
Selected from muratbuffalo
Author: Murat Demirbas
Translated by Machine Heart
Contributors: Panda
Distributed machine learning is a major research direction in the field of machine learning. Recently, Professor Murat Demirbas from the State University of New York at Buffalo, along with two of his students, published a paper comparing existing distributed machine learning platforms, introducing and comparing the architectures and performances of platforms such as Spark, PMLS, and TensorFlow. After the paper was released, Professor Murat Demirbas also published an interpretive blog post, which has been compiled and introduced by Machine Heart. The original paper can be accessed at: https://www.cse.buffalo.edu/~demirbas/publications/DistMLplat.pdf
This paper investigates the design approaches used by distributed machine learning platforms and proposes future research directions. I collaborated with my students Kuo Zhang and Salem Alqahtani on this work. We completed this paper in the fall of 2016, and it will also appear at the ICCCN’17 conference in Vancouver.
Machine learning (especially deep learning) has recently achieved transformative success in areas such as speech recognition, image recognition, natural language processing, and recommendation/search engines. These technologies have promising applications in autonomous vehicles, digital healthcare systems, CRM, advertising, and the Internet of Things. Of course, capital is leading the accelerated development of machine learning, and we have seen many machine learning platforms emerge recently.
Because the training process involves models of large datasets, machine learning platforms are often distributed, typically using dozens or hundreds of parallel workers to train models. It is estimated that in the near future, the vast majority of tasks running in data centers will be machine learning tasks.
I have a research background in distributed systems, so we decided to study these machine learning platforms from the perspective of distributed systems and analyze their communication and control limitations. We also investigated the fault tolerance and programming difficulty of these platforms.
We categorized these distributed machine learning platforms into three basic design approaches:
1. Basic Dataflow
2. Parameter-Server Model
3. Advanced Dataflow
We provided a brief introduction to these three methods and illustrated them with examples, where the basic dataflow method uses Apache Spark, the parameter-server model uses PMLS (Petuum), and the advanced dataflow model uses TensorFlow and MXNet. We provided several performance comparison results. The paper contains more evaluation results. Unfortunately, as a small team in academia, we could not conduct large-scale evaluations.
At the end of this article, I provide a summary and suggestions for future research on distributed machine learning platforms. If you are already familiar with these distributed machine learning platforms, you can skip directly to the end to see the conclusion.
Spark
In Spark, computations are modeled as a Directed Acyclic Graph (DAG), where each vertex represents a Resilient Distributed Dataset (RDD), and each edge represents an operation on the RDD. RDDs are collections of objects partitioned into different logical partitions, stored and processed in-memory, with shuffling/overflow to disk.
In a DAG, the edge E from vertex A to vertex B indicates that RDD B is the result of performing operation E on RDD A. There are two types of operations: transformations and actions. Transformations (e.g., map, filter, join) refer to executing an operation on an RDD to generate a new RDD.
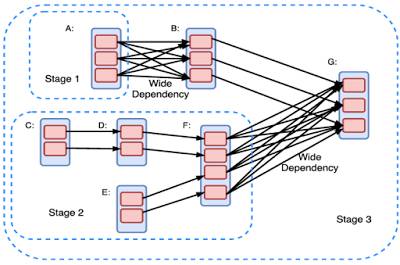
Spark users need to model computations as a DAG, performing transformations or actions on RDDs. The DAG needs to be compiled into stages. Each stage executes as a series of parallel tasks (each partition executes one task). Simple narrow dependencies favor efficient execution, while wide dependencies introduce bottlenecks as they disrupt the flow and require communication-intensive shuffle operations.
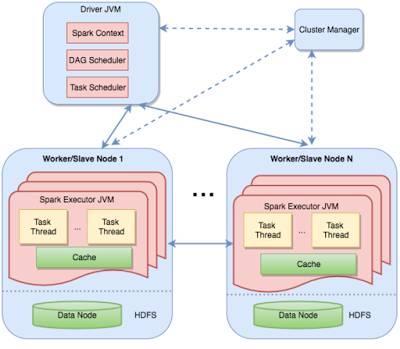
Distributed execution in Spark is achieved by splitting the DAG stages across different machines. This diagram clearly shows the master-worker architecture. The driver contains the tasks and two scheduler components – the DAG scheduler and the task scheduler; it also maps tasks to workers.
