So far, we have discussed the architecture of Agent systems, how to organize the system into sub-Agents, and how to build a unified mechanism to standardize communication.
Today, we will turn our attention to the tool layer and one of the most important aspects you need to consider in Agent system design: data retrieval.
Data Retrieval and Agent RAG
It is possible to create Agent systems that do not require data retrieval. This is because some tasks can be accomplished using only the knowledge that your language model has been trained on.
For example, you could likely create an effective Agent to write books about historical events (such as the Roman Empire or the American Civil War).
For most Agent systems, providing data access is a key aspect of system design. Therefore, we need to consider several design principles surrounding this functional area.
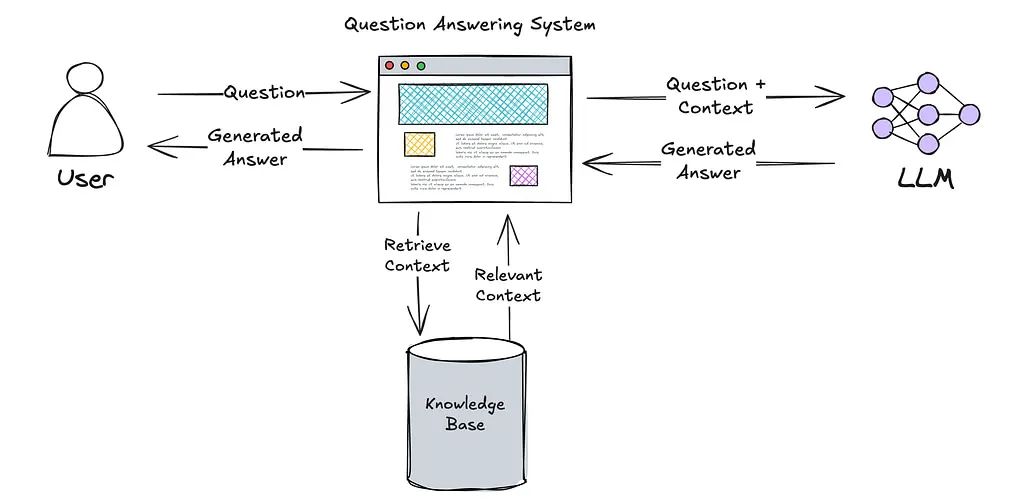
Retrieval-Augmented Generation (RAG) has become the de facto standard technology for connecting large language models (LLMs) to the data needed to generate their responses. As the name suggests, the general pattern for implementing RAG involves three steps:
Retrieval — Retrieve additional context from external knowledge bases. In this context, I use the term “knowledge base” broadly, which can include API calls, SQL queries, vector search queries, or any mechanism used to find relevant context to provide to the LLM.
Augmentation — The user’s input is augmented with the relevant context obtained in the retrieval step.
Generation — The LLM uses its pre-trained knowledge along with this augmented context to generate more accurate responses, even about topics and content it was never trained on.
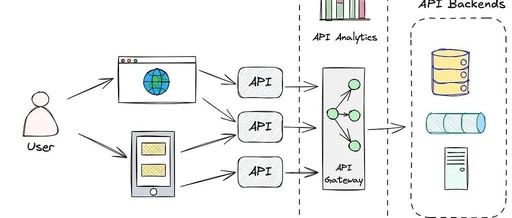
Thus, using RAG in a question-answering system looks roughly as follows:
Agent systems almost always require some implementation of RAG (Retrieval-Augmented Generation) to fulfill their duties. However, when designing Agent systems, it is important to consider how different types of data affect the overall system requirements.
Structured Data and APIs
Companies that have developed mature API projects will find it easier to find paths to value than those that have not. This is because most of the data needed to drive Agent systems is the same as the data used in non-Agent systems today.
A company that has built an API for generating insurance quotes is likely to find it easier to integrate that API into an Agent system than those still in the client/server era.
