Source: Data Analysis and Applications
1 Introduction
Our experience of the world is multimodal — we see objects, hear sounds, feel textures, smell odors, and taste flavors. A modality refers to the way something occurs or is experienced; when a research question involves multiple modalities, it has multimodal characteristics. For artificial intelligence to make progress in understanding the world around us, it needs to be able to interpret these multimodal signals simultaneously.
For example, images are often associated with labels and textual explanations, and text includes images to express the main idea of an article more clearly. Different modalities have very different statistical properties. This data is referred to as multimodal big data, which contains rich multimodal and cross-modal information, posing significant challenges to traditional data fusion methods.
In this review, we will introduce some pioneering deep learning models to fuse these multimodal big data. As exploration of multimodal big data increases, there are still challenges that need to be addressed. Therefore, this article reviews deep learning for multimodal data fusion, aiming to provide readers (regardless of their original community) with the fundamental principles of multimodal deep learning fusion methods and inspire novel multimodal data fusion technologies in deep learning.
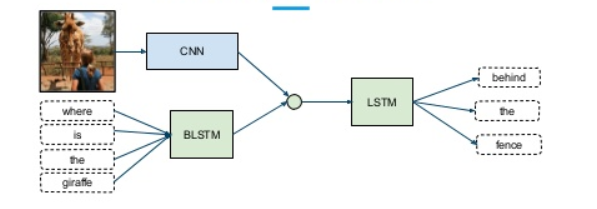
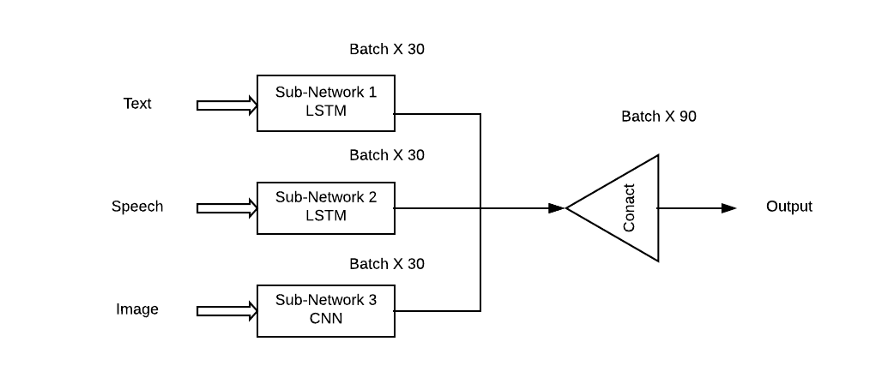
Using multimodal deep learning to combine different modalities or types of information to improve effectiveness is intuitively an attractive task, but in practice, how to combine different noise levels and conflicts between modalities is a challenge. Additionally, models have different quantitative effects on prediction results. The most common approach in practice is to concatenate high-level embeddings from different inputs and then apply softmax.
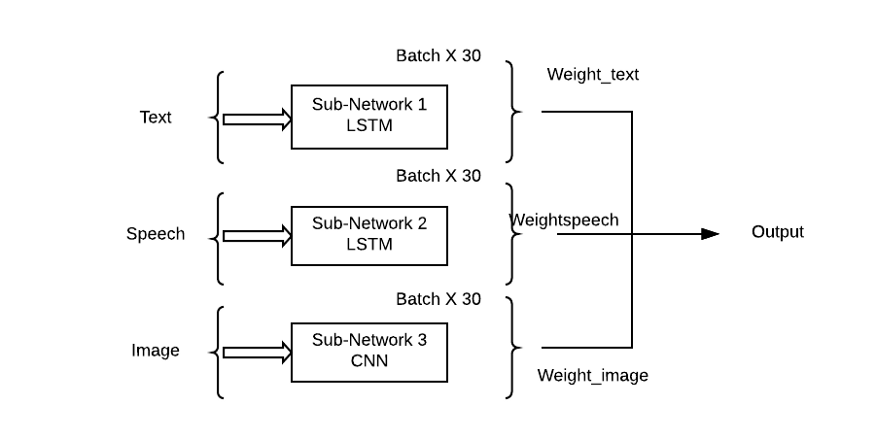
The problem with this approach is that it gives equal importance to all subnetworks/modalities, which is highly unlikely in real situations. Here, weighted combinations of subnetworks are needed so that each input modality can have a learning contribution to the output prediction (Theta).
