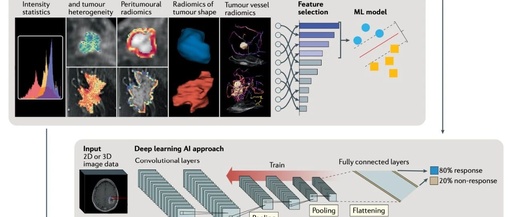
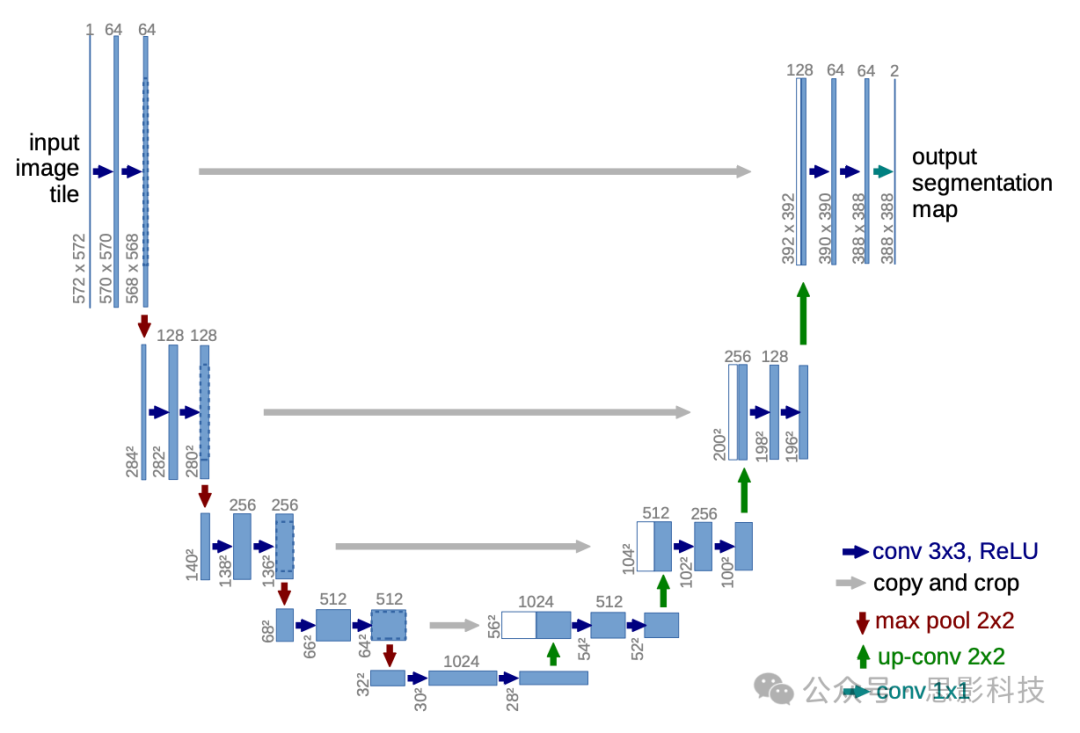
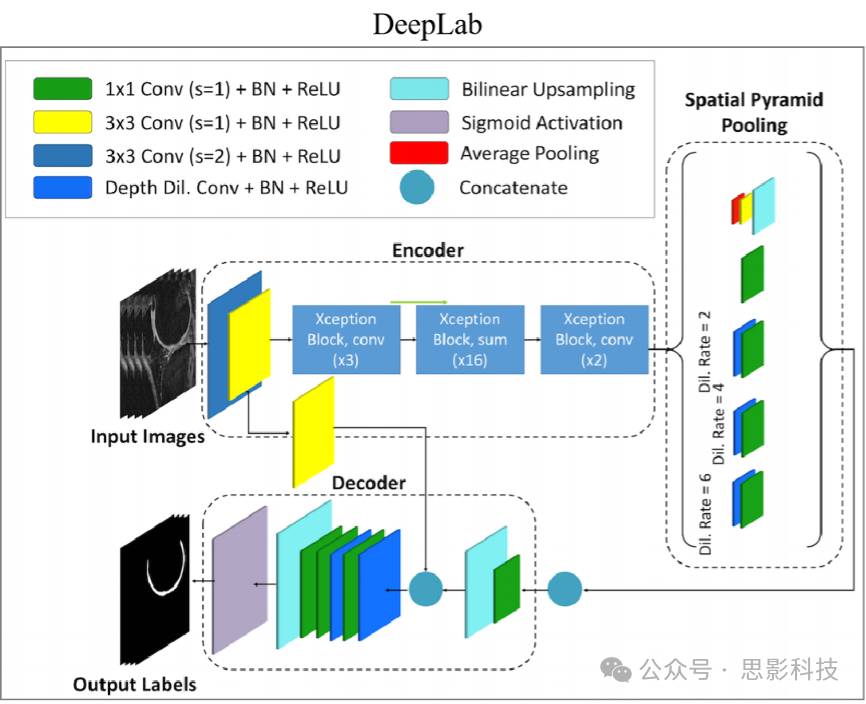
(1) U-Net: U-Net includes encoder and decoder parts, with downsampling, upsampling, and skip connections, used to refine the results of image segmentation. U-Net can be extended to U-Net++, V-Net, and 3D-Unet and other similar structures, all of which can be used for image segmentation.

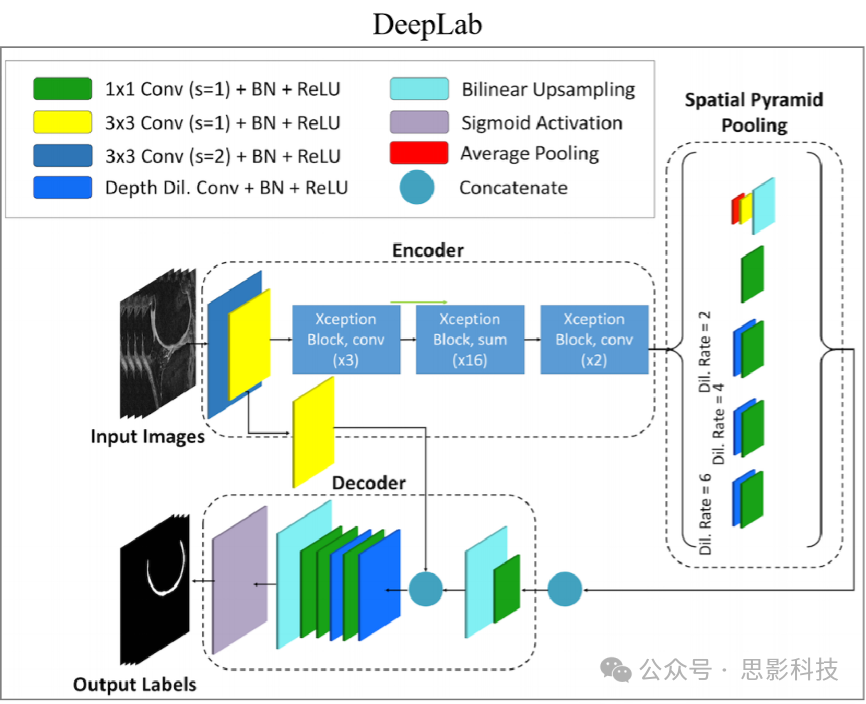
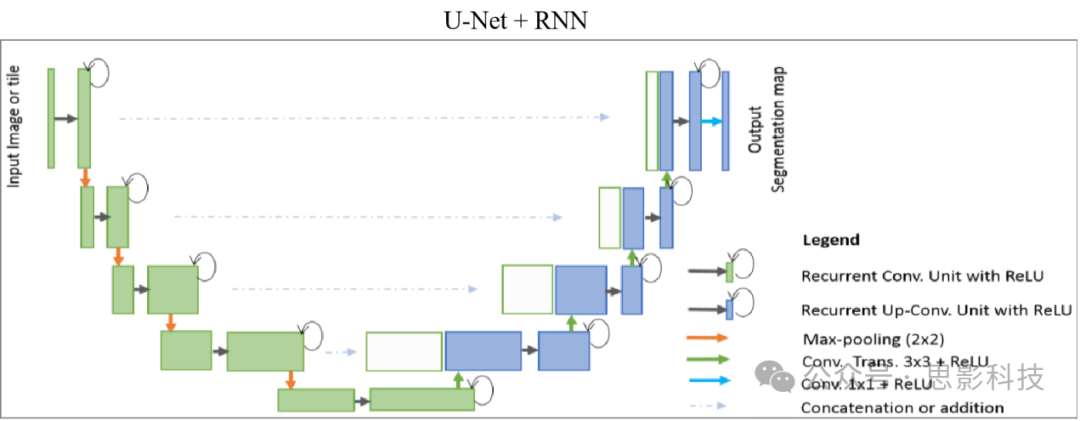