Spark is designed for general data processing and is not specific to machine learning. However, using MLlib for Spark, machine learning can also be performed on Spark. In basic setups, Spark stores model parameters on the driver node, and workers communicate with the driver to update these parameters after each iteration. For large-scale deployments, these model parameters may not fit in the driver and are maintained and updated as an RDD. This incurs significant overhead because a new RDD needs to be created to hold updated model parameters after each iteration. Updating models involves reshuffling data across machines/disks, which limits Spark’s scalability. This is a drawback of Spark’s basic dataflow model (DAG). Spark does not support the iteration required for machine learning well.
PMLS
PMLS is specifically designed for machine learning, without any other cluttered history. It introduces the abstract concept of parameter servers (PS) to support the intensive iterative process of machine learning training.
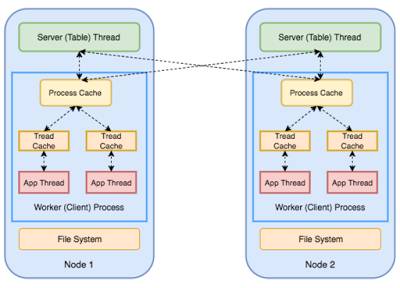
In this context, PS (the green box in the figure) is used as a distributed in-memory key-value store. It is replicated and shared: each node serves as the primary node for one shard of this model (parameter space) and as secondary nodes/replicas for other shards. Therefore, in terms of the number of nodes, PS can scale well.
PS nodes store and update model parameters and respond to requests from workers. Workers request the latest model parameters from their local PS replicas and perform computations on their assigned portions of the dataset.
PMLS also adopts the Stale Synchronous Parallelism (SSP) model, which is more relaxed than the Bulk Synchronous Parallelism (BSP) model – where workers synchronize at the end of each iteration. SSP reduces the hassle of synchronization for workers, ensuring that the fastest worker cannot exceed the slowest worker by s iterations. The relaxed consistency model can still be used for machine learning training because the process has a certain noise tolerance. I discussed this issue in my April 2016 article: https://muratbuffalo.blogspot.com/2016/04/petuum-new-platform-for-distributed.html
TensorFlow
Google has a distributed machine learning platform based on the parameter server model called DistBelief. Refer to my commentary on the DistBelief paper: https://muratbuffalo.blogspot.com/2017/01/google-distbelief-paper-large-scale.html. In my opinion, the main flaw of DistBelief is that writing machine learning applications requires manipulating low-level code. Google wants all its employees to be able to write machine learning code without needing to master distributed execution – for the same reason, Google developed the MapReduce framework for big data processing.
To achieve this goal, Google designed TensorFlow. TensorFlow adopts a dataflow paradigm, but it is a more advanced version – where the computation graph does not need to be a DAG and can include loops and support mutable states. I believe the design of Naiad may have influenced the design of TensorFlow.
TensorFlow uses directed graphs of nodes and edges to represent computations. Nodes represent computations, and states can be mutable. Edges represent multi-dimensional data arrays (tensors) that are transmitted between nodes. TensorFlow requires users to statically declare this symbolic computation graph and uses rewriting and partitioning to allocate it to machines for distributed execution. (MXNet, especially DyNet, uses dynamic declaration of graphs, improving programming difficulty and flexibility.)
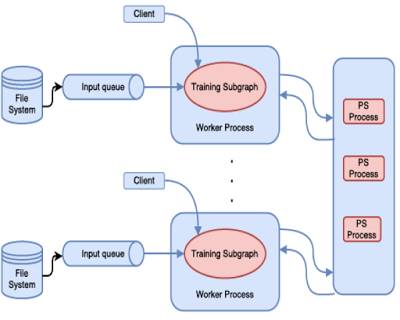
Distributed machine learning training in TensorFlow uses the parameter server method as shown in the figure. When you use the PS abstraction in TensorFlow, you are utilizing parameter servers and data parallelism. TensorFlow also allows you to do more complex things, but that requires writing custom code and venturing into new territories.
Some Evaluation Results
Our evaluations used Amazon EC2 m4.xlarge instances. Each instance contains 4 vCPUs driven by Intel Xeon E5-2676 v3 and 16 GiB of RAM. The EBS bandwidth is 750Mbps. We evaluated two common machine learning tasks: binary classification logistic regression and image classification using multi-layer neural networks. I only present a few graphs here; check our paper for more experiments. However, our experiments have some limitations: we used a small number of machines and could not conduct large-scale tests. We also limited CPU computation and did not test GPU.
