

Scan the QR code in the image to join the technology English live broadcast.
Students interested in Andrew Ng’s latest deep learning course can take a look at this article first.
Many people believe that machine learning is too specialized and has a high entry barrier. However, it has been proven that machine learning is a public, open, and active field. Those learning machine learning include not only professionals from computer science, artificial intelligence, and automation, but also many from finance, physics, materials, and even the arts, who can also master machine learning—the key lies in how to get started and how to quickly grasp the essence of machine learning.
Andrew Ng’s machine learning course has been available on the Coursera platform for about 5 years, with over 1.8 million enrollments. This course is an entry-level course for many machine learning enthusiasts and experts around the world. The entire course is thorough yet easy to understand.
On August 9th, Andrew Ng announced that deeplearning.ai has launched a new series of deep learning courses on Coursera, covering an overview of neural networks and deep learning, tuning and optimizing neural network parameters, how to build machine learning projects, convolutional neural networks, and recurrent neural networks. From the course setup, it covers both the basic theories and simple practical applications of deep learning. This is also the first project of the three major projects of deeplearning.ai.
It is said that the course was so popular that the deeplearning.ai website became inaccessible multiple times. Currently, the Chinese version of the course has been launched on NetEase Open Course on August 29. How is this course? What is the difficulty level? Is it really aimed at the general public as Andrew said? To clarify these questions, I personally tested 3 out of the 5 courses and scored each one based on difficulty and ease, highlighting the key points.
Now, let’s preview this course together with me.

Course 1
Rating: 4.8 out of 5
Conclusion: It would be perfect if a programming project designed entirely by oneself were added to this course! In short, “the most essential things are often the simplest.”
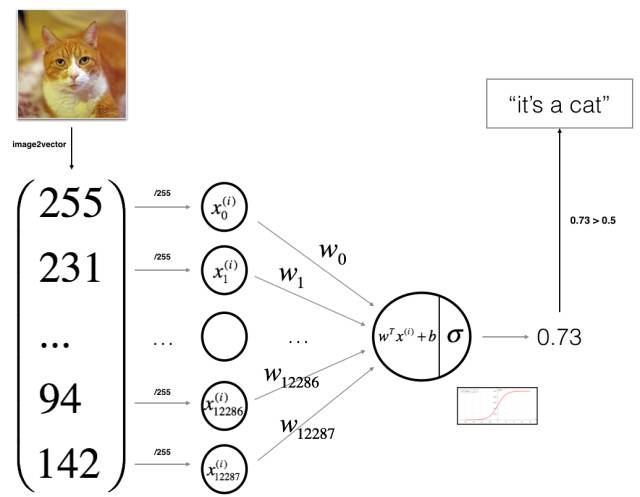
The first course is “Neural Networks and Deep Learning”. This course lasts for four weeks, and the video content includes the necessity of deep learning development, basic knowledge of neural networks, shallow neural networks, deep neural networks, and interviews with deep learning celebrities; programming assignments start with the most common functions from the Numpy library, then view logistic regression from the perspective of neural networks, train a neural network with only one hidden layer, and finally end with applications of deep neural networks.
During the learning process of this course, what I liked most was the design of the programming questions. I believe these designs are very helpful for learners to understand the model, capturing the essence of deep learning models and algorithms, and lowering the difficulty for learners to complete this course. This ensures that learners gain knowledge without undermining their confidence. This course is very suitable for beginners in machine learning; even if you are a novice in machine learning, as long as you can understand the basic probability and matrix operations and quickly learn Python programming, you can successfully complete the course with the programming guidance.
Course 2
Rating: 4.9
Conclusion: This course is very suitable for learners who have completed the first course and those who have a certain foundation in neural networks. I hope to add guidance on Tensorflow in the new round of courses.
The second course is “Improving Neural Networks: Tuning, Regularization, and Optimization”. This course lasts for three weeks, and the video content mainly includes how to avoid model overfitting, selecting appropriate optimization algorithms, choosing model hyperparameters, introducing the most popular deep learning frameworks, and interviews with deep learning celebrities. The programming part includes weight initialization, regularization methods, gradient checking (to verify whether the backpropagation algorithm is working correctly), different optimization algorithms, and implementing a multi-class project using the current most popular deep learning framework, Tensorflow.
