditional generation), such as translation, Q&A, reasoning, and summarization.
This means that this type of model can perform both generative tasks and understanding tasks.
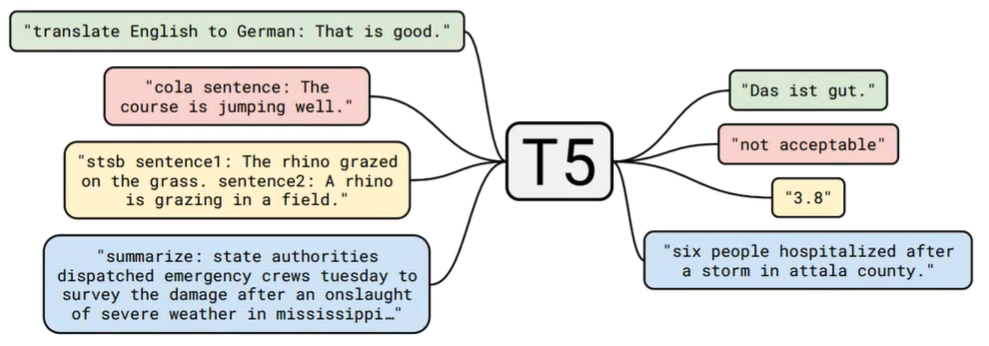
This structure, while combining the advantages of the two models above (to achieve RoBERTa’s metrics), also brings evident problems, namely an increase in the number of parameters, which can lead to high training costs and, on a larger scale, is not environmentally friendly and does not contribute to carbon neutrality. This is one of the pain points that GLM aims to address.
Summary
Currently mainstream pre-training frameworks can be divided into three types:
-
The representative of autoregressive models is GPT, which is essentially a left-to-right language model, commonly used for unconditional generation tasks. -
Autoencoding models are language encoders trained through a denoising objective (such as masked language modeling), such as BERT, ALBERT, DeBERTa, RoBERTa. Self-encoding models excel at natural language understanding tasks (NLU) and are often used to generate contextual representations of sentences. -
Encoder-decoder is a complete Transformer structure that includes an encoder and a decoder, represented by T5 and BART, commonly used for conditional generation tasks.
The idea behind GLM is to combine the advantages of the above models without significantly increasing the number of parameters. The current performance of ChatGPT demonstrates that it can not only generate but also perform Q&A and understanding, which is due to the emergence phenomenon of large models, where feeding data to a sufficient extent allows the generated answers to achieve Q&A and understanding effects.
Background Introduction
GLM-130B is a bilingual (English and Chinese) pre-trained language model with 130 billion parameters, using the General Language Model (GLM) algorithm.
ChatGLM references the design ideas of ChatGPT, injecting code pre-training into the 100 billion base model GLM-130B, and aligning human intent through techniques such as supervised fine-tuning. The capability enhancement of the current version of ChatGLM mainly comes from the unique 100 billion base model GLM-130B.
GLM-130B supports various natural language processing tasks such as text generation, text understanding, text classification, and text summarization, with a wide range of application scenarios, including machine translation, dialogue systems, knowledge graphs, search engines, and content generation.
GLM-130B outperforms other models in multiple English and Chinese benchmark tests, such as GPT-3 175B, OPT-175B, BLOOM-176B, ERNIE TITAN 3.0 260B, etc.
Key Point:Open-source Model
ChatGLM internal testing application: https://chatglm.cn/
Q: Why use English?
Research has shown that feeding code as corpus to pre-trained models can improve the model’s reasoning ability, as code corpus is usually in English.
Main Contributions and Innovations
-
GLM-130B is currently the largest open-source bilingual pre-trained model, while GLM-6B can also support inference on a single server with a single GPU. -
GLM-130B uses the GLM algorithm, achieving a bidirectional dense connection model structure that enhances the model’s expressive and generalization capabilities. -
During the training process, GLM-130B encountered various technical and engineering challenges, such as loss fluctuations and non-convergence, and proposed effective solutions, open-sourcing the training code and logs (a significant portion of the 48-page paper is dedicated to this content). -
GLM-130B utilizes a unique scaling property to achieve INT4 quantization with almost no loss in accuracy, and supports various hardware platforms (local platforms can be used, not necessarily NVIDIA).