2 Representative Deep Learning Architectures
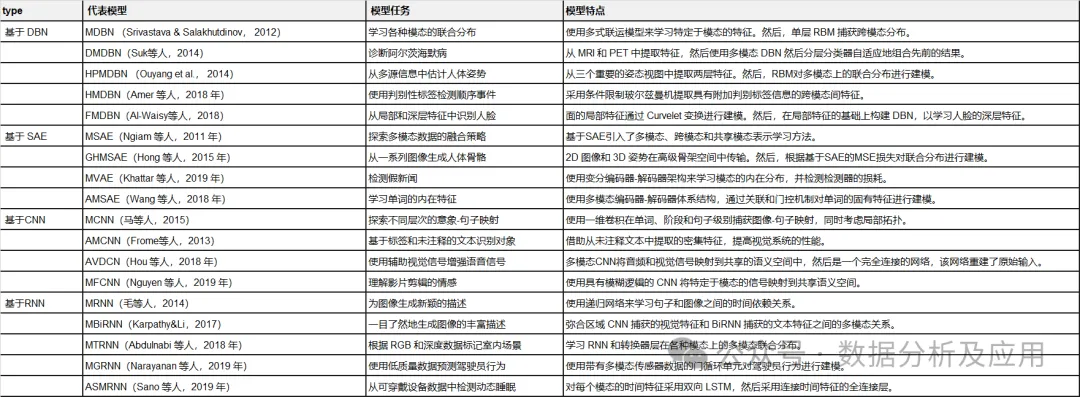
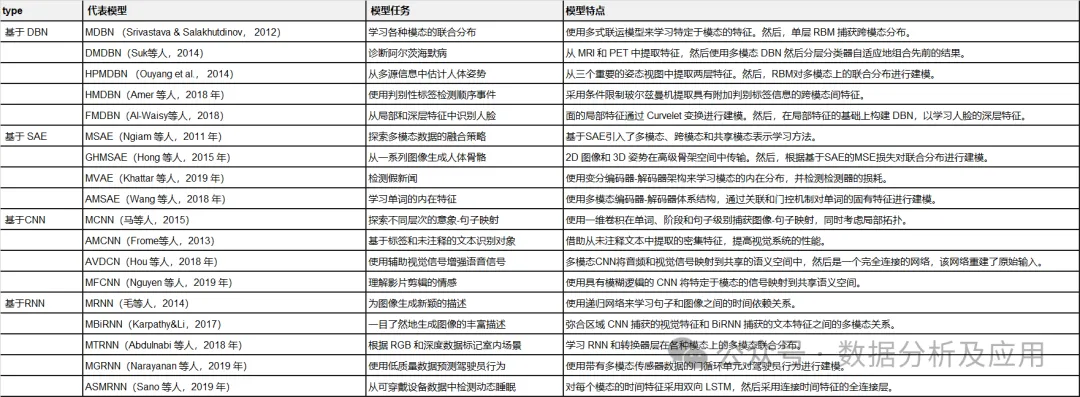
In this section, we will introduce the representative deep learning architectures for multimodal data fusion deep learning models. Specifically, the definitions, feedforward calculations, and backpropagation calculations of deep architectures are given, along with typical variants. Table 1 summarizes the representative models.
Table 1: Summary of Representative Deep Learning Models.
