Deep learning has opened a new chapter in machine learning, and currently, there have been groundbreaking research advances in deep learning applications in image and speech. Deep learning has long been praised as an artificial intelligence algorithm similar to the structure of the human brain. So why has there been no substantial progress in the field of semantic analysis with deep learning?
To quote a netizen from three years ago:
“Steve Renals calculated the number of accepted paper titles containing deep learning for icassp and found 44 papers, while naacl had 0 papers. There is a saying that language (words, sentences, texts, etc.) belongs to the high-level cognitive abstract entities generated during human cognition, while speech and images belong to the lower-level raw input signals, so the latter two are more suitable for deep learning to learn features.”
In fact, as of now, research on Deep Learning in the NLP field has already torn a layer of mystery from the profound human language. Among the most interesting and fundamental aspects is “word vectors”.
1. Word Vectors
The first step in transforming natural language understanding problems into machine learning problems is to find a method to mathematically represent these symbols.The most intuitive and, so far, the most commonly used word representation method in NLP is One-hot Representation, which represents each word as a long vector. The dimension of this vector is the size of the vocabulary, with the vast majority of elements being 0, and only one dimension having a value of 1, which represents the current word.For example, “microphone” is represented as [0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 …] “Mike” is represented as [0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 …] Each word is a single 1 in a sea of 0s.This One-hot Representation, if stored in a sparse manner, will be very concise: that is, assigning a numeric ID to each word. For instance, in the earlier example, the microphone is noted as 3, and Mike as 8 (assuming starting from 0). If you want to implement this in programming, you can use a Hash table to assign a number to each word. This concise representation method, combined with algorithms like maximum entropy, SVM, CRF, etc., has effectively completed various mainstream tasks in the NLP field.Of course, this representation method also has an important problem: the phenomenon of “vocabulary gap”: any two words are isolated. From just these two vectors, you cannot see whether the two words are related, even synonyms like microphone and Mike are not spared.
2. Distributed Representation of Word Vectors
Since the aforementioned easily understood One-hot Representation of word vectors has such significant drawbacks, a word vector representation method is needed that can represent the word itself while also considering semantic distance. This is the Distributed Representation word vector representation method we will introduce next.
Distributed representation was first proposed by Hinton in 1986. It is a low-dimensional real-valued vector, typically looking like this:
[0.792, −0.177, −0.107, 0.109, −0.542, …]
Dimensions of 50 and 100 are quite common, of course, this vector representation is not unique.The biggest contribution of Distributed Representation is that related or similar words are brought closer together (does this remind you of the difference between ordinary hash and simhash? Interested students can refer to the blog “[Algorithm] Using SimHash for Massive Text Deduplication”). The distance between vectors can be measured using the traditional Euclidean distance or the cosine angle. Using this representation method, the distance between “Mike” and “microphone” is much smaller than that between “Mike” and “weather”. Ideally, the representations of “Mike” and “microphone” should be completely identical, but due to some people writing the English name “Mike” as “Mike”, the word “Mike” carries some semantic meaning of a person’s name, thus it will not completely match “microphone”.
Mapping words into a new space and representing them as continuous real-valued vectors is called “Word Representation” or “Word Embedding”. Since the 21st century, people have gradually transitioned from the original sparse representation of word vectors to the current dense representation in low-dimensional space. Using sparse representation often encounters the curse of dimensionality and cannot represent semantic information, failing to reveal the potential connections between words. The low-dimensional space representation method not only solves the curse of dimensionality but also excavates the relational attributes between words, thereby improving the semantic accuracy of the vectors.
3. Word Vector Models
a) LSA Matrix Decomposition Model
This method uses singular value decomposition from linear algebra, selecting the feature vectors corresponding to the larger singular values to map the original matrix into a low-dimensional space, thus achieving the goal of word vectors.
b) PLSA Latent Semantic Analysis Probability Model
This model re-examines the matrix decomposition model from a probabilistic perspective, deriving a word vector model equivalent to LSA from a statistical and probabilistic standpoint.
c) LDA Document Generation Model
This model uses Bayesian estimation statistical methods to represent documents with multiple topics according to the document generation process. LDA not only solves the synonym problem but also addresses the polysemy problem. Currently, methods for training LDA models include those based on EM and differential Bayesian methods in the original paper, as well as the Gibbs Sampling algorithm that appeared later.
d) Word2Vector Model
This algorithm, which has just gained popularity in recent years, trains an N-gram language model using neural network machine learning algorithms and calculates the corresponding vector for each word during the training process. This article will elaborate on the principles of this method.
4. Word2Vec Algorithm Concept
What is word2vec? You can understand it as an efficient algorithm model that represents words as real-valued vectors, which utilizes deep learning concepts to simplify the processing of text content into vector operations in K-dimensional vector space, where the similarity in vector space can represent the semantic similarity of text.
The word vectors output by Word2vec can be used for many NLP-related tasks, such as clustering, finding synonyms, and part-of-speech analysis, etc. If we think differently, treating words as features, then Word2vec can map features into K-dimensional vector space, seeking deeper feature representations for text data.