GLM 6B
The parameter count of ChatGLM-6B is 6.2 billion, supporting bilingual (Chinese and English), and can perform inference on a single 2080Ti. In FP16 half-precision floating point mode, it requires 13GB of VRAM, while using INT4 mode only requires about 7GB. The generated sequence length reaches 2048, and human intent alignment training has been performed.
Close Reading
Let’s first review the three models mentioned earlier and the improvements made by GLM
| Model Name | Training Objective | Model Structure |
|---|---|---|
| GPT | Text generation from left to right, unconditional generation | Unidirectional attention, unable to utilize downstream information |
| BERT | Randomly masking text and predicting the masked words | Bidirectional attention, can perceive context simultaneously (strong in understanding tasks, but not suitable for generation tasks) |
| T5 | Accepting a segment of text, generating another segment of text from left to right, conditional generation (input text is the constraint) | Encoder with bidirectional attention, decoder with unidirectional attention, can perform both understanding and generation tasks, but with a large number of parameters |
| GLM | Compatible with three tasks (unconditional generation, autoregressive, conditional generation) through freely combining MASK and text | Custom Mask matrix |
It can be seen that GLM aims to combine the advantages of the three models, relying on a custom MASK, with the main ideas outlined in the table below:
| Equivalent Model | MASK Form |
|---|---|
| GPT | When all text is masked, the blank-filling task is equivalent to an unconditional language generation task. |
| BERT | When the length of the masked segment is 1, the blank-filling task is equivalent to masked language modeling. |
| T5 | When text 1 and text 2 are concatenated and text 2 is entirely masked, the blank-filling task is equivalent to conditional language generation. |
Custom Mask
Assuming a sentence is represented as:
Randomly sampling some segments (span) from this sentence, note that it is random sampling; suppose the result is 2 segments, marked in green and yellow:
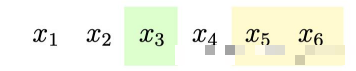
After taking out the sampled segments, the original sentence is divided into two parts:
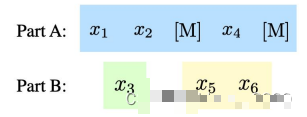
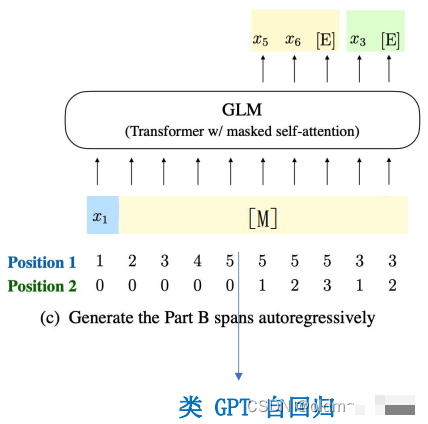
Then train in the following way:
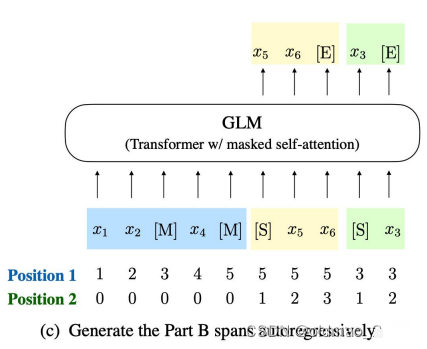
The blue part is the input to the Encoder in GLM, while the yellow and green parts correspond to the input to the Decoder.
Those who have studied NLP know that the letters MSE stand for mask, start, and end.
In the output above, since the yellow part is generated based on the previous blue part (acting as the condition), this part is equivalent to the generation result of the T5 model; the green part only masks one word, so all previous information can be seen, thus equivalent to the generation result of the BERT model. The entire self-attention mask is shown in the figure below:
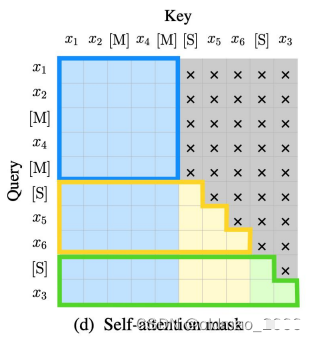
The blue box part can see all tokens in the context;
The yellow part can see all tokens in blue and the preceding yellow context;
The green part can see all tokens in blue and yellow.