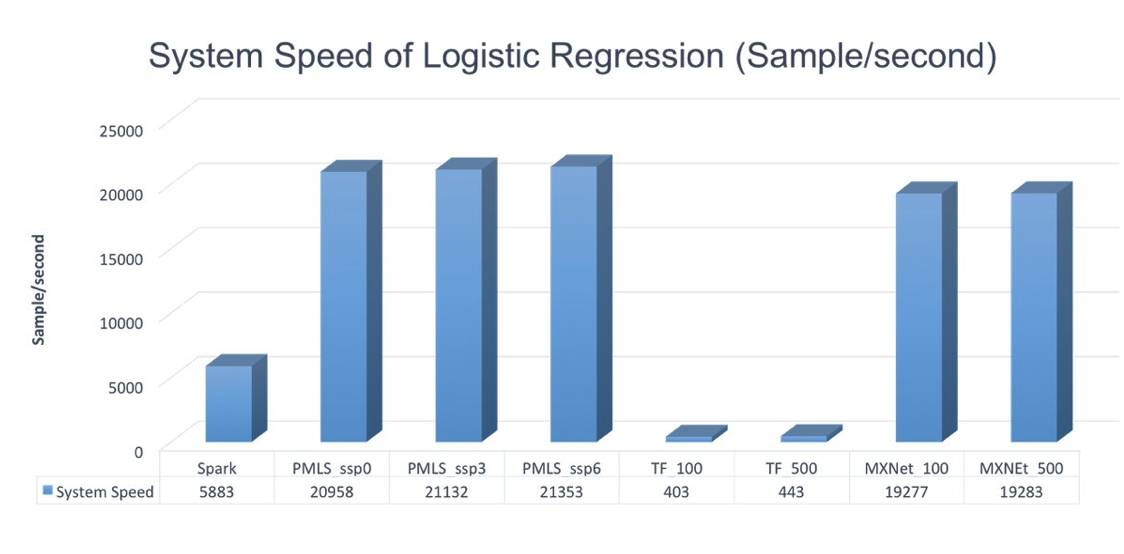
This graph shows the execution speed of logistic regression across platforms. Spark performs well but lags behind PMLS and MXNet.
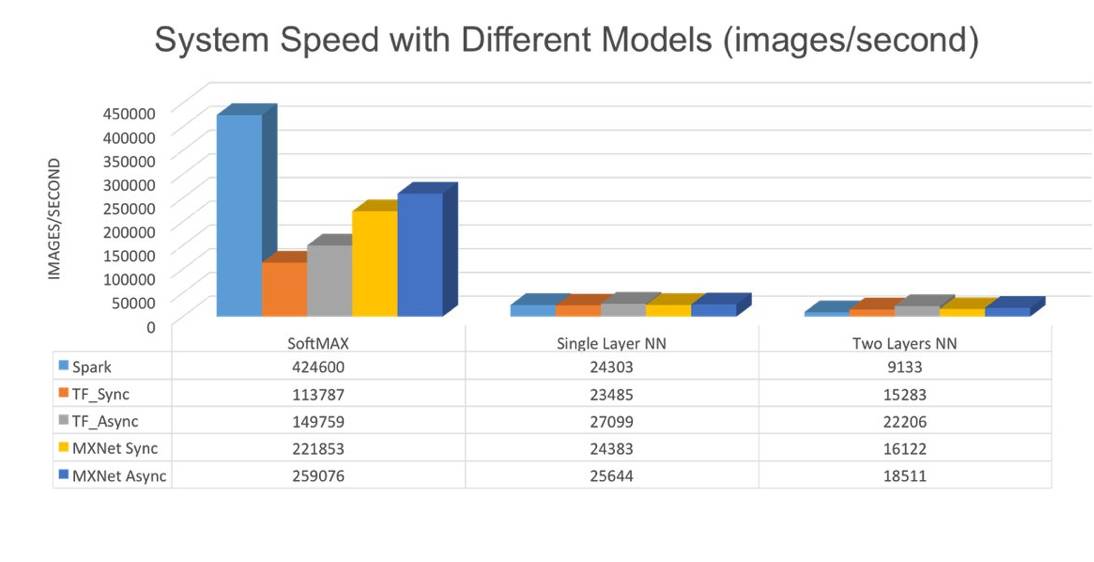
This graph shows the execution speed of deep neural networks (DNN) across platforms. Compared to single-layer logistic regression, Spark shows greater performance loss on two-layer neural networks. This is because two-layer networks require more iterative computations. In Spark, we store parameters in the driver, allowing them to fit; if we store parameters in an RDD and update them after each iteration, the situation would worsen.