This course continues the excellent tradition of the first course, with rich content, moderate difficulty, practicality, and helps to increase learners’ interest in deep learning (I still love its programming assignments the most; all programming assignments provide extremely clear answer hints, and you don’t need to write too much code to get the model running, which greatly reduces the difficulty of completing and understanding this course, enhancing your confidence in deep learning!).
Course 3
Rating: 4.7
Conclusion: This course is very suitable for learners who have completed the first course and those who have a certain foundation in neural networks. I hope to add guidance on Tensorflow in the new round of courses.
The third course is “Structuring Machine Learning Projects”. This course lasts for two weeks and is a feature of this specialized course, hoping that everyone building machine learning projects can learn from the experiences and lessons of predecessors to avoid detours! This course is not only aimed at novices in machine learning and deep learning but also at anyone confused in building machine learning systems. The latter part of this article is a simple summary of my experience after completing the third course of Andrew Ng’s deep learning specialization. If you are interested in machine learning and aspire to engage in research in machine learning and deep learning, I hope this summary will help you. If there are any shortcomings, I look forward to more exchanges and mutual progress!
To become an excellent machine learning engineer, you not only need to master the core algorithms of machine learning but also need to grasp the “basic” strategies of machine learning. So, what factors can ensure our machine learning systems work faster and more effectively? The experience summary provided in the third course is very valuable and is often not covered in deep learning courses at many universities. These experience summaries will guide you in building high-performance complex machine learning systems, saving time and cost.
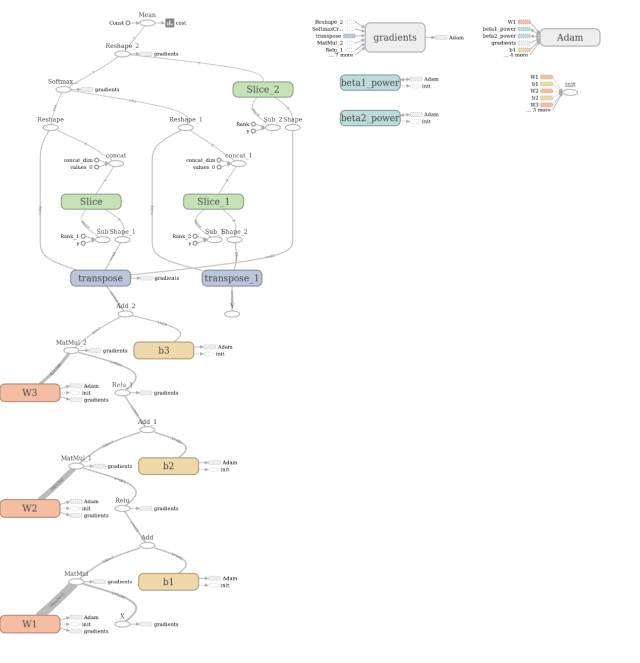
Note: This image is a deep neural network I built using Tensorflow after completing these three courses, used for classifying 62 different traffic sign objects. After 600 iterations, the accuracy is around 92%; before learning this course, I attempted to build a convolutional neural network and a deep neural network with three hidden layers to solve this problem, but after 600 iterations, the accuracy was less than 85% (this may be related to my different weight initialization in the neural network).
Imagine that when you have built a machine learning system with an accuracy of 90%, how should we further improve the system for practical applications? You may have many ideas: collect more training data; maintain the diversity of the training dataset; use larger neural networks; use different optimization algorithms; adopt dropout layers or use L2 regularization; change the architecture of the neural network, etc. Faced with so many choices, how should we decide? Which option is most likely to improve system performance? If your team spends nearly half a year collecting data only to find that more data is not the decisive factor in improving the system’s performance, you would have wasted a lot of precious time, just like your life.
