Skip to content
AI has swept the technology market. However, developing enterprise-level AI applications that can drive various vertical industries requires a new type of IT infrastructure. This infrastructure needs to be faster, more scalable, and more reliable than traditional centralized client-server networks.
NVIDIA’s Jensen Huang once stated: “Accelerated computing has reached a turning point, and ‘general computing’ is becoming inadequate. We need another way of computing…”
The shift Huang referred to signifies a change across the entire technology stack, including a revolution in network technology. Whether it is the internal chip connections of supercomputers, the interconnections of servers within AI clusters, or connecting these clusters with the network edge, all technologies must evolve to meet the performance demands of AI applications.
Market Trends in AI Networks
At the base layer of AI networks, there are I/O connections that link CPUs and GPUs to memory and to each other within AI servers. These connections rely on I/O standards such as PCIe and CXL.
For instance, as a leader in the AI network market, NVIDIA supports NVLink. According to NVIDIA, NVLink supports inter-GPU rates of up to 900 Gb/s, which is more than seven times the bandwidth of PCIe. To connect multiple GPUs using NVLink in AI servers, NVIDIA provides the NVLink Switch, a rack-level chip. Through the NVLink Switch, NVLink connections can scale across nodes, creating a seamless, high-bandwidth, multi-node GPU cluster.
Other vendors are also building similar proprietary solutions. For example, AMD offers the Infinity Fabric architecture to establish connections between its MI200 accelerators and EPYC processors in AI clusters. Recently, Astera Labs has introduced a PCIe/CXL Smart DSP Retimer that enhances overall performance by shortening the distance between CPUs, DPUs, storage, and other AI server components by retransmitting physical layer signals. Broadcom also offers its own PCIe Retimer, recently claiming to have released “the world’s first 5nm PCIe Gen 5.0/CXL2.0 and PCIe Gen 6.0/CXL3.1 Retimer.”
DPUs offload network and security processing tasks from the server’s CPU, and some also provide switching functions. The use of DPUs is not limited to NVIDIA; Broadcom and Intel are also market leaders, with vendors like Acronix and Napatech producing DPUs that support both InfiniBand and Ethernet.
Reportedly, Microsoft is developing a DPU for AI networks based on the technology acquired from the startup Fungible in early 2023. Fungible developed a DPU that aggregates solid-state drive storage within hyperscale data centers, reportedly outperforming NVIDIA’s DPU by 50%.
AI networks have zero tolerance for any form of congestion, latency, delay, or packet loss. Consequently, a range of solutions aimed at optimizing AI traffic and making it “lossless” have emerged in the market.
These include the virtual output queue (VOQ) adopted by Arista, which eliminates certain latencies in Ethernet packet flows and ensures full throughput on specific connections when used in conjunction with scheduling. Ethernet chip leader Broadcom has integrated packet scheduling into its Jericho3-AI chip, designed to provide load balancing, congestion control, and zero-impact failover for Ethernet-based AI networks.
Rapid Development of Switches
Switches are critical to AI networks, using both InfiniBand and Ethernet technologies, with various configurations. Vendors are actively adopting new technologies, and it is expected that this market will exhibit dynamic and rapid development in the coming years.
For example, NVIDIA’s Quantum-2 switch provides 64 400 Gb/s InfiniBand ports in a 1U chassis. These switches can work in conjunction with NVIDIA’s ConnectX network adapters and BlueField-3 DPUs. NVIDIA states that its InfiniBand solutions “integrate self-healing network capabilities, quality of service, enhanced virtual channel mapping, and advanced congestion control to maximize overall application throughput.” This solution is designed for multi-tenant networks in hyperscale or large enterprise environments.
Starting in 2025, NVIDIA will launch the Quantum-X800 platform, which includes the Quantum Q3400 InfiniBand switch, supporting 144 800 Gb/s ports, as well as the ConnectX-8 SuperNIC and specially designed LinkX cables and transceivers.
To support Ethernet, NVIDIA offers the Spectrum-X platform, which includes an Ethernet switch supporting 64 800 Gb/s ports and a BlueField-3 SuperNIC that supports 400 Gb/s RoCE connections. In 2025, NVIDIA will release its Spectrum-X800 platform, which includes a new 800 Gb/s switch and the BlueField-3 SuperNIC.
AI network interconnection: choose InfiniBand or Ethernet— this has been a topic of discussion in the industry.
