Deep Learning 2.0: Extending the Power of Deep Learning to the Meta-Level
Author: Frank Hutter
https://www.automl.org/author/fhutter/Deep learning has been able to revolutionize learning from raw data (images, text, speech, etc.) by replacing handcrafted features from specific domains with features learned jointly for the specific task at hand. In this blog post, I propose to elevate deep learning to a new level while jointly (meta) learning other currently handcrafted elements of deep learning pipelines: neural architectures and their initialization, training pipelines and their hyperparameters, self-supervised learning pipelines, etc.
I call this new research direction Deep Learning 2.0 because
-
like deep learning, it replaces previous handcrafted solutions (but now at the meta level) with learned solutions,
-
it allows automated customization for the task at hand with a significant quality leap, and
-
it allows automatic discovery of meta-level trade-offs with user-specified objectives, such as algorithmic fairness, interpretability, calibration of uncertainty estimates, robustness, energy consumption, etc. Thus, it can enable trustworthy AI through design, opening new horizons for deep learning in terms of quality.
From Standard Deep Learning to Deep Learning 2.0
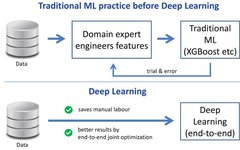
Let me first discuss why deep learning succeeded in the first place. Before deep learning, the traditional practice in machine learning was to perform feature engineering on the data at hand by domain experts, after which traditional machine learning methods, such as XGBoost (see the top of the figure below), could be applied.
By jointly optimizing the features and the classifiers learning on those features end-to-end, this can save manual effort and yield better results. The success of deep learning is an example where manually created components have been replaced by automatically generated components with better performance throughout the history of AI[ Clune, 2019,Sutton, 2019].
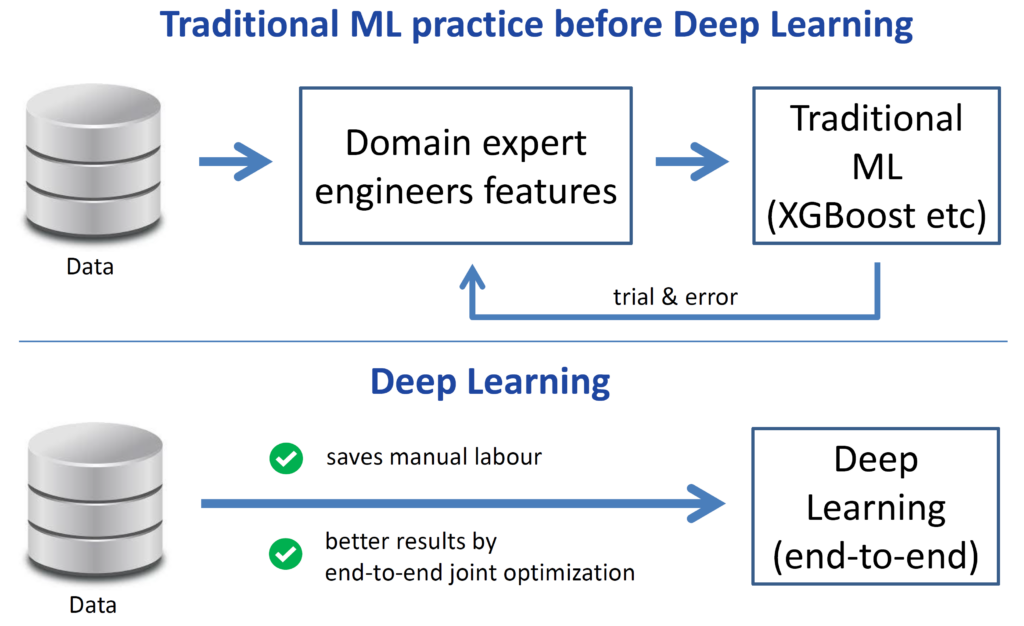
https://arxiv.org/abs/1905.10985http://www.incompleteideas.net/IncIdeas/BitterLesson.htmlMy proposal for deep learning 2.0 is to repeat this success at the meta level. Deep learning has eliminated the need for manual feature engineering, but it has actually replaced it with manual architecture and hyperparameter engineering by DL experts. Like feature engineering, this is a tedious trial-and-error process. To transition from this state, which I call “Deep Learning 1.0,” to Deep Learning 2.0, we once again bypassed this manual step, yielding the same advantages of deep learning over traditional machine learning. See the illustration in the figure below.
