Author: Cat-Eating Fish Python @CSDN
Editor: 3D Vision Developer Community
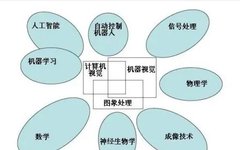
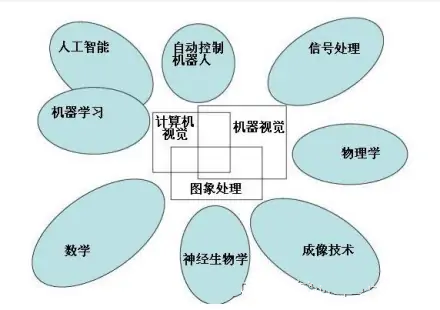
1. What is Computer Vision?
2. Basic Image Processing Operations
-
Image Processing: Read Image
-
Image Processing: Display Image
-
Image Processing: Save Image
3. Introduction to Image Processing Basics
4. Pixel Processing Operations
-
Shape
-
Number of Pixels
-
Image Type
7. Channel Splitting and Merging
1. What is Computer Vision?
Computer vision is a field that studies how to enable machines to “see”. More specifically, it refers to using cameras and computers to replace human eyes for tasks like recognition, tracking, and measurement, and further processing images to make them suitable for human observation or transmission to instruments for detection. As a scientific discipline, computer vision researches relevant theories and technologies, attempting to establish artificial intelligence systems capable of extracting ‘information’ from images or multidimensional data. The ‘information’ referred to here is defined by Shannon as information that can help make a “decision”. Since perception can be seen as extracting information from sensory signals, computer vision can also be viewed as the study of how to enable artificial systems to “perceive” from images or multidimensional data.
Vision is an inseparable part of various intelligent/autonomous systems in application fields such as manufacturing, inspection, document analysis, medical diagnosis, and military applications. Due to its importance, some advanced countries, such as the United States, classify research in computer vision as a major fundamental problem in science and engineering with widespread economic and scientific implications, known as a grand challenge.
The challenge of computer vision is to develop visual capabilities for computers and robots that are comparable to human levels. Machine vision requires modeling image signals, textures, and colors, geometric processing and reasoning, as well as object modeling. A capable visual system should integrate all these processes closely.
For students currently in school, learning about computer vision and machine learning is very useful, not only for their career prospects but also for writing related papers. Currently, knowledge related to computers has been integrated into various fields, including medicine (computer vision analysis of CT imaging), electrical engineering (using MATLAB and related fields for drawing), face recognition, and license plate recognition, etc. Moreover, for those interested in interdisciplinary studies, computer science can intersect with any field without barriers.
Due to my poor language skills and weak ability to organize language, we will stop here. In summary, computer vision, machine learning, and related computer knowledge are particularly important!
2. Basic Image Processing Operations
First, let’s look at a simple piece of code related to computer vision:
import cv2
img = cv2.imread('path') # 'path' refers to the image path
cv2.imshow('Demo', img)
cv2.nameWindow('Demo')
cv2.waitKey(0)
cv2.destroyAllWindows()
This code can display the image related to ‘img’ on the computer. Next, we will explain each step’s related operations.
Image Processing: Read Image
Related function:image = cv2.imread(file_path[, display_control_parameter])
File Name: Full path.
Parameters include:
cv.IMREAD_UNCHANGED: means the same as the original image.
cv.IMREAD_GRAYSCALE: means converting the original image to a grayscale image.
cv.IMREAD_COLOR: means converting the original image to a color image.
cv2.imread('d:\image.jpg', cv.IMREAD_UNCHANGED)
Image Processing: Display Image
Related function: None = cv2.imshow(window_name, image_name)
cv2.imshow('demo', image)
However, in OpenCV, we still need to add related constraints for image display:
retval = cv2.waitKey([delay])
If this constraint is not added, the displayed image will flash and disappear, resulting in an error.
Where the delay parameter includes:
delay = 0, waits indefinitely for image display until closed, which is also the default value of waitKey.
delay < 0, waits for a keyboard press to end the image display, meaning the image will stop displaying when we press a key.
delay > 0, waits for delay milliseconds before ending the image display.
Finally, we also need to display
to completely remove the image from memory.
Image Processing: Save Image
Related function: retval = cv2.imwrite(file_path, file_name)For example:
cv2.imwrite('D:\test.jpg', img)
This saves ‘img’ to the path D:\test.jpg
3. Introduction to Image Processing Basics
Introduction to Imaging Principles
The first concept we need to deeply engrave in our minds is:
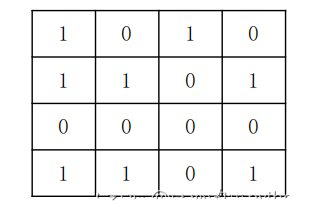
——Images are composed of pixels.