Currently, thanks to NVIDIA’s absolute market leadership and the advantages of InfiniBand over Ethernet in overall performance, InfiniBand technology has occupied about 80% to 90% of the market share in most AI network environments since NVIDIA’s acquisition of Mellanox in 2020.
InfiniBand offers higher throughput by supporting parallel data flows coordinated by NVIDIA software. Its quality of service control is fine-grained, and its message-based interaction protocol helps eliminate packet loss. InfiniBand is also a deterministic technology that directly supports RDMA. At the 2024 GTC conference, NVIDIA promoted its Quantum Q3400 InfiniBand switch, which can provide end-to-end speeds of 800 Gb/s. However, this switch will not start shipping until 2025.
However, the high cost of InfiniBand has become a significant disadvantage in competing with Ethernet, coupled with its high dependence on NVIDIA hardware and software, which somewhat limits customers’ freedom of choice, forcing them to bind to NVIDIA’s product ecosystem. Moreover, InfiniBand is far less widespread in terms of availability and support compared to Ethernet.
Meanwhile, Ethernet still needs to make significant efforts to keep pace with InfiniBand in terms of performance advantages.
Improvements Needed for Ethernet
In July 2023, AMD, Arista, Broadcom, Cisco, Eviden, HPE, Intel, Meta, and Microsoft announced the formation of the Ultra Ethernet Consortium (UEC). The goal of this organization is to develop an “Ethernet-based, open, interoperable, high-performance, full communication stack architecture to meet the growing network demands of large-scale AI and HPC.” Relevant specifications are expected to be released in 2025.
Will NVIDIA join the UEC?Insiders say that if the UEC makes significant research progress, NVIDIA will support the organization, but whether it will join remains uncertain.
Founding members of the Ultra Ethernet Consortium
The UEC aims to make the following adjustments to Ethernet:
Lossless Data Streams.Packet loss is an inherent flaw of Ethernet, and in AI networks, vendors have implemented a range of technologies to address this issue. For example, Broadcom has integrated intelligent scheduling capabilities in its Jericho3-AI chip for leaf switches, ensuring reliable packet transmission. Companies like Arista, Cisco, and Juniper also offer scheduling features in their switches to enhance network performance.
Reform of RoCEv2.Switch vendors such as Arista, Broadcom, Juniper, and Cisco all support RoCEv2, seeing it as a key factor in achieving maximum throughput. However, they believe RoCEv2 needs a complete overhaul. Specifically, research needs to be conducted on RDMA itself. Arista CEO Jayshree Ullal wrote in a blog post last year: “The traditional RDMA defined by the InfiniBand Trade Association (IBTA) decades ago seems somewhat outdated for the demanding AI/ML network traffic. RDMA transmits information in large flows, which can lead to link imbalance and overload. It is time to start from scratch and build a modern transport protocol that supports RDMA for emerging applications.”
Packet Spraying.Ethernet inherently causes packet collisions during data transmission. Vendors have their own load balancing solutions, but these are often proprietary. There are now various attempts to ensure that packets are evenly distributed across multiple paths. One such attempt is called Packet Spraying, which, in Ullal’s words, “allows each flow to access all paths to the destination simultaneously.”
More Congestion Management.Even relatively small traffic errors can disrupt entire AI workloads, forcing them to rerun. The UEC is researching algorithms for controlling load balancing in multipath transmission to ensure optimal utilization of expensive GPUs.
Ethernet Vendors Plan to Challenge NVIDIA
So far, NVIDIA has dominated the AI switch market, but the evolution of Ethernet presents potential opportunities for other vendors to offer viable alternatives. With the widespread adoption of technologies like RoCEv2, PFC, ECN, and Packet Spraying, Ethernet may be able to match InfiniBand’s performance.
While NVIDIA is able to support both InfiniBand and Ethernet with its Quantum-X and Spectrum-X product lines, other network vendors are entering the AI network market with Ethernet-based solutions. Ullal predicts that the opportunity in the AI network market will reach $750 million in Arista’s next fiscal year.
Arista Networks’ 7800R3 series switches provide AI backbone and core capabilities, supporting up to 576 400 Gb/s connection ports, along with a range of features including VOQ. Arista’s 7060X switches also support data rates of 400 Gb/s and 800 Gb/s. The vendor’s high-performance data center switches, including the 7800R3, 7280R3, 7060X, and 7050X3, all support the RoCEv2 protocol.