In fact, Agent systems are expected to disrupt almost every aspect of the insurance business. From quoting to underwriting, from actuarial science (the odds makers in insurance) to claims management, Agent AI is likely to completely take over these roles within the next 2-3 years. But this will only happen if Agent systems can access the right data and capabilities.
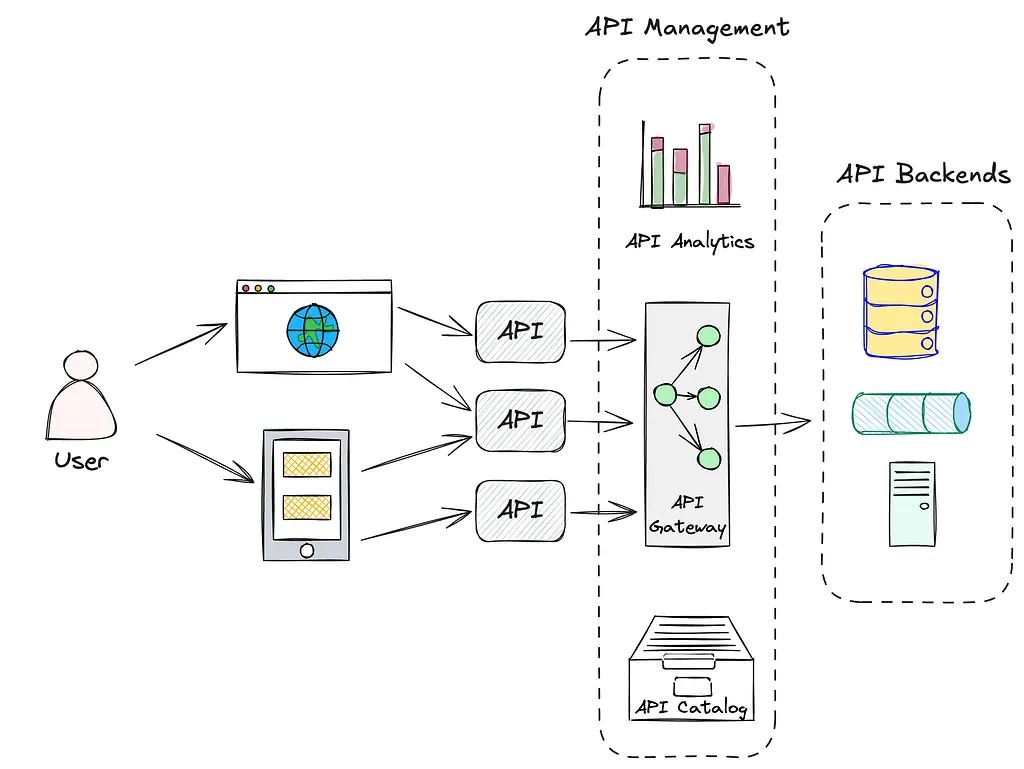
AI-Driven API Management
Many companies equate API management with having an API gateway. However, in the realm of Agent systems, OpenAPI (Swagger) has become a key driving factor for Agent systems to consume existing APIs. This is because the JSON schema used in OpenAPI can be easily converted into the function definition structures used by many large language model (LLM) providers.
Moreover, the service discovery mechanisms that allow Agent systems to find and discover APIs provide interesting opportunities for Agent systems to create emerging capabilities on their own. Depending on your perspective, this is either an exciting prospect or a frightening one.