Word2vec uses word vectors that are not the One-hot Representation type mentioned above, but rather the Distributed Representation type. The basic idea is to train to map each word into K-dimensional real-valued vectors (K is generally a hyperparameter in the model), and to judge their semantic similarity based on the distance between words (such as cosine similarity, Euclidean distance, etc.). It employs a three-layer neural network, consisting of an input layer, a hidden layer, and an output layer. A core technique is using Huffman coding based on word frequency, so that the content activated by similar frequency words in the hidden layer is basically the same; the more frequently a word appears, the fewer hidden layer activations it has, effectively reducing computational complexity. One reason for the popularity of Word2vec is its efficiency; Mikolov pointed out in his paper that an optimized single-machine version can train thousands of billions of words in a day.
This three-layer neural network itself models the language model, but also obtains a representation of words in vector space, and this side effect is the real goal of Word2vec.
Compared to the classical processes of Latent Semantic Analysis (LSI) and Latent Dirichlet Allocation (LDA), Word2vec utilizes the context of words, making the semantic information richer.
Word2Vec actually consists of two different methods: Continuous Bag of Words (CBOW) and Skip-gram. CBOW aims to predict the probability of the current word based on the context. Skip-gram does the opposite: predicting the probability of the context based on the current word (as shown in the figure below). Both methods utilize artificial neural networks as their classification algorithms. Initially, each word is a random N-dimensional vector. After training, the algorithm obtains the optimal vector for each word using either CBOW or Skip-gram methods.
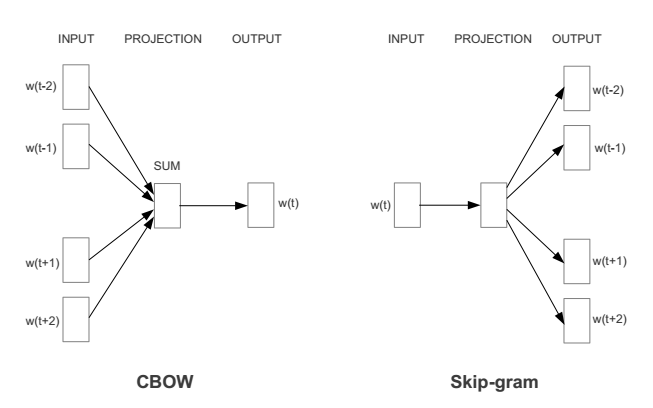
Take a suitable window size as the context, the input layer reads the words within the window, and their vectors (K dimensions, initially random) are summed together to form K nodes in the hidden layer. The output layer is a huge binary tree, where leaf nodes represent all the words in the corpus (if the corpus contains V independent words, then the binary tree has |V| leaf nodes). The algorithm for constructing this entire binary tree is the Huffman tree. Thus, for each leaf node representing a word, there will be a globally unique code, such as “010011”, where we can denote the left subtree as 1 and the right subtree as 0. Next, each node in the hidden layer will connect to the internal nodes of the binary tree, so each internal node of the binary tree will have K edges, each with a weight.
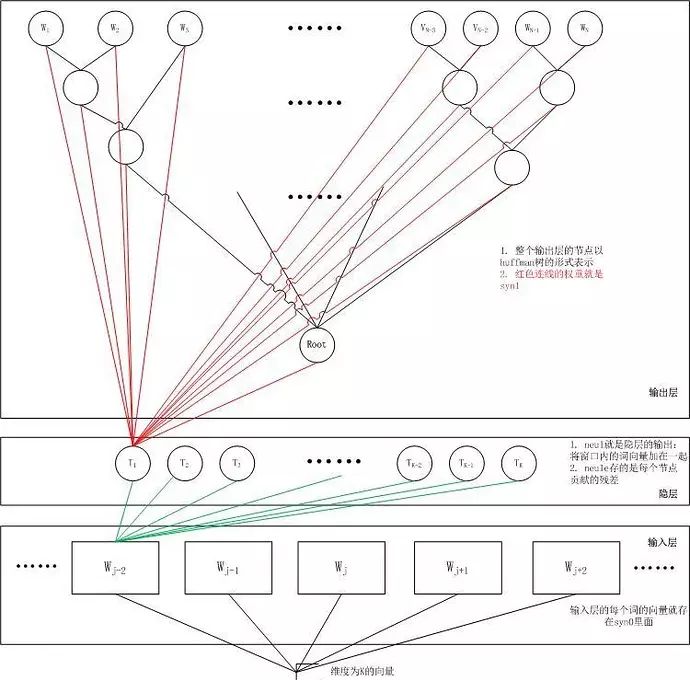
For a word w_t in the corpus, corresponding to a leaf node in the binary tree, it must have a binary code, such as “010011”. During the training phase, when given the context, we aim to predict the subsequent word w_t, we start traversing from the root node of the binary tree, and the goal here is to predict each bit of the binary number for this word. That is, for the given context, our goal is to maximize the probability of predicting the binary code for the target word. Visually, we hope that at the root node, the probability of the word vector and the connection to the root node yielding bit=1 is as close to 0 as possible, while in the second layer, we hope its bit=1 probability is as close to 1 as possible, and so on. We multiply the probabilities computed along the way to obtain the probability P(w_t) for the current word in the network, so the residual for this sample is 1-P(w_t), and we can use gradient descent to train this network to obtain all parameter values. It is evident that the probability value computed based on the binary code of the target word is normalized.