Cisco seems to see hope for the future in the Ethernet version, which incorporates Cisco Silicon One ASIC to compete with InfiniBand in HPC environments and AI networks. Additionally, Cisco’s Nexus 9000 switches feature a range of capabilities to enhance the reliability of Ethernet packet flows, including PFC, ECN, and intelligent buffering. The switches use RoCEv2 for AI networks. Cisco claims it supports multiple 400 Gb/s ports and is ready to provide 800 Gb/s connections. It also supports Fibre Channel and IP storage.
Juniper offers QFX switches (based on Broadcom’s Tomahawk 5 chip), PTX routers, and line cards, all of which now support lossless connections at 400 Gb/s and 800 Gb/s, working in conjunction with Apstra AIOps intent-based software, which is also associated with Juniper’s AI Native Networking Platform and Marvis Virtual Network Assistant. Several models in the PTX and QFX series support RoCEv2 networks. Juniper aims for its switches and routers to be “vendor-neutral” and compatible with various third-party SmartNIC/DPUs.
The startup Enfabrica offers a computing-to-computing interconnect switch for AI servers, acting as a high-bandwidth “crossbar of NIC,” enhancing connections between computing, networking, and memory within clusters. The chip, named ACF-S, enhances the functionality of SmartNICs and PCIe switches. Although it has not yet begun shipping, the ACF-S prototype has been showcased at several conferences and trade shows for months, and the company is accepting orders for shipments this year.
The architecture of AI networks varies with the increasing use cases for AI. For instance, NVIDIA’s large multi-GPU systems are connected by NVLink and InfiniBand and equipped with multiple DPUs, typically used for training large language models for generative AI applications. Large companies, including Meta, Microsoft, and Google, are among the few buyers who can afford the costs of these highly scalable and complex systems that can run thousands of GPUs across multiple clusters.
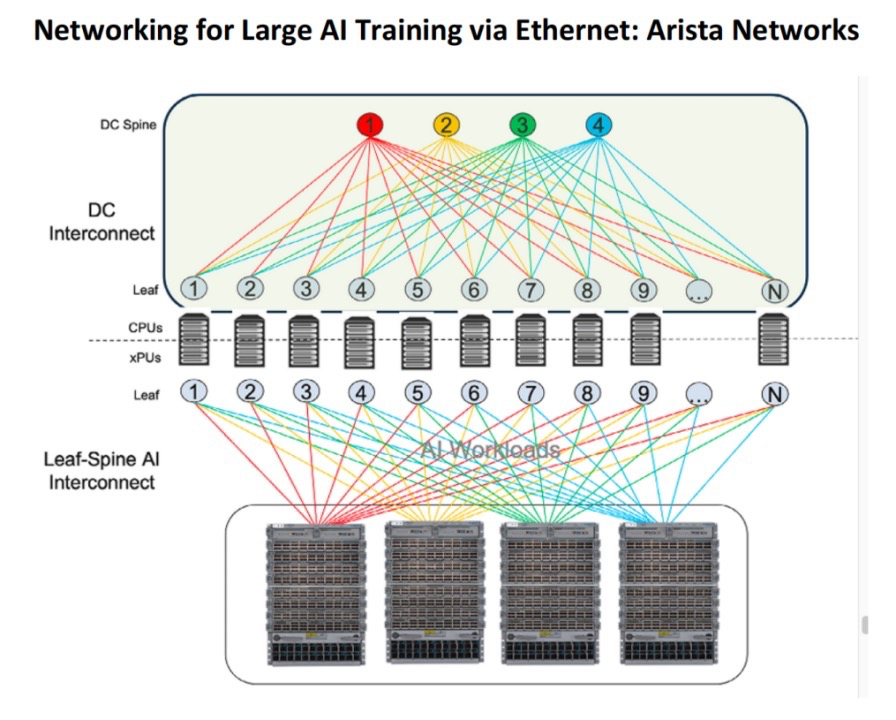
For example, Arista’s Ethernet leaf and spine switches include intelligent load balancing features, making Ethernet a more viable (and cheaper) alternative than InfiniBand. The following diagram illustrates an Ethernet-based training setup, with the front-end network at the top and the back-end network equipped with GPUs and storage at the bottom. The colored circles represent spine switches, such as the Arista 7800, while the gray circles indicate leaf switches, which could be Arista 7050 or 7280 platforms. “xPU” refers to components from different vendors.