2.1 Deep Belief Network (DBN)
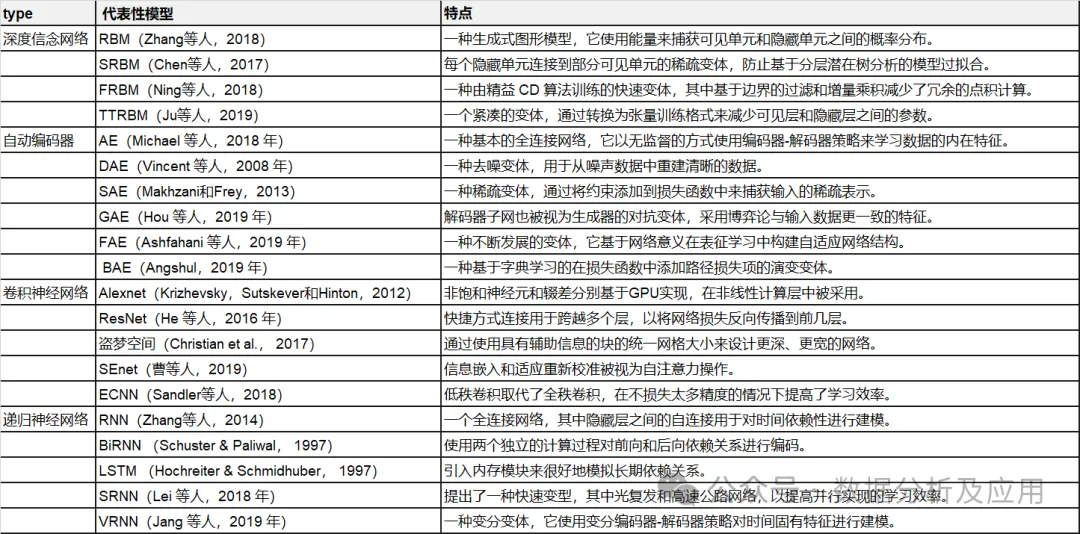
The Restricted Boltzmann Machine (RBM) is the basic building block of deep belief networks (Zhang, Ding, Zhang, & Xue, 2018; Bengio, 2009). RBM is a special variant of the Boltzmann machine (see Figure 1). It consists of a visible layer and a hidden layer; the units in the visible layer are fully connected to the units in the hidden layer, but there are no connections between units in the same layer. RBM is also a generative graphical model that uses an energy function to capture the probability distribution between visible and hidden units.
Recently, some advanced RBMs have been proposed to improve performance. For example, to avoid overfitting the network, Chen, Zhang, Yeung, and Chen (2017) designed a sparse Boltzmann machine based on a hierarchical latent tree learning network structure. Ning, Pittman, and Shen (2018) introduced a fast contrastive divergence algorithm to RBM, where boundary-based filtering and delta products are used to reduce redundant dot product calculations in computation. To protect the internal structure of multidimensional data, Ju et al. (2019) proposed tensor RBM, which learns high-level distributions hidden in multidimensional data, using tensor decomposition to avoid the curse of dimensionality.
DBN is a typical deep architecture composed of multiple stacked RBMs (Hinton & Salakhutdinov, 2006). It is a generative model based on pre-training and fine-tuning training strategies that can utilize energy to capture the joint distribution between visible objects and corresponding labels. In pre-training, each hidden layer is greedily modeled as an RBM trained in an unsupervised manner. Afterwards, each hidden layer is further trained using the discriminative information of labels in a supervised strategy. DBN has been used to solve problems in many fields, such as dimensionality reduction, representation learning, and semantic hashing. A representative DBM is shown in Figure 1.
Figure 1:
2.2 Stacked Autoencoder (SAE)
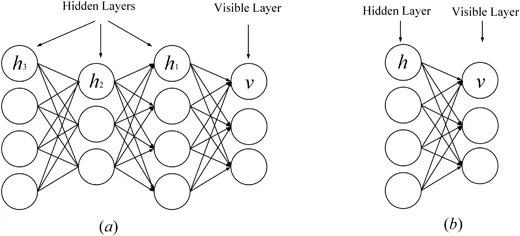
Stacked Autoencoders (SAE) are typical deep learning models based on the encoder-decoder architecture (Michael, Olivier, and Mario, 2018; Weng, Lu, Tan, and Zhou, 2016). It captures concise features of the input by converting the raw input into intermediate representations in an unsupervised-supervised manner. SAE has been widely applied in many fields, including dimensionality reduction (Wang, Yao, & Zhao, 2016), image recognition (Jia, Shao, Li, Zhao, & Fu, 2018), and text classification (Chen & Zaki, 2017). Figure 2 shows a representative SAE.