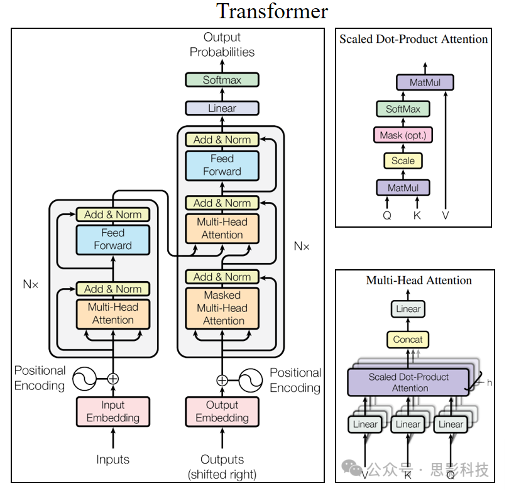
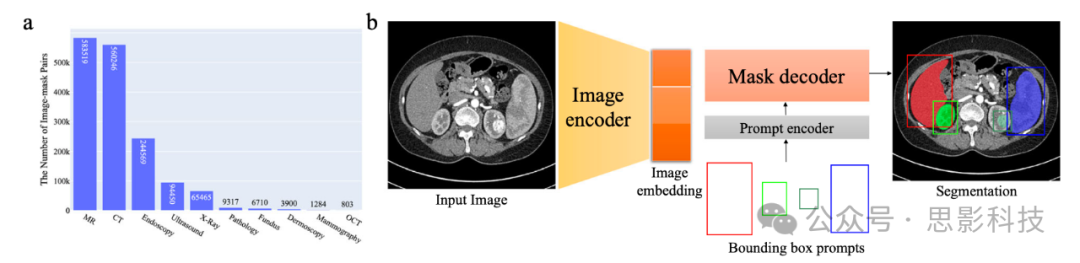
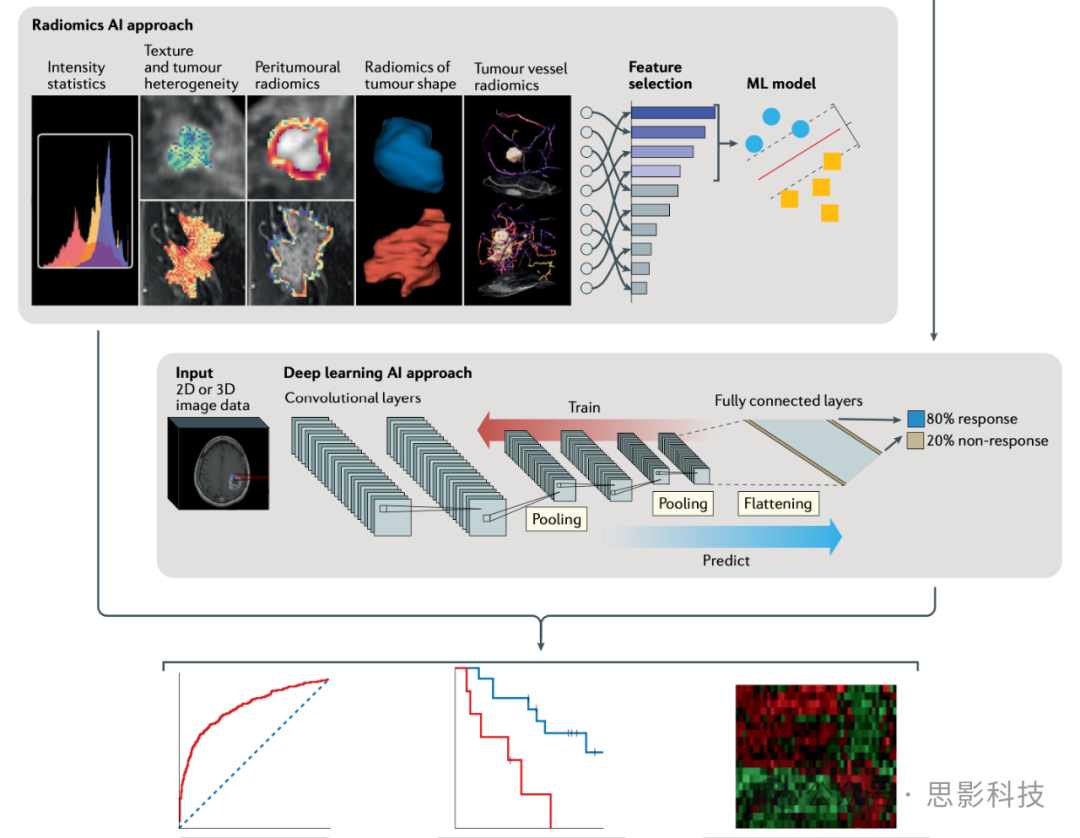
3. Feature Extraction and Selection
Unlike traditional radiomics that extracts various semantic and non-semantic features, deep learning-based radiomics can extract and select features through discriminative or generative models.
(1) Discriminative Models: Discriminative models typically extract class-discriminative features, allowing these models to directly