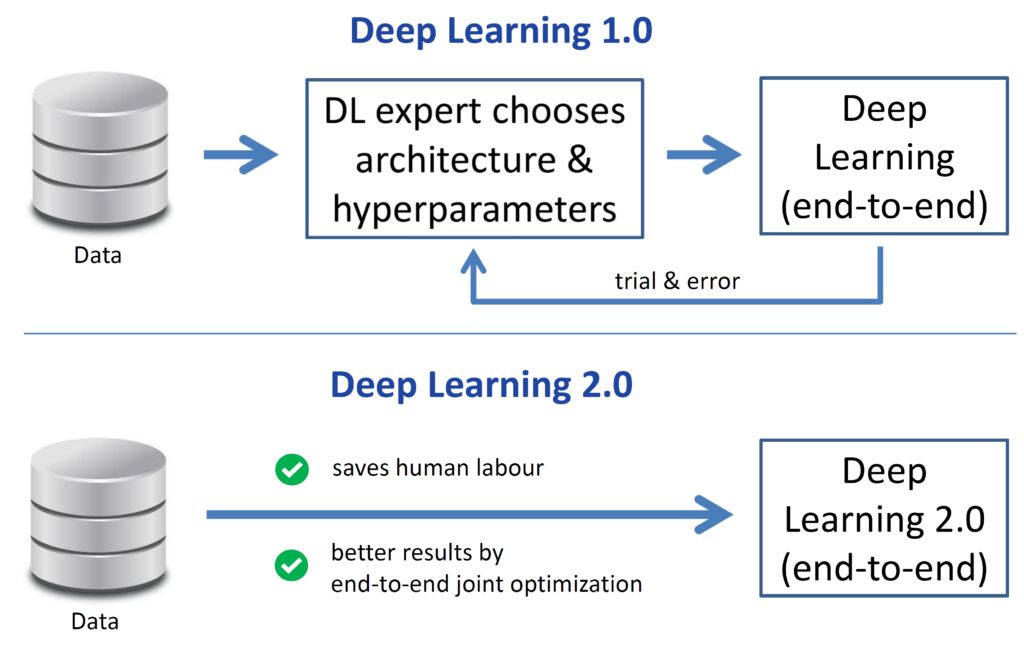
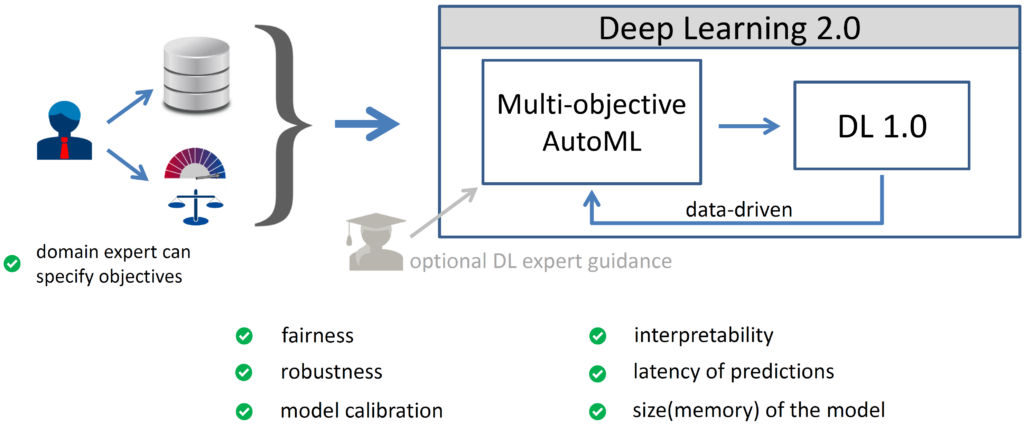
Deep Learning 2.0 can be realized through AutoML components that perform meta-learning and optimization on top of traditional foundational deep learning systems. But this is not the full picture of Deep Learning 2.0. In practice, we also often care about important additional objectives. That is why my vision for Deep Learning 2.0 includes allowing domain experts to specify the objectives they care about in specific applications. For example, policymakers can specify the correct algorithmic fairness standards in a specific application, and now multi-objective AutoML components can find instances of the underlying deep learning systems that yield Pareto fronts of non-dominated solutions. These can then be precisely optimized through design to meet the user’s objectives. Finally, I believe Deep Learning 2.0 should also help DL experts and collaborate with them, enhancing rather than replacing them. See the illustration in the figure below.
The Three Pillars of Deep Learning 2.0
I currently see three pillars that need to come together for Deep Learning 2.0 to reach its full potential:
Pillar 1: Joint Optimization of Deep Learning Pipelines
As mentioned, the key to the success of deep learning is the automatic learning of features from raw data. Deep learning continuously learns abstract representations of raw data, all of which are jointly optimized in an end-to-end manner. The figure below shows an example from computer vision: before deep learning, researchers attacked different levels of this feature learning pipeline in isolation in different isolated steps, with some doing edge detection, some learning contours, some combining contours into object parts, and finally, some dedicated to object classification based on object parts. In contrast, deep learning jointly optimizes all these components by optimizing the weights of all connections across all layers to minimize a single loss function. Thus, it learns in a way that allows them to combine well to learn contour detectors in higher layers in a way that allows them to combine well to allow powerful final classifications. All end-to-end and jointly orchestrated.