Figure 2:
2.3 Convolutional Neural Network (CNN)
DBN and SAE are fully connected neural networks. In both networks, every neuron in the hidden layer is connected to every neuron in the previous layer, which creates a large number of connections. To train the weights of these connections, fully connected neural networks require a large number of training objects to avoid overfitting and underfitting, which is computationally intensive. Moreover, fully connected topology does not consider the positional information of the features contained between neurons. Therefore, fully connected deep neural networks (DBN, SAE, and their variants) cannot handle high-dimensional data, especially large images and large audio data.
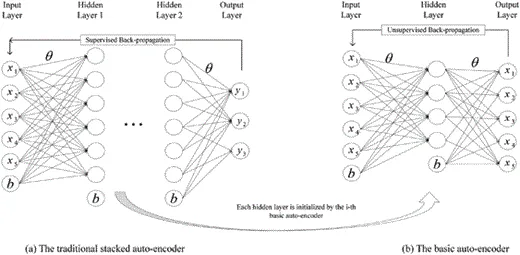
Convolutional Neural Networks are a special type of deep network that takes into account the local topological structure of the data (Li, Xia, Du, Lin, & Samat, 2017; Sze, Chen, Yang, and Emer, 2017). Convolutional Neural Networks include fully connected networks and constraint networks that contain convolutional and pooling layers. Constraint networks use convolution and pooling operations to achieve local receptive fields and parameter reduction. Like DBN and SAE, convolutional neural networks are also trained using stochastic gradient descent algorithms. They have made significant progress in medical image recognition (Maggiori, Tarabalka, Charpiat, and Alliez, 2017) and semantic analysis (Hu, Lu, Li, & Chen, 2014). A representative CNN is shown in Figure 3.
Figure 3:
2.4 Recurrent Neural Network (RNN)
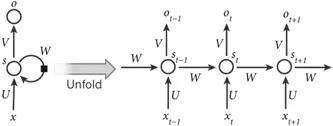
Recurrent Neural Networks are a neural computing architecture for processing sequential data (Martens & Sutskever, 2011; Sutskever, Martens, and Hinton, 2011). Unlike deep feedforward architectures (i.e., DBN, SAE, and CNN), it not only maps input patterns to output results but also transmits hidden states to outputs by utilizing connections between hidden units (Graves & Schmidhuber, 2008). By using these hidden connections, RNN models temporal dependencies, thus sharing parameters between objects over time. It has been applied in various fields such as speech analysis (Mulder, Bethard, and Moens, 2015), image captioning (Xu et al., 2015), and language translation (Graves & Jaitly, 2014), achieving excellent performance. Similar to deep feedforward architectures, its computation also includes forward pass and backpropagation stages. In the forward pass computation, RNN simultaneously acquires input and hidden states. In the backpropagation computation, it uses the time backpropagation algorithm to backpropagate the loss over time steps. Figure 4 shows a representative RNN.
Figure 4:
3 Deep Learning for Multimodal Data Fusion
In this section, we review the most representative multimodal data fusion deep learning models from the perspectives of model tasks, model frameworks, and evaluation datasets. Based on the deep learning architectures used, they are divided into four categories. Table 2 summarizes the representative multimodal deep learning models.
Table 2:
Summary of Representative Multimodal Deep Learning Models.
3.1 Network-based Deep Belief Multimodal Data Fusion
3.1.1 Example 1
Srivastava and Salakhutdinov (2012) proposed a multimodal generative model based on deep Boltzmann learning models that learns multimodal representations by fitting the joint distribution of multimodal data across various modalities (such as images, text, and audio).

The proposed multimodal DBN initializes each module in an unsupervised layer-wise manner and uses MCMC-based approximate methods for model training.
To evaluate the learned multimodal representations, a range of tasks were performed, such as generating missing modality tasks, inferring joint representation tasks, and discriminative tasks. Experiments validated whether the learned multimodal representations met the desired properties.
