

From some interesting use cases, it seems we can completely combine CNN and RNN/LSTM. Many researchers are currently working on this research. However, the latest research trends in CNN may render this idea outdated.

Some things, like water and oil, seem impossible to combine. While both have their value, they cannot be integrated.
This was my initial reaction to the idea of combining CNN (Convolutional Neural Networks) and RNN (Recurrent Neural Networks). After all, they are optimized for completely different types of problems.
-
CNN is suitable for hierarchical or spatial data, extracting unlabeled features. Suitable data can be images or handwritten characters. CNN accepts fixed-size input and generates fixed-size output.
-
RNN is suitable for temporal data and other types of sequential data. Data can be text bodies, stock market data, or letters and words in speech recognition. The input and output of RNN can be of arbitrary length. LSTM is a variant of RNN that remembers a controllable amount of previous training data or forgets in a more appropriate manner.
For certain types of problems, we know how to select the appropriate tools.
It turns out there is. Most of them target image data that appears in a time series, in other words, video data. But there are also some other interesting applications that have no direct relation to video, which stimulate researchers’ imagination. Below, we will introduce some of these applications.
There are also some recently proposed models that explore how to combine CNN and RNN tools. In many cases, CNN and RNN can be combined using separate layers, taking the output of CNN as input for RNN. However, some researchers have cleverly implemented the capabilities of both within the same deep neural network.
The classic scene labeling method is to train CNN to recognize objects in video frames and classify them. Objects may be further classified into higher-level logical groups. For example, CNN can identify items like stoves, refrigerators, and sinks, which can then be upgraded to classify as a kitchen.
Clearly, what we lack is an understanding of actions between multiple frames (over time). For instance, several frames of a billiard video can correctly indicate that the player has pocketed the eight ball. Another example is if several frames show some young people practicing riding a bicycle, and one rider is lying on the ground, it would be reasonable to conclude, “That boy fell off the bike.”
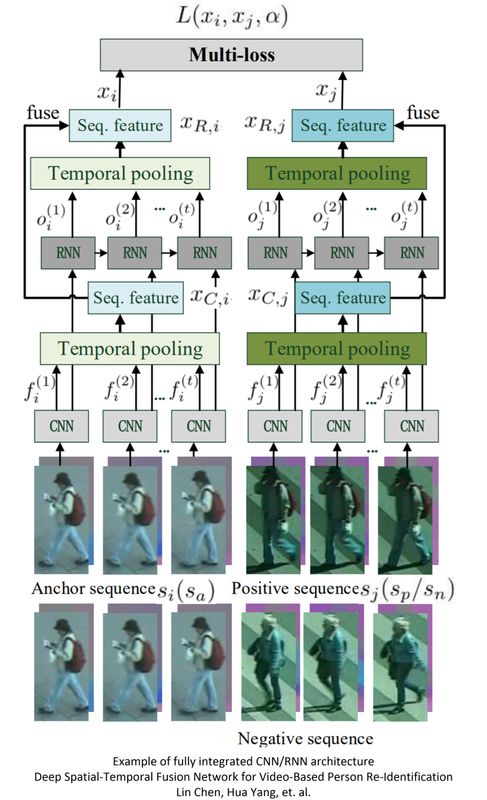
Some researchers have implemented a hierarchical CNN-RNN pair, taking the output of CNN as input for RNN. To create a “momentary” description for each video segment, researchers logically replaced RNN with LSTM. The combined RCNN model is shown above, where recursive connections are directly implemented in the kernel. The researchers eventually conducted some experimental validation on this RCNN model.
For detailed content, please refer to the original paper: http://proceedings.mlr.press/v32/pinheiro14.pdf
How to determine the emotions of individuals or groups through video remains a challenging problem. In response to this issue, the ACM International Conference on Multimodal Interaction (ICMI) holds an annual competition called the “Emotion Grand Challenge” (EGC, EmotiW Grand Challenge).
Each year, the target dataset for the EGC competition changes. The competition typically presents a set of different tests to classify the crowd or individuals appearing in the videos.
2016: Analysis of group happiness.