To be more precise:
-
Words in Part A can see each other (the area in the blue box in figure (d)); -
Words in Part B can see unidirectionally (the light yellow area in figure (d), green can too, but the green part only has one word); -
Part B can see Part A (the area in the red box in figure (d)); -
The rest are not visible (the gray area in figure (d));
The above demonstrates how GLM simulates T5 and BERT. If all tokens are masked, it simulates the GPT model:
Model Quantization
This technology contributes to reducing VRAM usage. The main approach is to use low-precision INT4 types to store the model, of course, this is based on ensuring that model performance is not significantly compromised.
In real life, there are corresponding examples: MP3
A 320kbps MP3 would be about 8-12MB, while a 192kbps MP3 would shrink to half its size, and for the average person (with normal hearing), it is hard to discern any significant quality loss.
I have also had a similar experience; previously while processing data, the memory exploded due to large data sizes. After consulting an expert, I learned that the default data type read into memory is FLOAT, which occupies a lot of space. The solution was to convert the type to INT before reading into memory, as the data was originally integers and did not need to be saved in a format like 1.000000.
1TB Bilingual Instruction Fine-tuning
This essentially allows the model to see various types of input, similar to interacting with ChatGPT, where the same question can be asked in various ways. The difficult part is how to enable the model to understand the question. How to (semi)automatically construct input instructions is very helpful for enhancing the model’s generalization performance.
RLHF
Reinforcement learning based on human feedback.
Reinforcement learning from human feedback
This technology can reduce the cost of corpus labeling and align the model closer to human performance (or the model will evolve to meet human expectations).
PEFT
Parameter Efficient Fine-Tuning is a technique that allows fine-tuning with less VRAM.
For specific introduction, please refer to: https://zhuanlan.zhihu.com/p/618894319?utm_id=0
Training Strategy
See the appendix of the paper for details.
-
GLM-130B was trained on a cluster consisting of 96 NVIDIA DGX-A100 (8 * 40G) GPU nodes, with each node having 8 A100 GPUs, responsible for 135 million parameters each; -
GLM-130B used ZeRO (Rajbhandari et al., 2020) as the optimizer, which effectively reduces VRAM usage and communication overhead, improving training efficiency; -
GLM-130B utilized mixed precision training (Micikevicius et al., 2018) and gradient accumulation (Chen et al., 2016) to enhance training speed and stability.
Experimental Analysis and Discussion
Model Parameters
-
GLM-130B has 96 layers for both the encoder and decoder, with 64 attention heads per layer and a hidden layer dimension of 8192; -
The total parameter count of GLM-130B is 130 billion (hence the name 130B), with 60% for the encoder and 40% for the decoder; -
GLM-130B uses Byte Pair Encoding (BPE) (Sennrich et al., 2016) as the vocabulary, with a total of 500,000 words, half of which are English and half Chinese.
Six Metrics
Accuracy, robustness, fairness, the higher the number, the better:
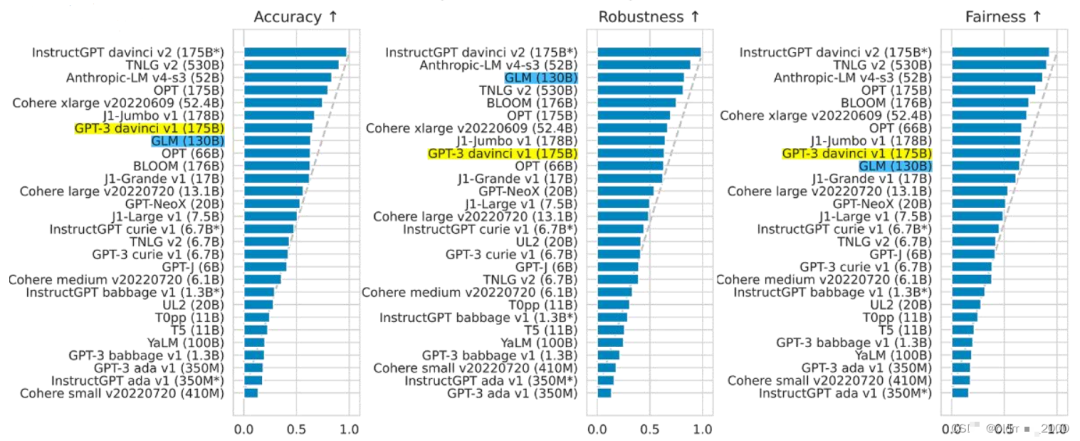
Among the above metrics, there seems to be a model starting with Cohere that also performs impressively.