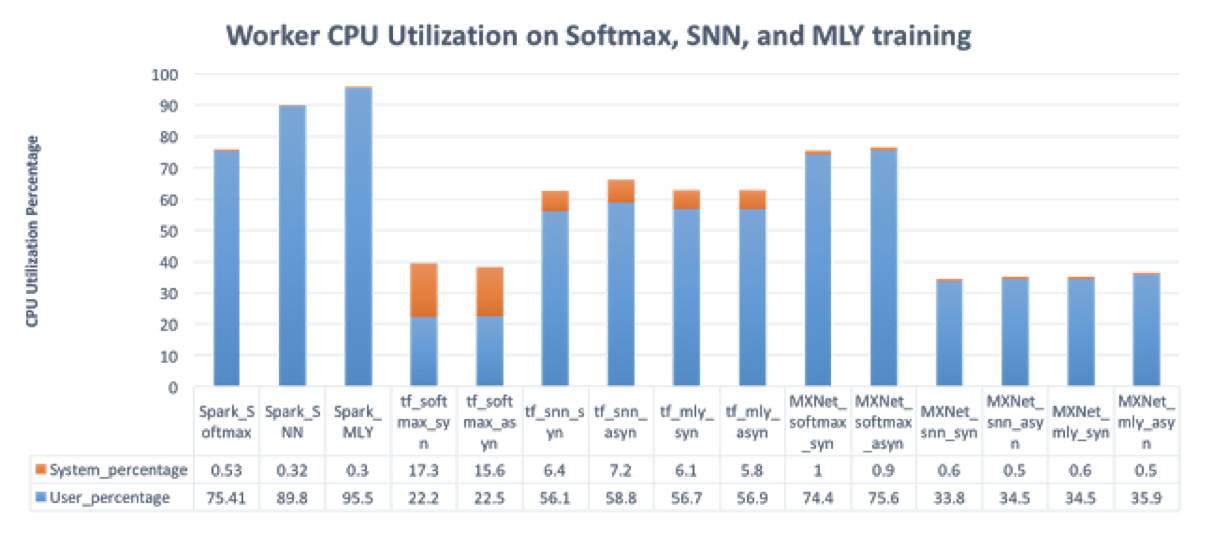
This graph shows the CPU utilization across platforms. Spark applications seem to have significantly high CPU utilization, mainly due to the overhead of serialization. Our earlier work has pointed out this issue: https://muratbuffalo.blogspot.com/2017/05/paper-summary-making-sense-of.html
Summary and Future Directions
Parallel processing of machine learning/deep learning applications is challenging and is not particularly interesting from the perspective of concurrent algorithms. It is quite certain that the parameter server method performs better in training distributed machine learning platforms.
As for limitations, the network remains a bottleneck for distributed machine learning applications. Providing better data/model hierarchy is more useful than more advanced general dataflow platforms; data/model should be treated as first-class citizens.
However, there may be some surprising and subtle aspects. In Spark, CPU overhead becomes a bottleneck before network limitations. The programming language Scala/JVM used by Spark significantly affects its performance. Therefore, distributed machine learning platforms especially need better monitoring and/or performance prediction tools. Recently, some tools have been proposed to address issues in Spark data processing applications, such as Ernest and CherryPick.
There are still many unresolved issues regarding distributed system support for machine learning runtime, such as resource scheduling and runtime performance enhancement. By applying runtime monitoring/performance analysis, the next generation of distributed machine learning platforms should provide detailed runtime elastic configuration/scheduling of computational, memory, and network resources for task execution.
Finally, there are also some unresolved issues regarding programming and software engineering support. What kind of (distributed) programming abstractions are suitable for machine learning applications? Additionally, more research is needed on the verification and validation of distributed machine learning applications, especially testing DNN with problematic inputs.
Original link: http://muratbuffalo.blogspot.jp/2017/07/a-comparison-of-distributed-machine.html
This article is a translation by Machine Heart, please contact this public account for authorization.
✄————————————————
Join Machine Heart (Full-time Reporter/Intern): [email protected]
Submissions or inquiries: [email protected]
Advertising & Business Cooperation: [email protected]