predict instances from the extracted features. The main network models include:
① Convolutional Neural Networks (CNN): CNN combines convolutional layers, nonlinear activation functions, and pooling layers for automatic feature learning. Common models include:AlexNet, VGGNet, Inception, multilayer CNNs and others.
② Capsule Networks: Composed of convolutional layers and capsule layers, it can solve the problem of lost spatial relationship information associated with pooling layers.
③ Recurrent Neural Networks (RNN): RNN can handle sequential data such as CT or MR slices. Meanwhile, Long Short-Term Memory Networks (LSTM) can further solve the vanishing gradient problem of RNN.
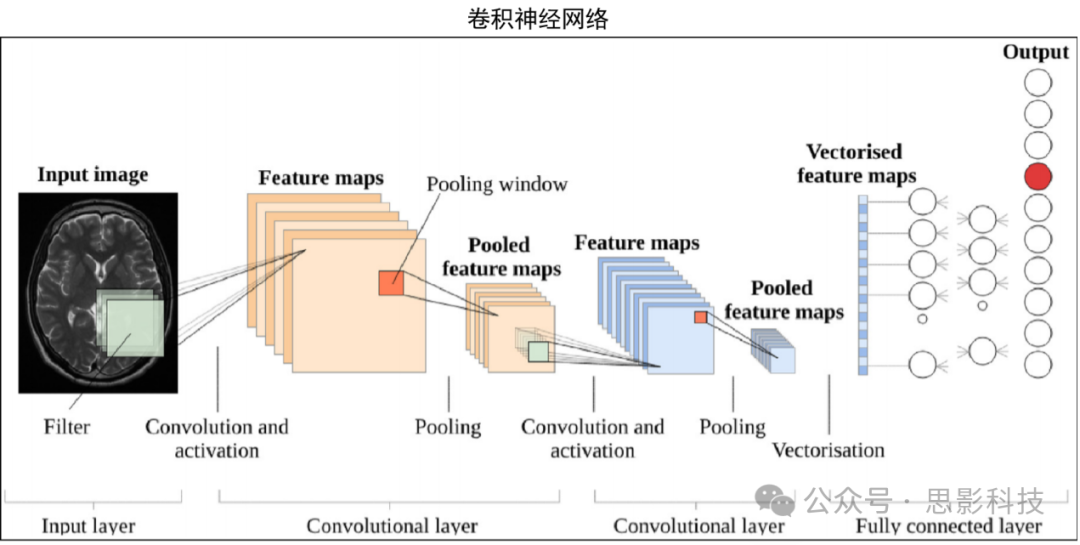
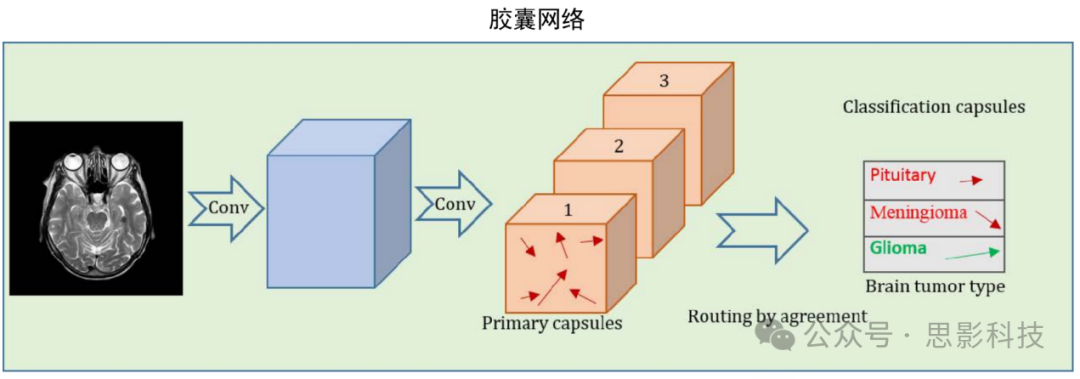
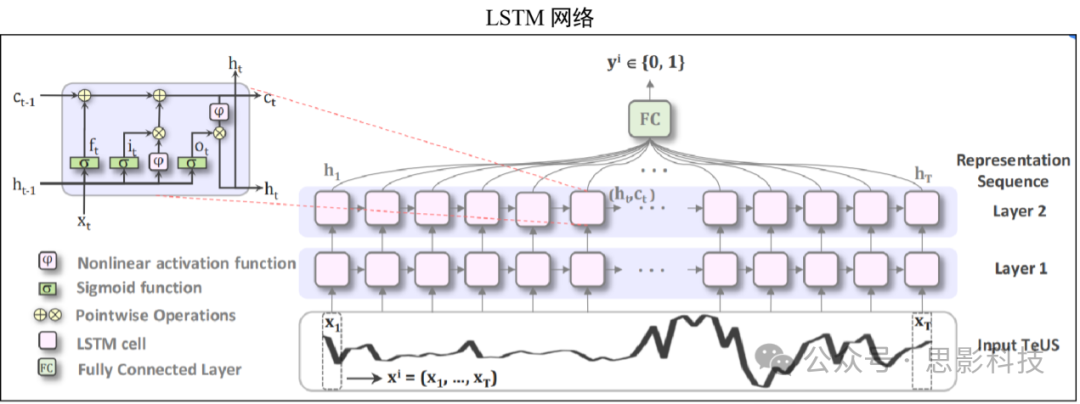
(2) Generative Models: The goal is to learn abstract and rich features from data distributions to generate new samples from the same distribution, mainly including the following network models:
① Auto-Encoder Networks: Auto-encoder networks consist of an encoder and a decoder, which can be trained end-to-end. Depending on the application, they can be extended to Denoising Autoencoders (DAEs), Convolutional Autoencoders (CAEs).
② Deep Belief Networks (DBN): Composed of stacked Restricted Boltzmann Machines (RBM), usually includes a visible layer and multiple hidden layers. DBN learns layered representations of data, capturing gradually abstract features of data.