To illustrate this vividly:
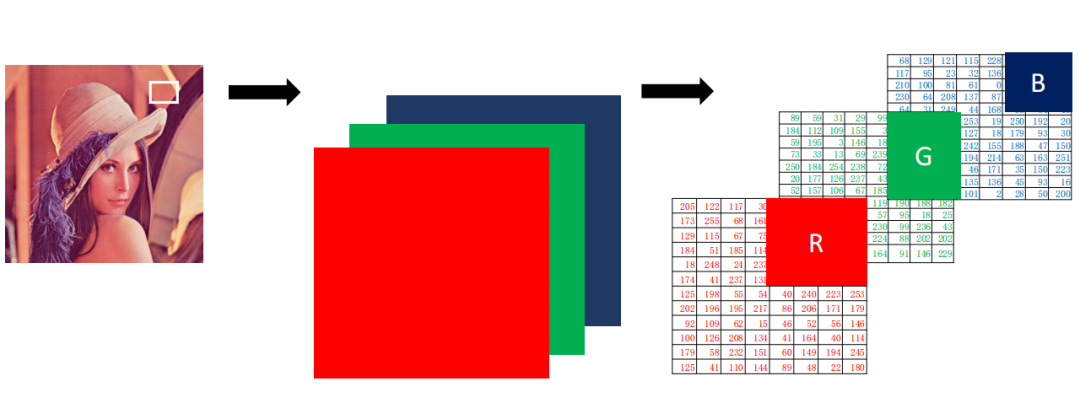
This perfectly demonstrates the imaging principle of computer images, which are constructed by colored pixels.
Images are generally classified into three categories:
1. Binary Image A binary image means that each pixel is composed only of 0 and 1, where 0 represents black and 1 represents white. Here, black and white are pure black and pure white. Thus, the images we see are like this. Let’s take the official website of Lina as an example.
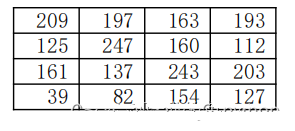
2. Grayscale Image A grayscale image is an 8-bit bitmap. What does this mean? It means from 00000001 to 11111111, which is the binary representation. If expressed in our commonly used decimal system, it is 0-255. Here, 0 represents pure black, and 255 represents pure white, with the colors in between being shades from pure black to pure white. Let’s still take Lina as an example.
All colors in a computer can be composed of R (red channel), G (green channel), and B (blue channel), where each channel consists of 0-255 pixel colors. For example, R=234, G=252, B=4 represents yellow. Therefore, the displayed color is yellow. Thus, a color image consists of three components corresponding to R, G, and B. Let’s still take Lina as an example:
Thus, we can conclude the complexity ranking as: color image – grayscale image – binary image. Therefore, in face recognition projects or license plate recognition projects, the most common operation is to convert color images to grayscale images and then convert grayscale images to the simplest binary images.
4. Pixel Processing Operations
Related function: return_value = image(position_parameters) We will first return the grayscale value using a grayscale image:
p = img[88, 142]
print(p)
Here we can return the grayscale value at the image coordinate [88, 142].
Then, as an example of a color image:
We know that a color image is composed of values from BGR three channels. Therefore, we need to return three values:
blue = img[78, 125, 0]
green = img[78, 125, 1]
red = img[78, 125, 2]
print(blue, green, red)
Thus, we have returned these three values.
Directly modify aggressively.
For grayscale images, img[88, 99] = 255
img[88, 99, 2] = 255, which can also be written as
img[88, 99] = [255, 255, 255], equivalent to the above.
Modify multiple pixel points
For example, still taking the color image as an example:
img[100:150, 100:150] = [255, 255, 255]
This means replacing the entire region from x-coordinates 100 to 150 and y-coordinates 100 to 150 with white.
Use Numpy in Python to Modify Pixel Values
Related function: return_value = image.item(position_parameters)
We use a grayscale image as an example:
For color images, we still have:
blue = img.item(88, 142, 0)
green = img.item(88, 142, 1)
red = img.item(88, 142, 2)
Then print(blue, green, red)
image_name.itemset(position, new_value)
We take a grayscale image as an example:
img.itemset((88, 99), 255)
img.itemset((88, 99, 0), 255)
img.itemset((88, 99, 1), 255)
img.itemset((88, 99, 2), 255)
import cv2
import numpy as np
img = cv2.imread('path', cv2.IMREAD_UNCHANGED)
print(img.item(100, 100))
img.itemset((100, 100), 255)
print(img.item(100, 100))
Through this piece of code, we can see the changes in pixel values. The same applies to color images.