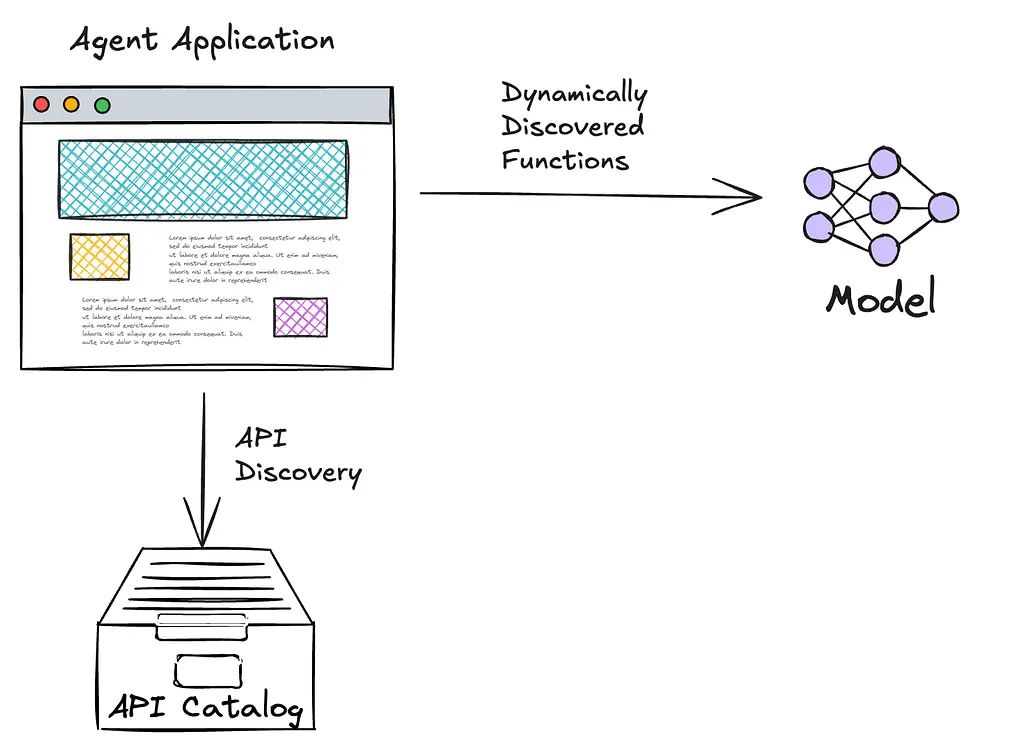
With appropriate security measures in place, it is even possible to expose API directory searches as an available feature to large language models (LLMs), allowing them to search for additional capabilities available to solve current tasks.
Unstructured Data and RAG
While most companies have mature practices for managing operational, analytical, and other types of structured data, unstructured data management often lags far behind.
Documents, emails, PDFs, images, customer service records, and other free-form text sources can be extremely valuable for Agent systems—provided that you can retrieve the right information at the right time and in the right format. This is where Retrieval-Augmented Generation (RAG) becomes particularly powerful.
Why Unstructured Data Is Challenging
The scope of unstructured data is often broader, and the formats are more diverse (PDF, images, plain text, HTML, etc.). This diversity can overwhelm simple data retrieval methods.

Unlike structured data stored in relational tables, unstructured data does not have a mandatory schema. You cannot simply run SQL queries on PDFs or perform direct “lookups” in spreadsheets.
This has driven the rapid adoption of new technologies to address these challenges.
Vector Databases and Semantic Search
Modern vector databases and semantic search technologies pave the way for large-scale retrieval of unstructured data. These systems convert text into high-dimensional vector embeddings, allowing for similarity-based lookups. User or agent queries are also converted into vectors, which then retrieve the closest vectors in the database (i.e., the most contextually similar text snippets).
Large documents are broken down into smaller “fragments,” each indexed separately. This allows the retriever to only retrieve relevant fragments instead of stuffing the entire document into a prompt.
Many vector databases allow you to attach metadata (e.g., author, date, document type) to each fragment. This metadata can guide downstream logic—e.g., only retrieving the latest product manuals or knowledge base articles relevant to user queries.