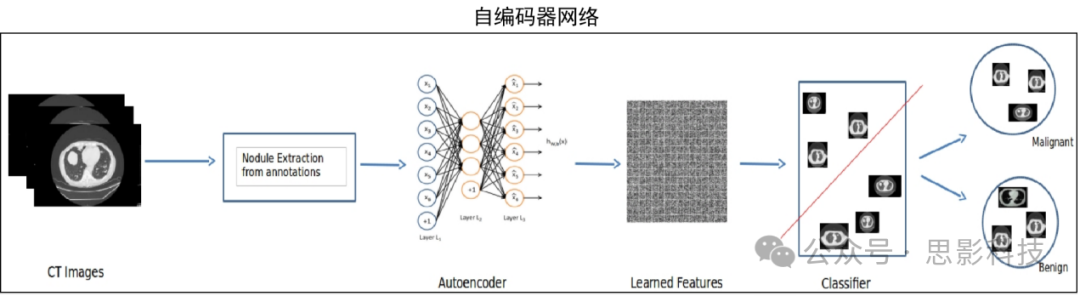
4. Model Establishment
The establishment of deep learning-based radiomics models is a dynamic and highly flexible process, depending on the application scenario and task requirements. Different models have advantages in different aspects, and selecting the appropriate model for fine-tuning is an efficient strategy.
|
Model |
Concept |
Features |
|
2D-CNN |
Focus on local areas by sliding convolution kernels over 2D image slices |
Suitable for analysis of static images and planar features |
|
3D-CNN |
Learn features directly in three-dimensional data without separating temporal and spatial information |
Effectively captures temporal and spatial depth information contained in fMRI data. |
|
RNN |
RNN can naturally model the temporal changes of each voxel |
Can capture long-term dependencies between data, suitable for tasks involving development and change |
|
Autoencoder |
Reproduce input data using the encoder-decoder structure |
Learn compressed representations of data, helping to extract the most important features |
|
CNN+Transformer |
CNN captures local features, Transformer captures global temporal dynamics |
Adaptively focuses on relationships between different areas in the input |
|
CNN+CRF |
Utilizes the advantages of CNN in feature learning, combined with CRF for spatial consistency modeling |
More accurate boundary delineation, reducing noise |
|
U-net |
Uses the encoder to capture contextual information of the input image, while the decoder is used to restore the spatial resolution of the image |
Maintains high-resolution features through skip connections, preserving more details in the segmentation results |
|
SegNet |
Effectively restores the details of the input image during the decoding process by passing index information to the deconvolution layers |
Relatively lightweight, suitable for real-time image segmentation tasks |
|
GANs |
Improves segmentation performance by alternating training of the generator and discriminator |
More detailed segmentation in complex structures and boundary regions, enhancing model generalization performance |
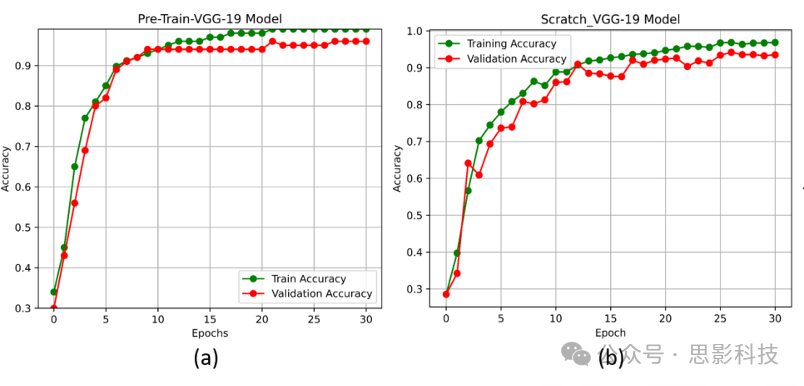
Fine-tuning: For routine tasks with a lot of existing work, models such as CNN, U-net, SegNet, etc., which have already been trained on large datasets, can be fine-tuned to complete tasks. Because pre-trained models have already learned low-level features that can be used for the proposed tasks, the time and data required to fine-tune pre-trained models are less than training a new model, making it easier to avoid overfitting during fine-tuning.
