Introduction to Open WebUI
Open WebUI (formerly known as Ollama WebUI) is a user-friendly web interface designed for Language Models (LLMs), supporting various LLM runners including Ollama and OpenAI compatible APIs. The project aims to provide users with an intuitive, responsive, fast, and easy-to-install chat interface.

Features of Open WebUI ⭐
-
• 🖥️ Intuitive Interface: Our chat interface is inspired by ChatGPT, ensuring a user-friendly experience.
-
• 📱 Responsive Design: Enjoy a seamless experience on both desktop and mobile devices.
-
• ⚡ Fast Response: Experience quick and responsive performance.
-
• 🚀 Easy Setup: Seamless installation using Docker or Kubernetes (kubectl, kustomize, or helm) for a hassle-free experience.
-
• 💻 Code Syntax Highlighting: Enjoy enhanced code readability through our syntax highlighting feature.
-
• ✒️🔢 Comprehensive Support for Markdown and LaTeX: Enhance your LLM experience with comprehensive Markdown and LaTeX features for richer interactions.
-
• 📚 Local RAG Integration: Dive into the future of chat interactions with groundbreaking Retrieval-Augmented Generation (RAG) support. This feature seamlessly integrates document interactions into your chat experience. You can load documents directly into the chat or easily add files to your document library, using the
#command in prompts for easy access. During its alpha phase, occasional issues may arise as we actively improve and enhance this feature to ensure optimal performance and reliability. -
• 🌐 Web Browsing Capability: Seamlessly integrate websites into your chat experience using the
#command followed by the URL. This feature allows you to directly incorporate web content into your conversations, enriching the depth and richness of your interactions. -
• 📜 Preset Prompt Support: Instantly access preset prompts using the
/command in chat input. Easily load predefined conversation starters to accelerate your interactions. Import prompts effortlessly through the Open WebUI Community[1] integration. -
• 👍👎 RLHF Annotations: Empower your messages with likes and dislikes, facilitating the creation of datasets for Reinforcement Learning from Human Feedback (RLHF). Utilize your messages to train or fine-tune models while ensuring the confidentiality of locally stored data.
-
• 🏷️ Conversation Tagging: Easily categorize and locate specific chats for quick reference and streamlined data collection.
-
• 📥🗑️ Download/Delete Models: Easily download or remove models directly from the web UI.
-
• ⬆️ GGUF File Model Creation: Easily create Ollama models by uploading GGUF files directly from the web UI. A simplified process provides options to upload GGUF files from your machine or download them from Hugging Face.
-
• 🤖 Multi-Model Support: Seamlessly switch between different chat models for diverse interactions.
-
• 🔄 Multi-Modal Support: Interact seamlessly with models supporting multi-modal interactions, including images (e.g., LLava).
-
• 🧩 Model File Builder: Easily create Ollama model files via the web UI. Create and add characters/agents, customize chat elements, and import model files effortlessly through the Open WebUI Community[2] integration.
-
• ⚙️ Multi-Model Conversations: Easily interact with multiple models simultaneously, leveraging their unique strengths for optimal responses. Enhance your experience by parallelly utilizing a diverse set of models.
-
• 💬 Collaborative Chat: Seamlessly organize group chats, leveraging the collective intelligence of multiple models. Use the
@command to specify models, enabling dynamic and diverse conversations within your chat interface. Immerse yourself in the collective intelligence woven into your chat environment. -
• 🔄 Regeneration History Access: Easily review and explore your entire regeneration history.
-
• 📜 Chat History: Easily access and manage your conversation history.
-
• 📤📥 Import/Export Chat History: Seamlessly move your chat data in and out of the platform.
-
• 🗣️ Voice Input Support: Interact with your models through voice; enjoy the convenience of direct conversations with models. Additionally, explore the option to automatically send voice inputs after 3 seconds of silence for a smoother experience.
-
• ⚙️ Fine Control of Advanced Parameters: Customize conversations to your specific preferences and needs by adjusting parameters like temperature and defining your system prompts for deeper control.
-
• 🎨🤖 Image Generation Integration: Enrich your chat experience with dynamic visual content using AUTOMATIC1111 API (local) and DALL-E seamlessly integrated for image generation capabilities.
-
• 🤝 OpenAI API Integration: Seamlessly integrate OpenAI compatible APIs for multifunctional conversations with Ollama models. Customize the API base URL to link with LMStudio, Mistral, OpenRouter, etc..