At the meta level of deep learning, our current situation resembles the foundational level before deep learning: different researchers independently study various components of deep learning, such as architectures, weight optimizers, regularization techniques, self-supervised learning pipelines, hyperparameters, etc. Deep Learning 2.0 proposes to jointly optimize these components to yield the best results from internal deep learning.
Pillar 2: Efficiency of Meta-Optimization
The success of deep learning is due to the efficiency of stochastic gradient descent (SGD) in solving optimization problems with millions to billions of parameters. Therefore, the success of Deep Learning 2.0 will largely depend on the efficiency of meta-level decision-making. Researchers have often used hyperparameter scanning or random search to enhance empirical performance, but these are insufficient to effectively search the qualitatively new joint space of meta-level decisions.
My personal goal is to develop a method that has an overhead of only 3 to 5 times that of standard deep learning when compared to using fixed meta-level decisions. More complex methods than grid and random search already exist, but they require substantial research effort to achieve this goal. The most promising methods fall into two categories:
-
Gradient-based methods. There has been much work in gradient-based neural architecture search, gradient-based initial network weight learning, gradient-based hyperparameter optimization, and gradient-based DL optimizer learning. These promise essentially zero overhead, for example, by alternating SGD steps at the meta level and SGD steps at the base level of network weights. However, they are also very fragile, often exhibiting common catastrophic failure modes, and require solving many research problems to make them as usable as powerful off-the-shelf DL optimizers.
-
Multi-fidelity optimization. Another promising approach is to extend complex black-box optimization methods, such as Bayesian optimization, with the capability of optimizing with different approximations of the cost function for inference, similar to Hyperband. Bayesian optimization and Hyperband have already been combined to produce an effective and powerful meta-level optimizer, but performance needs further improvement, requiring only costs equivalent to 3 to 5 times the evaluation of expensive cost functions.
Finally, tools need significant improvement, similar to the strong push of DL frameworks like TensorFlow and Pytorch, to make using complex meta-level optimization second nature for deep learning researchers.
Pillar 3: Direct Alignment with User Objectives through Multi-Objective Optimization
Compared to standard deep learning, Deep Learning 2.0 proposes to reintroduce human domain experts, allowing them to specify their own objectives. Then, DL 2.0 systems can automatically optimize for these objectives and provide Pareto fronts of possible non-dominated solutions for domain experts to choose from. For example, these user objectives could include any definition of algorithmic fairness, which can be specifically chosen for the current situation (realizing that “fairness” means very different things in one context than in another). Someone certainly needs to define which solution is better than another, but that person should not be some DL engineer responsible for implementing the system, but should be ethicists, policymakers, etc., who provide the objectives to be optimized without needing to know how the system works, but can audit the final solutions provided and choose the best trade-off for the situation at hand. I believe this direct alignment of optimization objectives with user objectives has the potential to enable trustworthy AI through design.
Deep Learning 2.0 is Underway
Deep Learning 2.0 builds on many components that have been developed over many years. Meta-learning is not a new concept, with pioneering work such as model-agnostic meta-learning to optimize the initial weights of neural networks and DARTS to optimize neural architectures. More novel is the joint optimization of multiple meta-level components. There has been much less work in this area, such as Auto-Meta and MetaNAS (both of which optimize neural architectures and their initial weights), Auto-PyTorch (jointly optimizing neural architectures and their hyperparameters), and SEARL (optimizing the neural architecture and hyperparameters of deep reinforcement learning agents).
Deep Learning 2.0 can draw on a lot of existing work in multi-objective optimization. Much of the work in neural architecture search has focused on secondary objectives such as latency, parameter count, and energy consumption. Although these have not yet been associated with deep learning, there has already been some work in hyperparameter optimization that considers fairness as a secondary objective.
The existence of all these puzzle pieces makes Deep Learning 2.0 more feasible and potentially successful.
Key Takeaways
I believe Deep Learning 2.0 is the natural next step for deep learning. I believe it is destined to succeed because it will
-
save manpower and yield better results
-
harmonize many issues related to the credibility of deep learning;
-
democratize deep learning;
-
be more general than standard deep learning, thus supporting a significant expansion of the deep learning market, which is already worth billions.
Therefore, I encourage the deep learning community to strengthen their efforts on the three pillars of Deep Learning 2.0.