Many tasks can achieve satisfactory results by fine-tuning pre-trained models. If the pre-trained model performs poorly, or if the task is particularly complex and requires a higher level of performance, then considering designing a model yourself may be a reasonable choice.
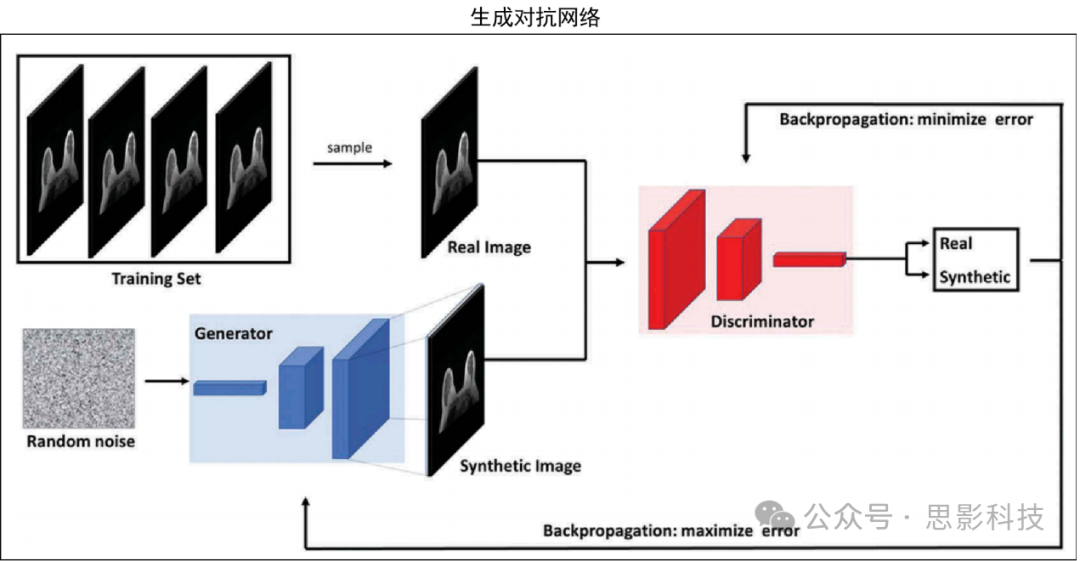
Multi-modal Data Analysis: Deep learning can handle multi-modal medical image data, such as fusing CT and MRI data. Data from different modalities provide complementary information, helping to understand disease states more accurately and providing a more comprehensive perspective for personalized medicine and disease diagnosis.
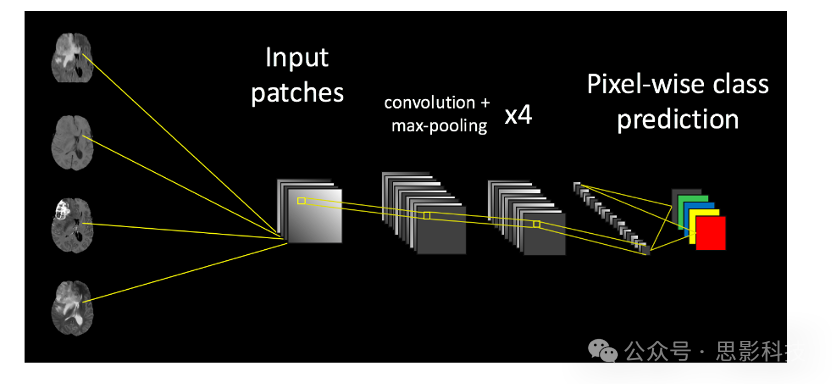
5. Result Reporting&Visualization
(1) Model Interpretability Analysis: In medical image segmentation tasks, interpretability analysis focuses on the decision-making process of the model, which is crucial for improving the model’s credibility, practical application, and clinical acceptance.