3.1.2 Example 2
To effectively diagnose Alzheimer’s disease early, Suk, Lee, Shen, and the Alzheimer’s Neuroimaging Initiative (2014) proposed a multimodal Boltzmann model that can fuse complementary knowledge from multimodal data. Specifically, to address the limitations caused by shallow feature learning methods, DBN was used to learn deep representations for each modality by transferring domain-specific representations to hierarchical abstract representations. A single-layer RBM was then built on the concatenated vector, which is a linear combination of the hierarchical abstract representations from each modality. It was used to learn multimodal representations by constructing the joint distribution of different multimodal features. Finally, extensive evaluations of the proposed model were conducted based on three typical diagnoses on the ADNI dataset, achieving state-of-the-art diagnostic accuracy.
3.1.3 Example 3
To accurately estimate human posture, Ouyang, Chu, and Wang (2014) designed a multi-source deep learning model that learns multimodal representations by extracting the joint distribution of body patterns in high-order space from mixed types, appearance scores, and deformation modalities. In the human-pose multi-source deep model, three widely used modalities were extracted from the image structure model, which combined the various parts of the body based on conditional random field theory. To obtain multimodal data, the graphical structure model was trained using a linear support vector machine. After that, each of these three features was input into a two-layer restricted Boltzmann model to capture the abstract representation of high-order pose space from feature-specific representations. Through unsupervised initialization, each restricted Boltzmann model for specific modalities captures the inherent representation of the global space. Then, the RBM was further used to learn human pose representations based on high-level mixed types, appearance scores, and deformation representations. To train the proposed multi-source deep learning model, a task-specific objective function that considers both body position and human detection was designed. The proposed model was validated on LSP, PARSE, and UIUC, achieving improvements of up to 8.6%.
Recently, several new multimodal feature learning models based on DBN have been proposed. For example, Amer, Shields, Siddiquie, and Tamrakar (2018) proposed a hybrid method for sequence event detection, using conditional RBM to extract modal and cross-modal features with additional discriminative label information. Al-Waisy, Qahwaji, Ipson, and Al-Fahdawi (2018) introduced a multimodal method for facial recognition. In this method, a DBN-based model was used to model the multimodal distribution of local handcrafted features captured by Curvelet transforms, which can combine the advantages of local features and deep features (Al-Waisy et al., 2018).
3.1.4 Summary
These DBN-based multimodal models use probabilistic graphical networks to transform modality-specific representations into semantic features in a shared space. Then, the joint distribution on modalities is modeled based on the features of the shared space. These DBN-based multimodal models are more flexible and robust in unsupervised, semi-supervised, and supervised learning strategies. They are well-suited to capture the information features of input data. However, they neglect the spatial and temporal topological structures of multimodal data.
3.2 Stacked Autoencoder-based Multimodal Data Fusion
3.2.1 Example 4
Multimodal deep learning proposed by Ngiam et al. (2011) is the most representative deep learning model for multimodal data fusion based on Stacked Autoencoders (SAE). This deep learning model aims to solve two data fusion problems: cross-modal and shared modal representation learning. The former aims to leverage knowledge from other modalities to capture better unimodal representations, while the latter focuses on the complex correlations between intermediate learning modalities. To achieve these goals, three learning scenarios were designed — multimodal, cross-modal, and shared modal learning, as shown in Table 3 and Figure 6.
Figure 6:
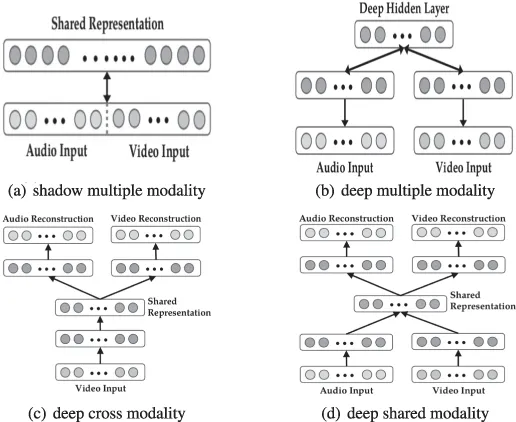
Architecture of multimodal, cross-modal, and shared modal learning.
Table 3: Settings for Multimodal Learning.