Hierarchical Softmax constructs a binary tree using Huffman coding, which actually utilizes the idea of approximating multi-class classification problems with a series of binary classifications. For instance, if we treat all words as outputs, then “orange” and “car” are mixed together. Given the context of w_t, the model first determines whether w_t is a noun, then whether it is food, then whether it is fruit, and finally whether it is “orange”.
However, during the training process, the model assigns these abstract intermediate nodes a suitable vector, which represents all its child nodes. Because the actual words share these abstract node vectors, the Hierarchical Softmax method is not equivalent to the original problem, but this approximation does not significantly degrade performance while significantly increasing the solvability of the model.
Without using this binary tree, but directly calculating the probability of each output from the hidden layer — that is, traditional Softmax, requires calculating for each word in |V|, leading to a time complexity of O(|V|). By using a binary tree (like the Huffman tree in Word2vec), the time complexity is reduced to O(log2(|V|)), greatly speeding up the process.
Now these word vectors have captured contextual information. We can use basic algebraic formulas to discover relationships between words (for example, “king” – “man” + “woman” = “queen”). These word vectors can replace bags of words to predict the sentiment of unknown data. The advantage of this model is that it not only considers contextual information but also compresses the data scale (usually, the vocabulary size is around 300 words instead of the previous models’ 100,000 words). Because neural networks can extract this feature information for us, we only need to do very little manual work. However, since the lengths of texts vary, we may need to use the average of all word vectors as input values for the classification algorithm, thus classifying the entire text document.
5. Doc2Vec Algorithm Concept
However, even if the above model averages the word vectors, we still ignore the influence of the order of words on sentiment analysis. The aforementioned word2vec is based on the dimensions of words for “semantic analysis” and does not have the capability for contextual “semantic analysis”.
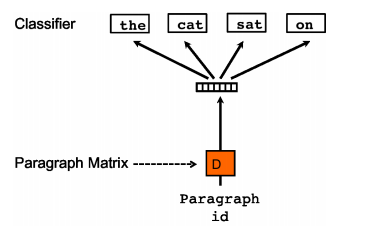
As a summarizing method for handling variable-length texts, Quoc Le and Tomas Mikolov proposed the Doc2Vec method. Besides adding a paragraph vector, this method is almost identical to Word2Vec. Like Word2Vec, this model also has two methods: Distributed Memory (DM) and Distributed Bag of Words (DBOW). DM attempts to predict the probability of words given the context and paragraph vector. During the training process of a sentence or document, the paragraph ID remains unchanged, sharing the same paragraph vector. DBOW predicts the probability of a set of random words in the paragraph given only the paragraph vector.
Below is a content excerpt from some methods of semantic analysis (part two)
First, let’s look at the c-bow method. Compared to the c-bow model of word2vec, the differences are:
-
During the training process, a paragraph ID is added, meaning each sentence in the training corpus has a unique ID. The paragraph ID, like ordinary words, is first mapped into a vector, which is the paragraph vector. The dimensions of the paragraph vector and word vector are the same but come from two different vector spaces. In subsequent calculations, the paragraph vector and word vector are summed or concatenated to serve as input to the output layer softmax. During the training process of a sentence or document, the paragraph ID remains unchanged, sharing the same paragraph vector, effectively utilizing the semantics of the entire sentence when predicting the probability of words.
-
During the prediction phase, a new paragraph ID is assigned to the sentence to be predicted, and the parameters of the word vector and output layer softmax remain unchanged from the training phase, reusing the gradient descent to train the sentence to be predicted. Once converged, the paragraph vector for the sentence to be predicted is obtained.
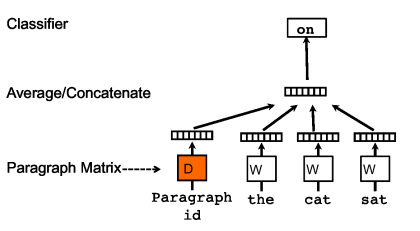
Sentence2vec, compared to the skip-gram model of word2vec, differs in that in sentence2vec, the input is the paragraph vector, and the output is a randomly sampled word from that paragraph.
Below are examples of results from sentence2vec. First, use Chinese sentence corpus to train sentence vectors, and then calculate the cosine values between sentence vectors to obtain the most similar sentences. It can be seen that the sentence vectors are quite impressive in representing the semantics of sentences.

6. Reference Content
1. Official Word2vec address: Word2Vec Homepage
2. Python version of word2vec implementation: gensim word2vec
3. Python version of doc2vec implementation: gensim doc2vec
4. A new method for sentiment analysis — based on Word2Vec/Doc2Vec/Python
5. Turning Data into Gold: some methods of semantic analysis (part two)
6. Wang Lin Introduction to Word2vec Principles