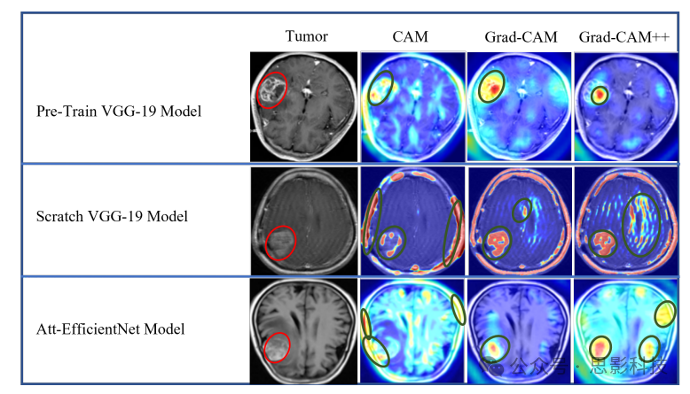
② LIME: Uses local models to explain the predictions of the original model. By generating a set of samples near the input data and then using a simple interpretable model to approximate the behavior of the original model, it helps to understand the decision-making process of the model.
③ Model Sensitivity Analysis: By modifying a small portion of the input data and observing the changes in model output, it analyzes the model’s sensitivity to input, which helps to understand the model’s attention to different parts of the input.
(2) Model Performance Evaluation: Qualitative and quantitative analyses aim to comprehensively evaluate the performance and applicability of segmentation models. The two analysis methods provide different perspectives for evaluating the effectiveness of segmentation algorithms and their adaptability to specific tasks.
① Quantitative Analysis: Evaluates the performance of segmentation models through numerical metrics. The Dice Coefficient is used to measure the overlap between the model’s segmentation results and the true segmentation results, serving as a commonly used performance metric for segmentation. IoU represents the proportion of the intersection of the model’s segmentation area to the union with the true segmentation area.
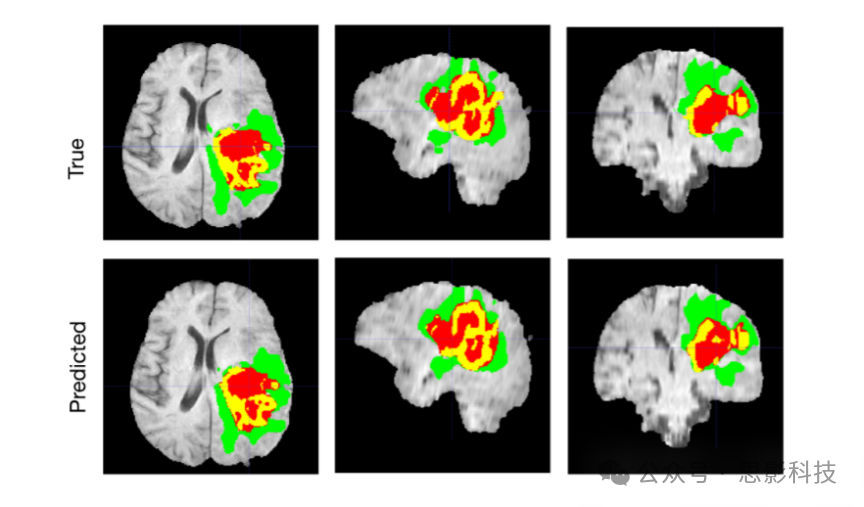
(3) Result Reporting:
For classification tasks: can report accuracy, sensitivity, specificity, area under the ROC curve (AUC), and 95% confidence intervals, and can plot ROC curves, decision curves, and calibration curves.
For regression tasks: can report mean squared error (MSE), mean absolute error (MAE), coefficient of determination (R-squared), root mean square error (RMSE), explained variance, and correlation coefficient, and can plot scatter plots of regression predictions against true values.
For segmentation tasks: in addition to IoU and Dice Coefficient, can also report pixel accuracy, mean accuracy, mean IoU, and boundary accuracy.

Welcome to browse Siyi’s data processing services and course introductions.(Please click the text below directly to browse all courses offered by Siyi Technology. Feel free to add WeChat ID19962074063 or 18983979082 for consultation. All courses are open for registration, and we will contact you as soon as you register, reserving spots for registered students):
Siyi Technology Functional Magnetic Resonance (fMRI) Data Processing Services