2017: Detection of three types of emotions (positive, neutral, and negative) based on groups.
The 2018 competition (planned for November) will be even more complex. The challenge involves classifying dining environments, which includes three sub-items:
-
Food Type Challenge: Classifying each utterance into seven categories of food.
-
Food Preference Challenge: Identifying individuals’ scores for food preferences.
-
Dining Conversation Challenge: Identifying the difficulty level of conversations during meals.
The key challenge lies not only in how to combine CNN and RNN, but also how to add audio track data that can be modeled and integrated separately.
The winner of the 2016 competition created a hybrid network composed of RNN and 3D convolutional networks (C3D). As with traditional methods, data fusion and classification occur in the later stages. RNN uses appearance features extracted from various frames by CNN as input and encodes the subsequent motion. At the same time, C3D also models both appearance and motion in the video, which is then merged with the audio module.
Accuracy remains a challenge in the EGC competition, and the current metrics are still not very high. The 2016 winner scored 59.02% in individual facial recognition. In 2017, this rose to 60.34%, with group scores increasing to 80.89%. However, it should be noted that the nature of the challenges changes every year, so comparisons cannot be made on an annual basis.
For detailed information on the EGC annual competition challenges, visit the official ICMI homepage: https://icmi.acm.org/2018/index.php?id=challenges
The goal of this application is to recognize a person in a video (based on an existing personal labeled database) or merely to identify whether someone has appeared in the video (i.e., re-identification, where individuals are unlabeled). Gait recognition is a key research area in this application, further developing into full-body motion recognition (e.g., arm swinging patterns, walking characteristics, posture, etc.).
This application faces some obvious non-technical challenges, the most prominent of which include changes in clothing and shoes, and partial blurriness from jackets or full-body clothing. Some well-known technical issues in CNN include multiple views (essentially multiple perspectives caused by a person passing from left to right, with the first view being front, then side, and finally back), as well as classic image issues like lighting conditions, reflectivity, and size.
Previous studies have represented a complete gait using multiple frames obtained by CNN, which are then combined into a type called “Gait Energy Image” (GEI).
To analyze multiple “gaits” together, some studies have incorporated LSTM into the model. The sequential capabilities of LSTM enable frame-to-frame view transformation models to adjust for perspective.
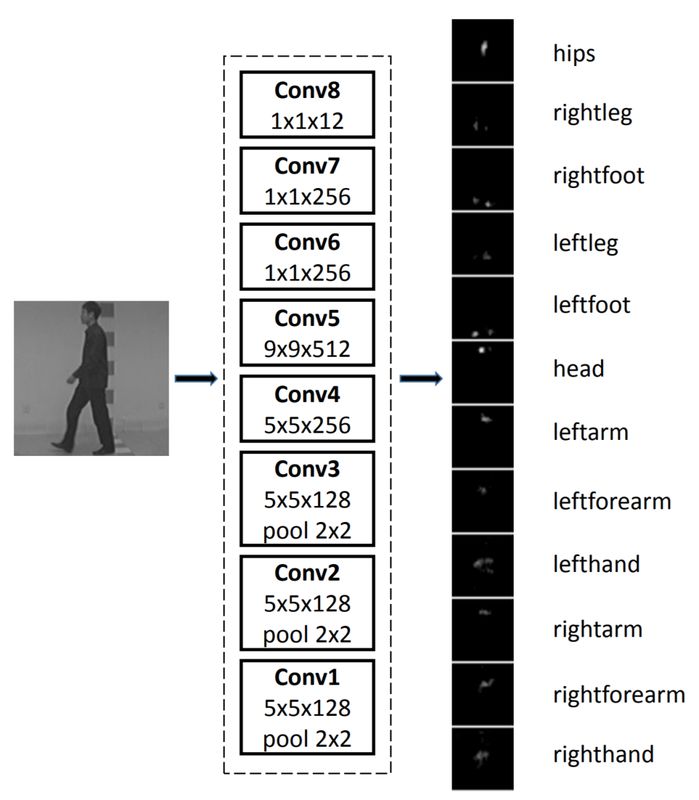
The original research and the image data used are provided here: https://vision.unipv.it/CV/materiale2016-17/3rd%20Choice/0213.pdf.