Strategy 1: Orthogonalization Process
The biggest challenge in building machine learning systems includes tuning parameters, and during the tuning process, you have many choices. If time allows, you can try various approaches. However, experience shows that the most efficient machine learning practitioners know what methods are most effective, which brings us to the idea of orthogonalization. For example, an old television has many knobs on it, and you can adjust the picture in various ways. However, the most effective way to adjust is to ensure each knob has a specific function before making adjustments. Electronic engineers have spent a lot of time ensuring that each designed knob has a relatively interpretable function: one knob controls the height of the image, another controls the width, and others control the left-right position of the video, rotation, and translation—this setup ensures that people can manipulate the image more easily; if one knob controls all functions, it would be nearly impossible to adjust the television image. This is the design thinking of orthogonalization, which ensures that our operations are simple and interpretable. So, how does this relate to machine learning?
In building supervised machine learning systems, we also go through a similar process. First, we must ensure that our system performs well on the training set, then on the cross-validation set, and finally on the test set. If your algorithm does not perform well on the training set, you need a dedicated “knob” to solve this issue; this might require training a larger neural network or using a better optimization algorithm, such as the Adam optimization algorithm; if your system performs poorly on the cross-validation set, you also need to develop another set of orthogonalized “knobs” to solve this problem, which may require using a larger training set to help your machine learning algorithm generalize better to the cross-validation set; if your system performs well on the cross-validation set but poorly on the test set, what should you do? In this case, you should adjust the knobs to obtain a larger cross-validation set; if your system performs well on the test set but the user experience is poor, it means you may need to go back and reselect the cross-validation set or cost function.
In building high-performance machine learning systems, we should be clear about which module is problematic and take different measures for these different modules. The construction of machine learning systems should fully consider the concept of orthogonalization, ensuring that each process and each function is independent, with interpretable functionality.
Strategy 2: Determine a Single Model Performance Evaluation Metric and Select Appropriate Training, Cross-Validation, and Test Sets
Whether you are tuning hyperparameters, trying different learning algorithms, or using different machine learning models, you need to determine a performance evaluation metric for the model. With a performance evaluation metric, you can quickly assess whether new attempts are effective, which will accelerate your process of building machine learning systems. Applying machine learning requires rich experience; a good practice is to write code first, then run the code to see the experimental results and continue to improve your algorithm based on that. For example, you first establish a simple classifier A, and then by adjusting certain hyperparameters or other aspects in the model, you can train a new classifier B, and then evaluate the performance of your classifiers based on the performance evaluation metrics.
Using precision and recall to evaluate the performance of classifiers may be reasonable, but there may be a problem: classifier A has a higher precision, which means that classifier A’s predictions are more accurate; classifier B has a higher recall, which means that classifier B has a lower misclassification probability. So, which is better, classifier A or classifier B? Additionally, if you try many ideas and use different parameters, you will typically end up with more classifiers. How do you select the best classifier among these? At this point, it would be unreasonable to continue using two metrics to measure model performance, so the best approach is to consider precision and recall together, such as the F1 score, which is such a metric. Using this type of evaluation metric can accelerate the iteration process of machine learning.
Sometimes, we cannot only focus on precision, recall, or even the F1 score; we need to consider more limiting factors in training machine learning systems, such as time and money. In this case, a single performance evaluation metric may not meet our needs. More generally, we need to identify the most reasonable optimization target among multiple objectives, treating other objectives or conditions as constraints, and then evaluate or calculate on the training, cross-validation, or test sets to select the optimal algorithm under the constraints.
The selection of training, cross-validation, and test sets has a huge impact on the construction of machine learning application products. So, how should we select these datasets to improve the efficiency of our team in developing machine learning systems? When training machine learning models, we often try many different ideas, train different models on the training set, then use the cross-validation set to validate your ideas and select a model. Continue training, improve your model on the validation set, and finally evaluate the model on the test set.
It has been proven that the cross-validation and test sets should come from the same data distribution. Once a single performance evaluation metric and cross-validation set are determined, machine learning teams can quickly innovate, try different ideas, run experiments, and select the best model. Therefore, it is recommended to shuffle the data evenly before splitting the datasets, then divide into cross-validation and test sets to ensure that the two datasets come from the same distribution.