Shape can retrieve the image’s shape, returning a tuple containing the number of rows, columns, and channels.
Grayscale images return the number of rows and columns; color images return the number of rows, columns, and channels.
import cv2
img1 = cv2.imread('grayscale_image')
print(img1.shape)
Size can retrieve the number of pixels in the image.
For grayscale images: number of rows * number of columns; for color images: number of rows * number of columns * number of channels.
dtype returns the image’s data type.
import cv2
img = cv2.imread('image_name')
print(img.dtype)
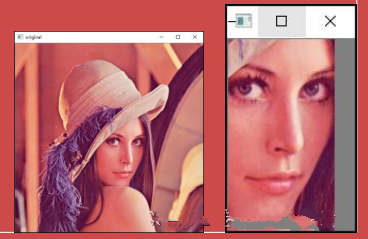
ROI (Region of Interest) indicates the area of interest.
-
Outline the area to be processed in the image with a box, circle, ellipse, or irregular polygon.
-
Can use various operators and functions to obtain the ROI and perform subsequent operations.
import cv2
import numpy as np
a = cv2.imread('path')
b = np.ones((101, 101, 3))
b = a[220:400, 250:350]
a[0:101, 0:101] = b
cv2.imshow('o', a)
cv2.waitKey()
cv2.destroyAllWindows()
We can also add the area of interest to another image.
7. Channel Splitting and Merging
import cv2
img = cv2.imread('image_name')
b = img[:, :, 0]
g = img[:, :, 1]
r = img[:, :, 2]
In OpenCV, we have a dedicated function for splitting channels: cv2.split(img)
import cv2
import numpy as np
a = cv2.imread('image\lenacolor.png')
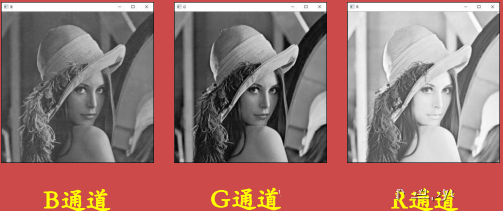
b, g, r = cv2.split(a)
cv2.imshow('B', b)
cv2.imshow('G', g)
cv2.imshow('R', r)
cv2.waitKey()
cv2.destroyAllWindows()
import cv2
import numpy as np
a = cv2.imread('image\lenacolor.png')
b, g, r = cv2.split(a)
m = cv2.merge([b, g, r])
cv2.imshow('merge', m)
cv2.waitKey()
cv2.destroyAllWindows()
We can merge the previously split image to get the following result:
Download 1: OpenCV-Contrib Extension Module Chinese Tutorial
Reply "Extension Module Chinese Tutorial" in the "Little White Learning Vision" WeChat public account backend to download the first OpenCV extension module tutorial in Chinese, covering installation, SFM algorithms, stereo vision, target tracking, biological vision, super-resolution processing, and more than twenty chapters of content.
Download 2: 52 Lectures on Python Vision Practical Projects
Reply "Python Vision Practical Projects" in the "Little White Learning Vision" WeChat public account backend to download 31 vision practical projects including image segmentation, mask detection, lane line detection, vehicle counting, eyeliner addition, license plate recognition, character recognition, emotion detection, text content extraction, face recognition, etc., to help quickly learn computer vision.
Download 3: 20 Lectures on OpenCV Practical Projects
Reply "20 Lectures on OpenCV Practical Projects" in the "Little White Learning Vision" WeChat public account backend to download 20 practical projects based on OpenCV for advanced learning.
Group Chat
Welcome to join the WeChat group for readers of the public account to communicate with peers. Currently, there are WeChat groups for SLAM, 3D vision, sensors, autonomous driving, computational photography, detection, segmentation, recognition, medical imaging, GAN, algorithm competitions, etc. (will gradually subdivide in the future). Please scan the WeChat ID below to join the group, and note: "Nickname + School/Company + Research Direction", for example: "Zhang San + Shanghai Jiao Tong University + Visual SLAM". Please follow the format; otherwise, you will not be approved. After successfully adding, you will be invited to join the relevant WeChat group based on your research direction. Please do not send advertisements in the group, or you will be removed. Thank you for your understanding~