-
• ✨ Support for Multiple OpenAI Compatible APIs: Seamlessly integrate and customize various OpenAI compatible APIs to enhance the versatility of your chat interactions.
-
• 🔗 External Ollama Server Connection: Seamlessly connect to externally hosted Ollama servers at different addresses by configuring environment variables.
-
• 🔀 Load Balancing Across Multiple Ollama Instances: Easily distribute chat requests across multiple Ollama instances to enhance performance and reliability.
-
• 👥 Multi-User Management: Easily supervise and manage users through our intuitive management panel, streamlining user management processes.
-
• 🔐 Role-Based Access Control (RBAC): Ensure secure access by restricting permissions; only authorized individuals can access your Ollama, with exclusive model creation/pull permissions reserved for administrators.
-
• 🔒 Backend Reverse Proxy Support: Enhance security through direct communication between the Open WebUI backend and Ollama. This critical feature eliminates the need to expose Ollama on the LAN. Requests sent from the web UI to the ‘/ollama/api’ route will be seamlessly redirected from the backend to Ollama, enhancing the overall system security.
-
• 🌟 Continuous Updates: We are committed to improving Open WebUI through regular updates and new features.
Installation Guide
Open WebUI offers various installation methods, including Docker, Docker Compose, Kustomize, and Helm.
However, regardless of the installation method you use, you cannot bypass downloading the whisper model from huggingface.co, or you might run into errors and get stuck here:
RUN python -c "import os; from faster_whisper import WhisperModel; WhisperModel(os.environ['WHISPER_MODEL'], device='cpu', compute_type='int8', download_root=os.environ['WHISPER_MODEL_DIR'])"At this point, you will need this magical command:
ENV HF_ENDPOINT "https://hf-mirror.com"This command means to download the required models from the https://hf-mirror.com mirror instead of the official https://huggingface.co.
If you want to speed up the npm and Python package installation process, you can do it like this:
RUN npm config set registry https://mirrors.huaweicloud.com/repository/npm/
RUN pip config set global.index-url https://mirrors.aliyun.com/pypi/simple/There are multiple options for pip mirrors; the speed may vary for each individual. Here are a few mirrors you can choose from:
https://pypi.tuna.tsinghua.edu.cn/simple
https://pypi.doubanio.com/simple/
https://mirrors.aliyun.com/pypi/simple/
https://mirrors.ustc.edu.cn/pypi/web/simpleThere are also several options for npm mirrors:
Taobao NPM mirror: https://registry.npm.taobao.org
Aliyun NPM mirror: https://npm.aliyun.com
Tencent Cloud NPM mirror: https://mirrors.cloud.tencent.com/npm/
Huawei Cloud NPM mirror: https://mirrors.huaweicloud.com/repository/npm/
NetEase NPM mirror: https://mirrors.163.com/npm/
USTC Open Source Mirror Station: http://mirrors.ustc.edu.cn/
Tsinghua University Open Source Mirror Station: https://mirrors.tuna.tsinghua.edu.cn/Choose a fast mirror according to your needs.
The modified Dockerfile:
# syntax=docker/dockerfile:1
FROM node:alpine as build
ENV NPM_REGISTRY "https://mirrors.huaweicloud.com/repository/npm/"
WORKDIR /app
# wget embedding model weight from alpine (does not exist from slim-buster)
RUN wget "https://chroma-onnx-models.s3.amazonaws.com/all-MiniLM-L6-v2/onnx.tar.gz" -O - | \
tar -xzf - -C /app
RUN npm config set registry ${NPM_REGISTRY}
COPY package.json package-lock.json ./
RUN npm ci
COPY . .