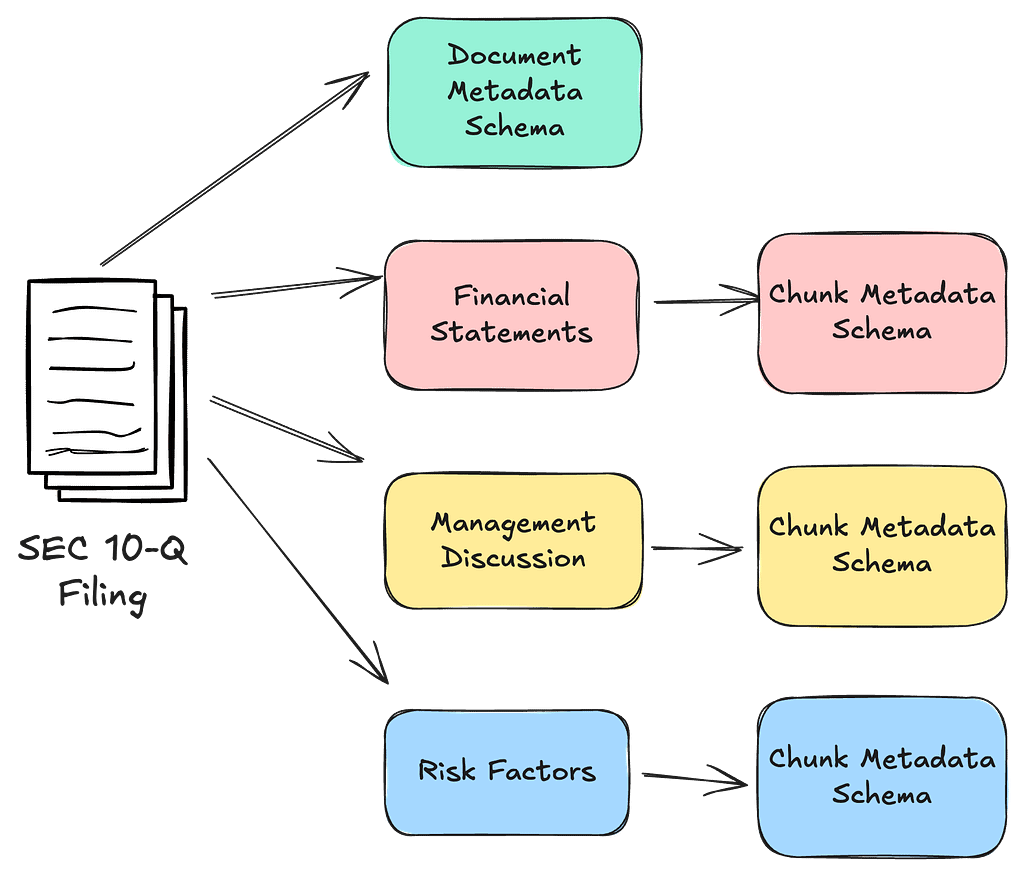
In high-traffic scenarios or cases where data quality is crucial (e.g., legal or medical use cases), you can apply additional filters and ranking criteria after semantic search to ensure that only the highest quality or domain-approved content is returned.
RAG Pipelines for Unstructured Data Processing
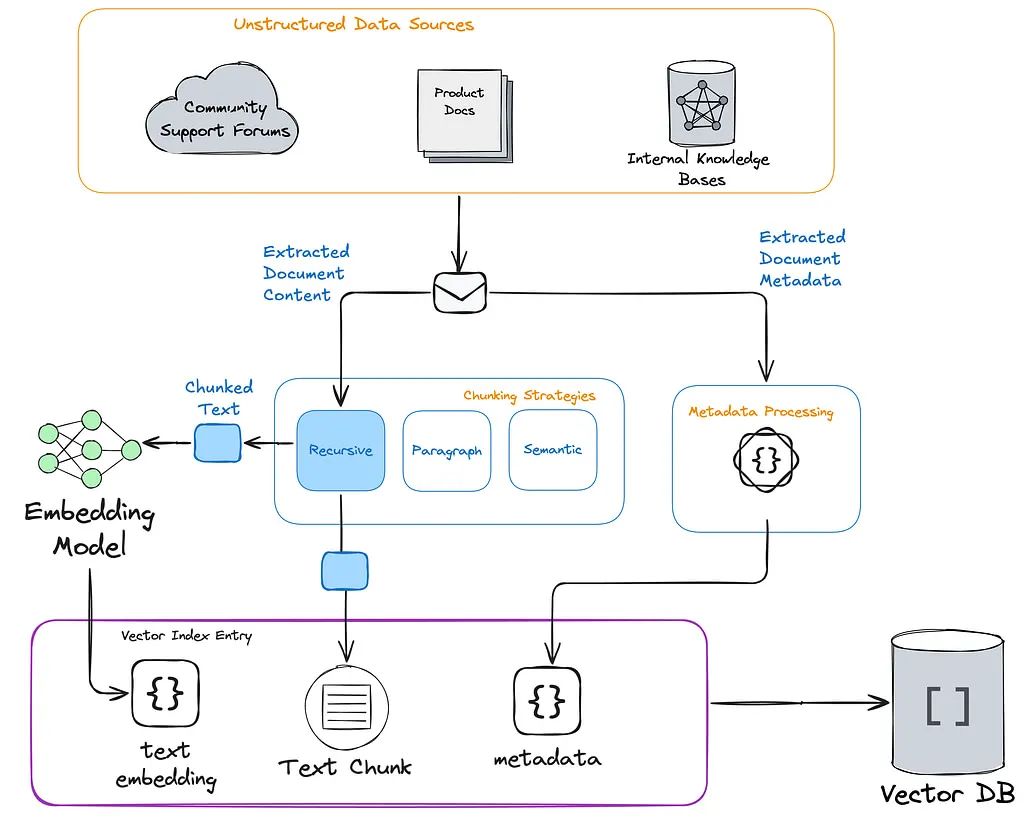
RAG pipelines serve as the connective organization between unstructured data sources and vector databases. They typically include several steps such as extraction, chunking, and embedding, transforming messy or free-form documents into optimized search indexes to provide relevant context for your large language model (LLM).
In the image below, you can see how data flows from various unstructured data sources. These may include knowledge bases, documents in file systems, web pages, content in SaaS platforms, and many other sources.
Within the RAG pipeline, unstructured data undergoes a series of transformations. These include extraction, chunking, metadata processing, and embedding (vector) generation, which are then written to a vector index. These pipelines provide the critical capability of supplying the most relevant information snippets when your LLM needs to answer questions or complete tasks.
Because unstructured data is often scattered across different data silos, keeping it synchronized and updated can be a challenge. In large enterprises, some unstructured data sources are in constant flux, meaning that RAG pipelines must capture and process these changes with minimal latency.
