
Introduction: AI, CNN Algorithm, Hilbert, Feynman, 577

Who are the eldest, second, and third brothers of the convolution family?
Starting from the division of apples into sizes…


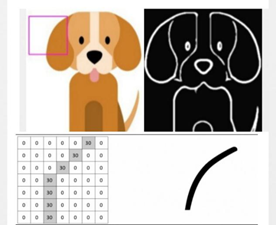
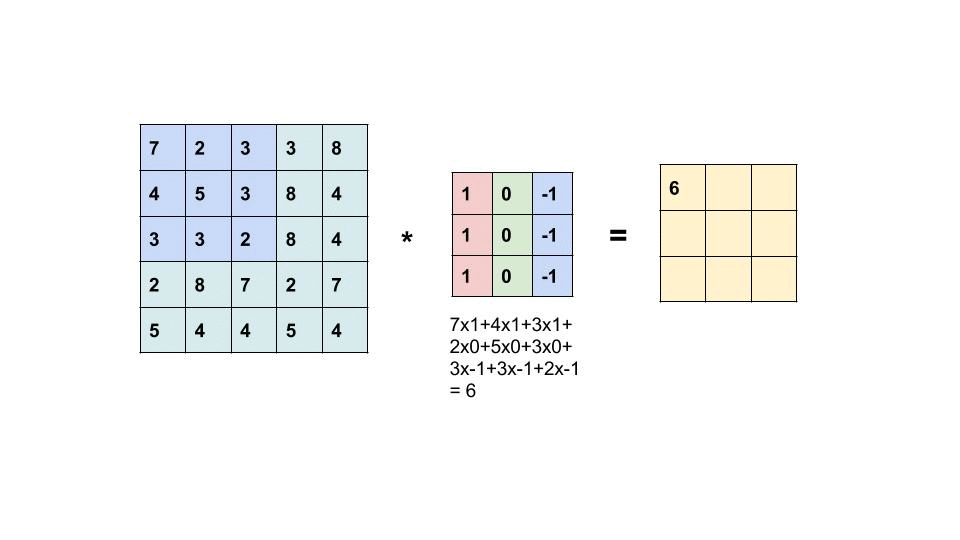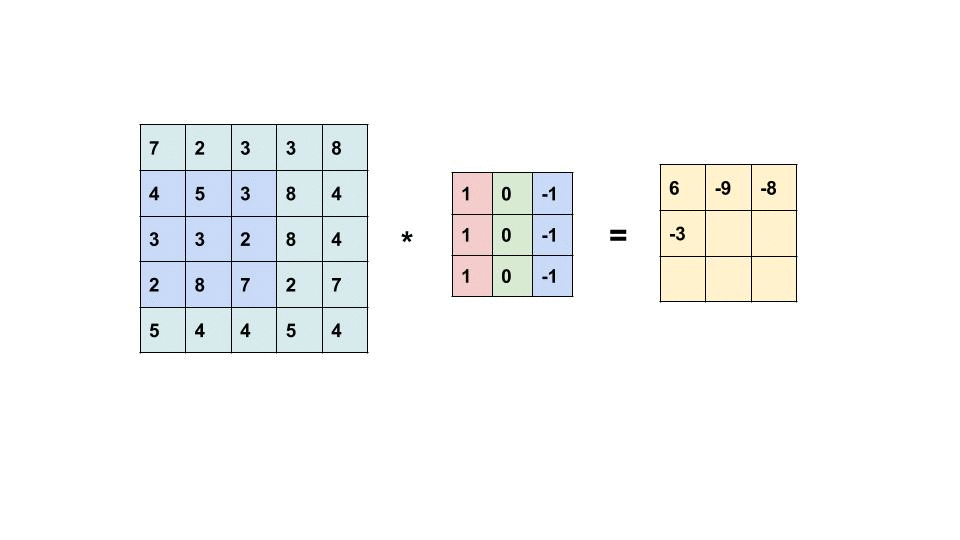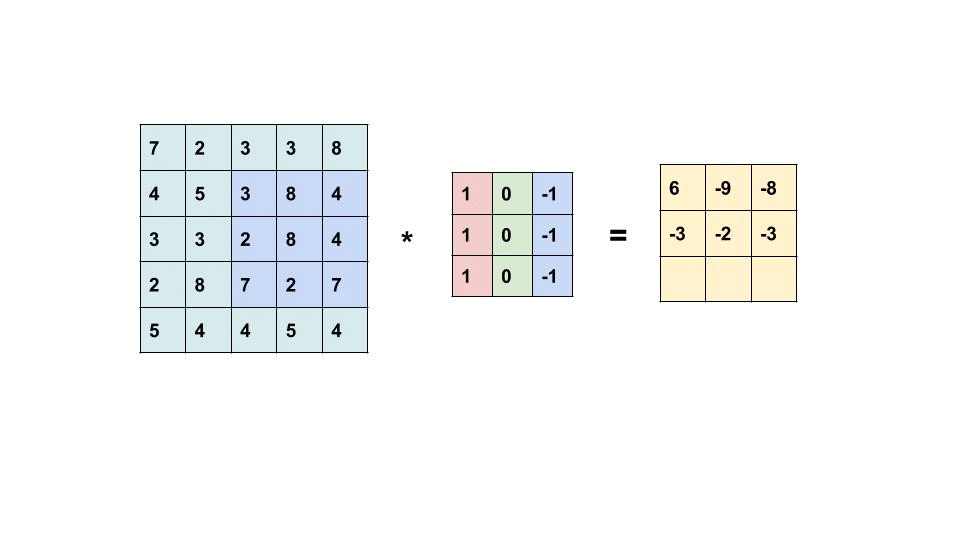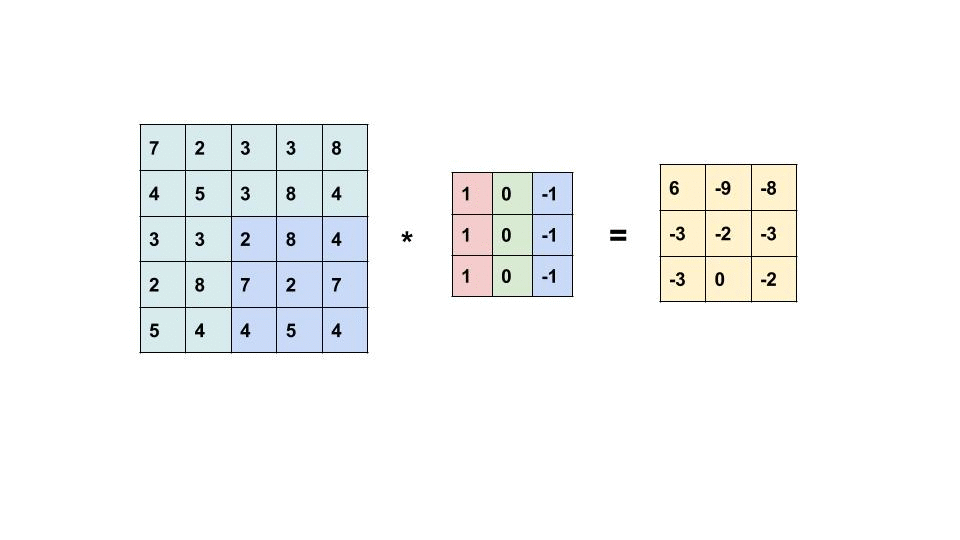


Next, let’s look at the Fourth Brother of the Convolution Family, the ‘Convolution Layer’
Understanding the four brothers means you’ve succeeded halfway
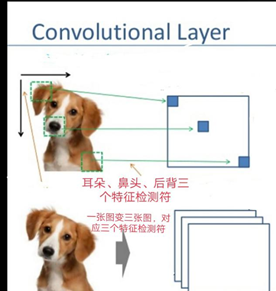
‘Neural’ means what? A misleading term.


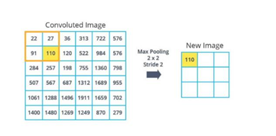
Besides ‘Convolution Layer’, what are the other two layers?
What does ‘Network’ mean in CNN?
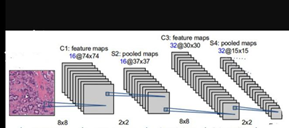
CNN’s Second Half: What is Learned in Deep Learning?
What is the fundamental flaw of CNN?

Conclusion
In Closing

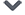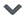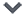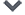


This article is a featured content of NetEase News · NetEase Account “Each Has Its Attitude” Some content is sourced from the internet Please reply “Reprint” in the public account for reprints