In the multimodal learning scenario, audio spectrograms and video frames are linearly concatenated into vectors. The concatenated vector is fed into a sparse restricted Boltzmann machine (SRBM) to learn the correlations between audio and video. This model can only learn the shadow joint representation of multiple modalities because the correlations are implicit in the high-dimensional representations at the raw level, and a single-layer SRBM cannot model them. Inspired by this, the concatenated vector of intermediate representations is input into the SRBM to model the correlations of multiple modalities, showing better performance.
In the cross-modal learning scenario, a deep stacked multimodal autoencoder was proposed to explicitly learn the correlations between modalities. Specifically, audio and video are presented as inputs in feature learning, and during supervised training and testing, only one of them is input into the model. This model is initialized in a multimodal learning manner and can effectively simulate cross-modal relationships.
In shared modal representation, specific to the modal deep stacked multimodal autoencoder introduced under the incentive of denoising autoencoders, it explores the joint representations between modalities, especially in the absence of one modality. The training dataset, expanded by replacing one modality with zero, is input into the feature learning model.
Finally, detailed experiments were conducted on the CUAVE and AVLetters datasets to evaluate the performance of multimodal deep learning in specific task feature learning.
3.2.2 Example 5
To generate visually and semantically effective human skeletons from a series of images (especially videos), Hong, Yu, Wan, Tao, and Wang (2015) proposed a multimodal deep autoencoder to capture the fusion relationship between images and poses. In particular, the proposed multimodal deep autoencoder is trained using a three-stage strategy to build a nonlinear mapping between 2D images and 3D poses. In the feature fusion stage, multi-view hypergraph low-rank representation is utilized to construct internal 2D representations from a series of image features (such as oriented gradient histograms and shape contexts) based on manifold learning. In the second stage, a single-layer autoencoder is trained to learn abstract representations that are used to recover 3D poses by reconstructing features of 2D images. Simultaneously, a single-layer autoencoder is trained similarly to learn the abstract representation of 3D poses. After obtaining the abstract representations of each single modality, a neural network is used to learn the multimodal correlation between 2D images and 3D poses by minimizing the squared Euclidean distance between the mutual representations of the two modalities. The learning of the proposed multimodal deep autoencoder consists of initialization and fine-tuning stages. In the initialization phase, parameters of each sub-part of the multimodal deep autoencoder are copied from the corresponding autoencoders and neural networks. Then, the parameters of the entire model are further fine-tuned using the stochastic gradient descent algorithm to construct 3D poses from the corresponding 2D images.
3.2.3 Summary
SAE-based multimodal models adopt encoder-decoder architectures to extract intrinsic modal features and cross-modal features through reconstruction methods in an unsupervised manner. Since they are based on SAE, which is a fully connected model, they require training many parameters. Furthermore, they neglect the spatial and temporal topological structures within multimodal data.
3.3 Convolutional Neural Network-based Multimodal Data Fusion
3.3.1 Example 6
To simulate the semantic mapping distribution between images and sentences, Ma, Lu, Shang, and Li (2015) proposed a multimodal convolutional neural network. To fully capture the semantic relevance, a three-level fusion strategy was designed in the end-to-end architecture — word-level, phase-level, and sentence-level. The architecture consists of an image subnet, a matching subnet, and a multimodal subnet. The image subnet is a representative deep convolutional neural network, such as Alexnet and Inception, which effectively encodes image inputs into concise representations. The matching subnet models the joint representation that associates the content of images with fragments of sentences in the semantic space.
3.3.2 Example 7
To extend visual recognition systems to an infinite number of discrete categories, Frome et al. (2013) proposed a multimodal convolutional neural network by leveraging semantic information in textual data. The network consists of a language submodel and a visual submodel. The language submodel is based on the skip-gram model, which can transmit textual information into dense representations in the semantic space. The visual submodel is a representative convolutional neural network, such as Alexnet, which is pre-trained on the 1000-class ImageNet dataset to capture visual features. To model the semantic relationship between images and text, the language and visual submodels are combined through a linear projection layer. Each submodel is initialized with the parameters of each modality. After that, to train this visual-semantic multimodal model, a new loss function was proposed, which provides high similarity scores for correct image and label pairs by combining dot product similarity and hinge rank loss. The model can achieve state-of-the-art performance on the ImageNet dataset, avoiding semantically unreasonable results.