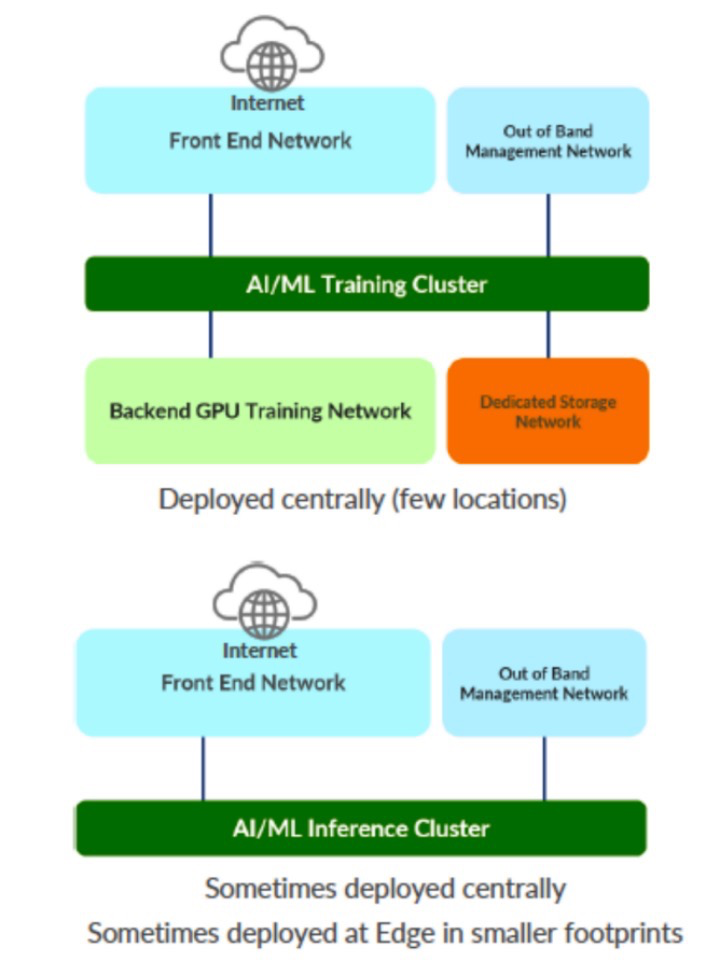
For AI inference, there are numerous options. Generally, inference scenarios still require GPUs, but in smaller quantities, perhaps just dozens or hundreds of GPUs.
Juniper summarizes the different needs of inference architecture in the following diagram:
When it comes to the practical application of InfiniBand and Ethernet in AI networks, both currently hold a place. Google network engineer Amrinder R. wrote in a blog: “It is hard to determine which one is better.” Currently, most hyperscale data center operators are using InfiniBand, with no signs of abandoning it. Companies like Meta run both InfiniBand and Ethernet simultaneously.
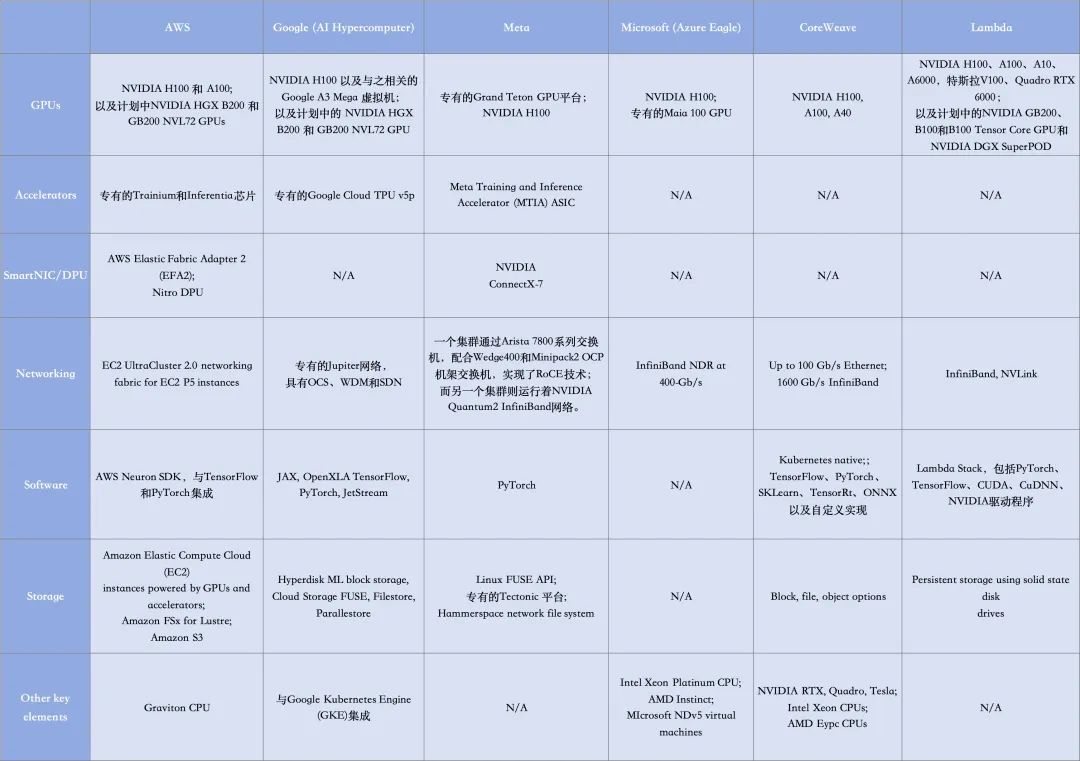
Meta’s implementation of InfiniBand and Ethernet is illustrated in the following diagram:
Meta has built an RDMA cluster based on a RoCE network fabric solution using Arista 7800, Wedge400, and Minipack2 OCP rack switches. Another cluster employs NVIDIA’s Quantum2 InfiniBand architecture. Both solutions can interconnect 400 Gbps endpoints. (For more information, click on “Unveiling the Latest Large-Scale AI Cluster Technology Details from Meta!”)
Other AI Network Deployment Options
In addition to InfiniBand and UEC Ethernet, other options are also emerging.
DriveNets offers a Network Cloud-AI solution,which uses a distributed decentralized chassis (DDC) approach to interconnect any brand of GPU in AI clusters through a cell-based architecture. This product is based on Broadcom Jericho 2C+ and Jericho 3-AI components in a white box implementation, capable of connecting up to 32,000 GPUs at speeds of up to 800 Gb/s.
Optical networks are also showing broad future prospects.
Google has created its own optical network technology Jupiter for its AI supercomputers. Market leader in optical equipment Ciena states that its expertise in coherent optics gives Ciena the opportunity to launch products that accelerate data center interconnect speeds, which may also be applicable to AI data centers. Ciena’s competitor Infineon offers a chip called ICE-D for connections within data centers. This chip integrates a range of optical functions, connecting systems at data rates of 1.6 Tb/s and above over distances from 100 meters to 10 kilometers, and can be used with electrical or optical switching devices.