RUN npm run build
FROM python:3.11-slim-bookworm as base
ENV ENV=prod
ENV PORT ""
ENV OLLAMA_API_BASE_URL "/ollama/api"
ENV OPENAI_API_BASE_URL ""
ENV OPENAI_API_KEY ""
ENV WEBUI_SECRET_KEY ""
ENV SCARF_NO_ANALYTICS true
ENV DO_NOT_TRACK true
ENV HF_ENDPOINT "https://hf-mirror.com"
ENV PIP_REPO "https://mirrors.aliyun.com/pypi/simple/"
#Whisper TTS Settings
ENV WHISPER_MODEL="base"
ENV WHISPER_MODEL_DIR="/app/backend/data/cache/whisper/models"
WORKDIR /app/backend
# install python dependencies
COPY ./backend/requirements.txt ./requirements.txt
RUN pip3 config set global.index-url ${PIP_REPO}
RUN pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cpu --no-cache-dir
RUN pip3 install -r requirements.txt --no-cache-dir
# Install pandoc and netcat
# RUN python -c "import pypandoc; pypandoc.download_pandoc()"
RUN apt-get update \
&& apt-get install -y pandoc netcat-openbsd \
&& rm -rf /var/lib/apt/lists/*
# RUN python -c "from sentence_transformers import SentenceTransformer; model = SentenceTransformer('all-MiniLM-L6-v2')"
RUN python -c "import os; from faster_whisper import WhisperModel; WhisperModel(os.environ['WHISPER_MODEL'], device='cpu', compute_type='int8', download_root=os.environ['WHISPER_MODEL_DIR'])"
# copy embedding weight from build
RUN mkdir -p /root/.cache/chroma/onnx_models/all-MiniLM-L6-v2
COPY --from=build /app/onnx /root/.cache/chroma/onnx_models/all-MiniLM-L6-v2/onnx
# copy built frontend files
COPY --from=build /app/build /app/build
# copy backend files
COPY ./backend .
CMD [ "bash", "start.sh"]If you want to speed it up further, you need to configure the Docker and Debian mirrors.
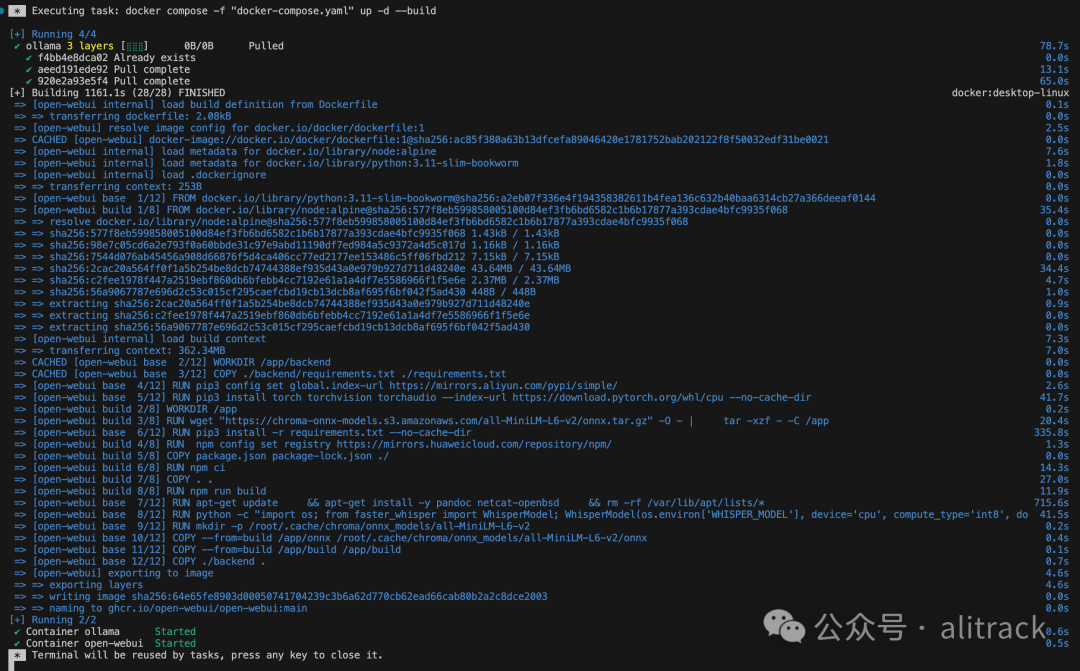
Manual Installation
If you are doing a manual installation, use the corresponding commands to set environment variables depending on your system:
-
• Linux/macOS
export HF_ENDPOINT=https://hf-mirror.com-
• Windows Powershell
$env:HF_ENDPOINT = "https://hf-mirror.com"-
• Windows CMD
set HF_ENDPOINT="https://hf-mirror.com"Reference Links
[1] Open WebUI Community: https://openwebui.com/[2] Open WebUI Community: https://openwebui.com/