Calibration error, bias, toxicity (involving gambling, drug, and other harmful speech), the lower the number, the better. For the last metric, GPT performs well likely due to its dominance in the corpus.
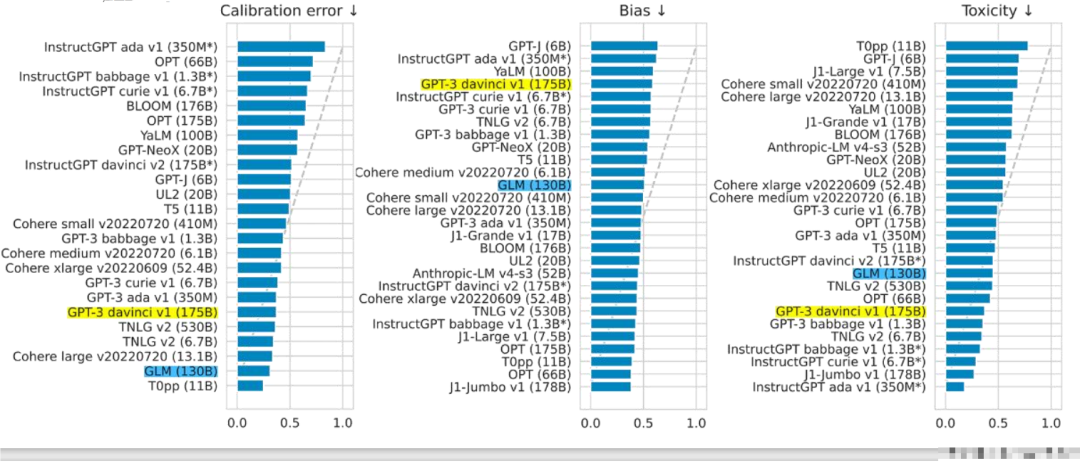
The above results come from Stanford’s mainstream evaluation report: https://arxiv.org/pdf/2211.09110.pdf
In which figure 26 (p55)
GLM is the only Chinese model selected in this report, with accuracy and maliciousness on par with GPT-3, and robustness and calibration error performing best among all models.
Other Evaluation Results
A third-party foundation’s open evaluation results indicate it possesses 70% of ChatGPT’s capability level.
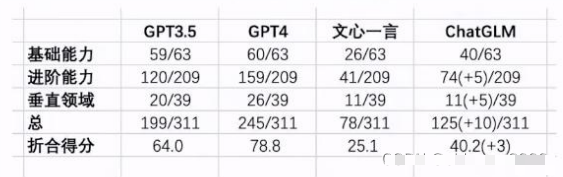
Domestic large model capability evaluation:
-
1) Understanding of classical poetry and idioms in Chinese context is more accurate -
2) Performance in topic writing (continuation, style imitation, etc.) is significantly better -
3) Ability to correct answers is stronger -
4) Context understanding capability is significantly better -
5) Code output includes explanations -
6) No obvious objective questions that cannot be answered -
7) Slightly better in mathematical calculations and logical reasoning capabilities
Code Reproduction (6B)
Environment Preparation
https://github.com/pengwei-iie/ChatGLM-6B
Server installation configuration can be found in the previous large model paper reproduction notes.
Open the terminal and create a project folder:
mkdir GLM6B
Use cd to enter the folder, then clone the project:
git clone https://github.com/pengwei-iie/ChatGLM-6B.git
The ptuning directory contains the model fine-tuning code, but the fine-tuning dataset needs to be downloaded separately, which will be discussed later.
cli_demo.pyweb_demo.py
These two are used for prediction code.
Download the model from hugging face (https://huggingface.co/THUDM/chatglm-6b) to local, download address: https://huggingface.co/THUDM/chatglm-6b/tree/main, it can be downloaded to another directory, the files are large, be sure to confirm whether the download is complete, otherwise loading failure errors will occur.