Outdated embeddings or stale text snippets can lead your AI system to provide inaccurate or misleading answers, especially when users seek the latest data on product updates, policy changes, or market trends. Ensuring that your pipelines can handle near-real-time updates—whether through event-driven triggers, periodic crawlers, or streaming data feeds—can significantly enhance the quality and credibility of system outputs.
Optimizing RAG Performance
Developers familiar with data engineering practices for building data pipelines are often unprepared for the non-deterministic nature of vector data.
In traditional data pipelines, we have a good understanding of the forms data should take in both source and target systems. For example, a set of relational tables in PostgreSQL may need to be transformed into a single flat structure in BigQuery. We can write tests to tell us whether the data in the source system has been correctly transformed into the representation we want in the target system.
When dealing with unstructured data and vector indexing, neither the source nor the target is very clear. Web pages and documents contain
What’s Next?
In the fifth and final part of this series, we will explore horizontal concerns. We will delve into important areas that Agent system designers need to consider, such as security, observability, and tool isolation.
Recommended Reading
-
Agentic AI System Design: Part 3 Inter-Agent Interaction
-
Agentic AI System Design: Part 2 Modularity
-
Agentic AI System Design: Part 1 Agent Architecture
-
Ant Group’s Distributed AI Agent Framework Built on Ray
-
Generative AI Application Creation Platform
-
Building Efficient Agents
👆👆👆Welcome to follow👆👆👆
Welcome to leave comments for discussion