“This is the beginning of a new industrial revolution, one that is not about energy production or food production, but about the production of intelligence.”
This focus on AI demands a transition from general computing to accelerated computing, as Huang mentioned. The networking of accelerated computing environments must achieve lower latency, higher throughput, greater bandwidth, and overall performance required by AI networks. AI workloads cannot tolerate any latency, congestion, or failure; any failure in any link will force the entire task to rerun. Given the enormous costs of GPUs and their associated AI components, the consequences of failure are costly.
Today, NVIDIA’s dominance in the GPU market also makes it the best-selling vendor in the AI network space. NVLink and InfiniBand, used for GPU connections within and between clusters, have long dominated supercomputing environments, and this dominance continues. Other vendors and the enterprises they serve view Ethernet as another option for AI network interconnection. They believe Ethernet is cheaper than InfiniBand, has a wider range of available expertise, and is not limited by a single vendor’s sales. All of this has contributed to the formation of the UEC.
Meanwhile, components like those from Enfabrica are emerging as part of alternative networking technologies that replace some switches and enhance the performance of GPU clusters.
As the market develops, alternatives that challenge InfiniBand will undoubtedly emerge, but it will not be completely eliminated. InfiniBand’s long-standing dominance in the supercomputing market, along with its rich history of high performance, will ensure that it remains competitive with any alternatives in the coming years.
Source: 5G Communication
Reviewed by: Zhao Lixin