Install dependencies:
pip install -r requirement.txt
Running Invocation
Code Invocation
The parts of the code that load the tokenizer and model can be replaced with local file paths; otherwise, it will automatically download from hugging face remotely.
history is the historical dialogue information
from transformers import AutoTokenizer,AutoModel
#
tokenizer=AutoTokenizer.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True)
model=AutoModel.from_pretrained("THUDM/chatglm-6b",trust_remote_code=True).half().cuda()
model.eval()
response,history=model.chat(tokenizer,"你好",history=[])
>>>print(response)
Web Service
The web service is based on Gradio, so it needs to be installed first
pip install gradio
Then you can start the web service
python web_demo.py
You will get a URL, copy it to the browser to start the conversation.
Command Line Invocation
The main command is to run cli_demo.py, and you also need to modify the path inside.
python cli_demo.py
After loading the model, it will display:
“Welcome to use the ChatGLM-6B model, input content to start the conversation, clear to clear conversation history, stop to terminate the program”
By default, it can only ask in English.
The model can also be called using API; specific details can be found in the github instructions, which will not be elaborated here.
Model Fine-tuning
The original instruction file address is: https://github.com/pengwei-iie/ChatGLM-6B/blob/main/ptuning/README.md
The fine-tuning dataset download address is: https://cloud.tsinghua.edu.cn/f/b3f119a008264b1cabd1/?dl=1
The downloaded file is named: AdvertiseGen.tar.gz
It is about 16MB, and contains two json files.
The dataset dictionary contains two fields: content and summary. The task is to generate a piece of advertisement summary based on the content field.
Below is the format of a single sample, where asterisks can be seen as separators and hashtags can be seen as colons.
{
"content": "Type#Top*Material#Denim*Color#White*Style#Simple*Pattern#Embroidery*Clothing Style#Outerwear*Clothing Type#Distressed",
"summary": "A simple yet sophisticated denim jacket, the white fabric is very versatile. The jacket features several distressed designs that break the monotony, adding a touch of style. The back of the jacket has interesting embroidery decorations that enrich the layering and showcase unique fashion."
}
You can also prepare personalized domain data in the above format to fine-tune the model.
After downloading, extract AdvertiseGen.tar.gz into the AdvertiseGen folder under the ptuning directory where the model is located.
Open train.sh
PRE_SEQ_LEN=128
LR=2e-2
CUDA_VISIBLE_DEVICES=0 python3 main.py \
--do_train \
--train_file AdvertiseGen/train.json \
--validation_file AdvertiseGen/dev.json \
--prompt_column content \
--response_column summary \
--overwrite_cache \
--model_name_or_path THUDM/chatglm-6b \
--output_dir output/adgen-chatglm-6b-pt-$PRE_SEQ_LEN-$LR \
--overwrite_output_dir \
--max_source_length 64 \
--max_target_length 64 \
--per_device_train_batch_size 1 \
--per_device_eval_batch_size 1 \
--gradient_accumulation_steps 16 \
--predict_with_generate \
--max_steps 3000 \
--logging_steps 10 \
--save_steps 1000 \
--learning_rate $LR \
--pre_seq_len $PRE_SEQ_LEN \
--quantization_bit 4
| Keyword | Meaning |
|---|---|
| PRE_SEQ_LEN | Sets the length of the training sequence, the longer, the more memory required |
| LR | Learning rate |
| train_file | Location of the training dataset |
| validation_file | Location of the validation dataset |
| prompt_column | Input field corresponding to the prompt, matching the keyword in the json |
| response_column | Output field, corresponding to the keyword in the json |
| model_name_or_path | Path to the model storage |
| output_dir | Output path |
| per_device_train_batch_size | The larger the setting, the more memory required, training recognition can try smaller values; here it is set to 1 |
Then run:
bash train.sh
If you want to train based on dialogue corpus, you can use:
bash train_chat.sh
This command adds a history_column parameter to specify the field name for saving dialogue history, and some parameter numbers will change, for example, max_source_length will be set larger, as the dialogue sequence including history will be longer.
Previous Exciting Reads
👉Kaggle Competition Baseline Collection
👉Classic Paper Recommendation Collection
👉Must-Read AI Books
👉Experience Sharing for Undergraduate, Master, and Doctoral Studies