It has also been proven that the selection of the scale of validation and test sets is changing the field of machine learning. You may have heard of one of the empirical rules in the field of machine learning, which is to divide all data into 70:30 for the training and test sets or to allocate 60% of the dataset for training, 20% for cross-validation, and 20% for testing. This was quite reasonable in the early field of machine learning, especially when the data volume was small.
However, in the modern field of machine learning, where datasets are extremely large, this 70/30 empirical rule no longer applies. If you have 1 million samples, it would be reasonable to select 98% as the training set, 1% as the cross-validation set, and the remaining 1% as the test set. This is because the 1% also contains 10,000 samples, which is sufficient for both the test and cross-validation sets. Therefore, in the process of modern large-scale data machine learning or deep learning, the division proportion of the test and cross-validation sets is far less than 20%. Additionally, deep learning algorithms require a large amount of data, so most of the data can be allocated to the training set. The purpose of using the test set is to validate the reliability of the final machine learning system, increasing your confidence in the overall performance of the machine learning system. Unless you need to measure the final performance of the system very accurately, your test set does not need millions of samples; thousands of data points are sufficient.
Strategy 3: Adjust Performance Evaluation Metrics and Cross-Validation/Test Sets
Selecting cross-validation sets and evaluation metrics is like shooting at a target. Many times, your project has already progressed to a certain point when you realize that you have selected the wrong target, just like misjudging the position of the target during the shooting process. Therefore, when building a machine learning system, the first step should be to determine the evaluation metrics, even if the established evaluation metrics are not necessarily the best, but you need to have this awareness; then apply the various steps in the orthogonalization process to ensure that the algorithm works well.
For example, you have established two classifiers A and B to recognize cats, and their classification error rates on the cross-validation set are 3% and 5%, respectively, but when you test your algorithm in practice, you find that classifier B performs better—this may be because the cross-validation set you selected contains high-quality cat images, while the machine learning application you are building has to deal with many low-quality cat images that are blurry and may contain various strange expressions. In this case, you need to change your cross-validation set to better reflect your actual situation.
In summary, if the current evaluation metrics and data cannot effectively address what you truly care about, it is a good time to change your evaluation metrics and/or cross-validation/test sets. This will help your algorithm better capture the information you care about; this is beneficial for determining the strengths and weaknesses of the algorithm, accelerating the iteration process of ideas, and improving algorithm efficiency.
Strategy 4: Compare System Performance with Human Performance to Determine Methods for Improving System Performance
We often find that when machine learning systems exceed human performance in certain aspects, the system’s performance improves rapidly; after surpassing human performance, progress becomes slow. Humans are very good at classification, recognizing things, listening to music, and reading comprehension. When the system’s performance exceeds human performance, humans can always use specific strategies to help improve the system’s performance. These strategies include using more labeled data; gaining insights from error analysis; conducting bias and variance analysis. When the system’s performance surpasses human performance, these strategies become less effective.
This is why it is important to compare the performance behavior of machine learning systems with that of humans, especially on tasks where humans excel.
A supervised machine learning system fundamentally needs to ensure two aspects to work properly: first, it should fit the training set well, achieving low bias; second, the trained system should have strong generalization ability, performing well on the cross-validation or test set, achieving low variance.
Before improving the performance of machine learning systems, it is essential to understand the differences between the training error of the machine learning system and human error and to determine whether there is high bias. To address high bias, several methods can be employed: using a larger neural network model; training for a longer time; using better algorithms such as ADAM, Momentum, NAG, Adagrad, Adadelta, RMSProp; adjusting the neural network architecture, including the number of layers, the way neurons are connected, the number of neurons, activation functions, and other hyperparameters. Then, compare the errors on the cross-validation or test set with those on the training set to determine whether there is high variance. The level of variance indicates whether your model has good generalization ability. When encountering high variance, several solutions can be applied: collecting more data to train the model; using regularization methods, including dropout, data augmentation, weight regularization, etc.; adjusting the neural network structure, etc.
Rating
I hope DT’s personal summary can help resolve some of your doubts in building machine learning systems, saving time and cost, and accelerating the process of building machine learning systems.
-End-

Technology English Live Broadcast is Online | Learn Technology English Daily with MIT Technology Review!
Click the “Read Original” button below to enter the Xiao E Tong live broadcast room