Research papers on video surveillance and gait recognition have high citation counts, and it is not surprising that almost all of the research is conducted in China.
The next frontier of research will be complete human pose recognition, whether for identification or labeling (human poses standing, jumping, sitting, etc.), which will propose independent convolutional models for each part of the body. As part of UI, gesture recognition is becoming a research hotspot, especially in the augmented reality field.

The goal of this application is to predict rainfall intensity in a local area over a relatively short time span. This field is also known as “nowcasting.”
98% of human DNA is unencoded, and these unencoded segments are called “introns.” Introns were initially thought to be worthless evolutionary remnants, but geneticists now recognize their value. For example, 93% of disease-related variants are located in these regions. Modeling the nature and function of these regions is an ongoing research effort. Recently, a model called “DanQ” that combines CNN and LSTM has made contributions to solving this challenge.
According to the researchers of DanQ, “The convolutional layer captures regulatory motifs, while the recurrent layer captures long-term dependencies between motifs to learn regulatory ‘syntax’ for improved predictions. Compared to other models, DanQ has achieved significant improvements across multiple metrics. Compared to some related models, DanQ achieved over 50% relative improvement in the area under the ROC curve for certain regulatory markers.”
The original research paper can be found here: https://academic.oup.com/nar/article/44/11/e107/2468300
Some researchers from MIT have created a large number of labeled drumstick sound clips. They used a CNN/LSTM combination method, where CNN is used to recognize visual scenes (the impact of drumsticks in silent videos). However, since sound clips are sequential and extend over several frames, they used LSTM layers to match sound clips with appropriate frames.
According to the researchers’ reports, people are fooled by the predicted sound matches over 50% of the time.
You can view the video here: https://www.youtube.com/watch?t=0s&v=flOevlA9RyQ
I am very surprised to see a large amount of research where researchers combine CNN and RNN to gain the advantages of both. Some studies even use GANs in hybrid networks, which is very interesting.
Although this combined model seems to offer better capabilities, there is currently another new research direction that is attracting more attention. This research direction suggests that CNN alone is sufficient, and the RNN/LSTM combination model is not a long-term solution.
A group of researchers proposed a novel deep forest architecture. This architecture is embedded in the node structure, outperforming CNN and RNN, while reducing computational resources and complexity.
We are also paying attention to more mainstream directions such as those taken by companies like Facebook and Google. Both companies have recently stopped using RNN/LSTM-based tools in their voice translation products in favor of TCN (Temporal Convolutional Net).
Typically, for temporal issues, especially for text problems, RNN has inherent design issues. RNN reads and interprets one character (or word, or image) in the input text at a time, meaning that the deep neural network must wait until the current character is processed before moving on to the next one.
This means that RNN cannot utilize large-scale parallel processing (MPP) like CNN. Especially when RNN/LSTM needs to run simultaneously to better understand context.
This is an insurmountable barrier that will undoubtedly limit the utility of RNN/LSTM architectures. TCN resolves this issue by using CNN architectures. The CNN architecture can easily implement new concepts like “attention” and “gate hopping” with MPP acceleration.
For detailed content, please refer to our original paper: https://www.datasciencecentral.com/profiles/blogs/temporal-convolutional-nets-tcns-take-over-from-rnns-for-nlp-pred
Of course, I cannot summarize the entire research field. Even for cases where minimal latency requirements are not as strict as in speech translation, I cannot list all the research one by one. However, for all the applications we introduced above, it seems entirely possible to reconsider whether this new method of TCN is applicable.
Bill Vorhies’ blog post:
https://www.datasciencecentral.com/profiles/blog/list?user=0h5qapp2gbuf8
Bill Vorhies is the editor-in-chief of Data Science Central and has been engaged in data science research since 2001. He can be contacted at [email protected] or [email protected].
View the original English text:
https://www.datasciencecentral.com/profiles/blogs/combining-cnns-and-rnns-crazy-or-genius

If you liked this article or want to see more similar quality reports, remember to leave me a message and give it a thumbs up!