3.3.3 Summary
CNN-based multimodal models can learn local multimodal features between modalities through local fields and pooling operations. They explicitly model the spatial topology of multimodal data. Moreover, they are not fully connected models, significantly reducing the number of parameters.
3.4 Recurrent Neural Network-based Multimodal Data Fusion
3.4.1 Example 8
To generate captions for images, Mao et al. (2014) proposed a multimodal recurrent neural architecture. This multimodal recurrent neural network can bridge the probabilistic correlations between images and sentences. It addresses the limitations of previous works that could not generate new image captions, as prior works retrieved corresponding titles from a sentence database based on learned image-text mappings. Unlike previous works, the multimodal recurrent neural model (MRNN) learns the joint distribution in the semantic space based on given words and images. When an image appears, it generates sentences word by word based on the captured joint distribution. Specifically, the multimodal recurrent neural network consists of a language subnet, a visual subnet, and a multimodal subnet, as shown in Figure 7.
Figure 7:
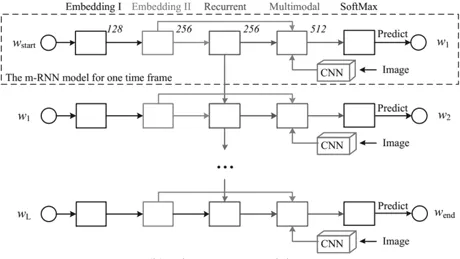
3.4.2 Example 9
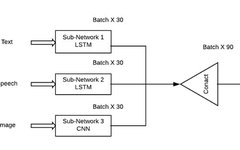
To address the limitation of current visual recognition systems that cannot generate rich descriptions of images at a glance, a multimodal alignment model was proposed by bridging the inter-modal relationships between visual and textual data (Karpathy & Li, 2017). To achieve this, a dual scheme was designed. Firstly, a visual semantic embedding model was designed to generate a multimodal training dataset. Then, a multimodal RNN was trained on this dataset to generate rich descriptions of images.
In the visual semantic embedding model, a region convolutional neural network is used to obtain rich image representations that contain sufficient information corresponding to the content of the sentences. Then, a bidirectional RNN is used to encode each sentence into dense vectors of the same dimension as the image representations. Additionally, a multimodal scoring function is provided to measure the semantic similarity between images and sentences. Finally, a Markov random field method is utilized to generate the multimodal dataset.
In the multimodal RNN, a more efficient extended model based on textual content and image input is proposed. This multimodal model consists of a convolutional neural network that encodes image inputs and an RNN that encodes image features and sentences. This model is also trained using the stochastic gradient descent algorithm. Both multimodal models are extensively evaluated on the Flickr and MSCOCO datasets, achieving state-of-the-art performance.
3.4.3 Summary
RNN-based multimodal models can analyze temporal dependencies hidden in multimodal data through explicit state transmission in hidden unit computations. They use time backpropagation algorithms to train parameters. As computations are performed during hidden state transmission, it is challenging to parallelize on high-performance devices.
4 Summary and Outlook
We summarize the models into four groups of multimodal data deep learning models based on DBN, SAE, CNN, and RNN. These pioneering patterns have made some progress. However, these models are still in their preliminary stages, and challenges remain.
First, there are a large number of free weights in multimodal data fusion deep learning models, particularly redundant parameters that have little impact on the target task. To train these parameters that capture the structure of data features, a large amount of data is input into multimodal data fusion deep learning models based on backpropagation algorithms, which are computation-intensive and time-consuming. Therefore, how to design new multimodal deep learning compression methods combining existing compression strategies is also a potential research direction.
Secondly, multimodal data contains not only cross-modal information but also rich cross-modal information. Therefore, the combination of deep learning and semantic fusion strategies may be one way to address the challenges posed by exploring multimodal data.
Third, collecting multimodal data from dynamic environments indicates that the data is uncertain. Therefore, with the explosive growth of dynamic multimodal data, the design issues of online and incremental multimodal deep learning models for data fusion must be addressed.