
With the launch of ChatGPT by OpenAI, generative artificial intelligence (AI) has begun to create a global sensation. This wave has not only attracted the attention of the general public but has also become a hot topic in the investment community. According to the Nikkei, the total market value of over 100 large-scale generative AI companies worldwide has reached $48 billion, far exceeding the levels of 2020, and this trend is led by OpenAI.
However, in this fiercely competitive field, OpenAI is not the only player. Competitors such as Jasper, DeepMind, Stability, and Cohere are also rising. As a startup originating from Canada, how has Cohere managed to stand out in this intense competition and gain favor from numerous investors? We will delve into the company’s development history and analyze the differences between its products and ChatGPT.
Cohere Founders: Aidan Gomez, Nick Frosst, and Ivan Zhang
Cohere was co-founded in 2019 by three founders: Aidan Gomez, Nick Frosst, and Ivan Zhang. They jointly established this natural language processing (NLP) company with the aim of providing API services using large NLP models to enhance computers’ understanding and generation capabilities of text, thereby promoting the development and application of NLP technology.

Aidan Gomez and Nick Frosst, as co-founders of Cohere, both served as researchers at Google, accumulating rich technical and industry experience. Among them, Aidan Gomez is one of the authors of the paper “Attention Is All You Need,” which proposed a new network architecture—Transformer, hailed as the “ancestor” that laid the foundation for subsequent large-scale language models like ChatGPT.
Cohere’s Business Model
Cohere’s business model mainly revolves around its natural language processing (NLP) technology and related products, aiming to provide enterprises with powerful language understanding and generation solutions.
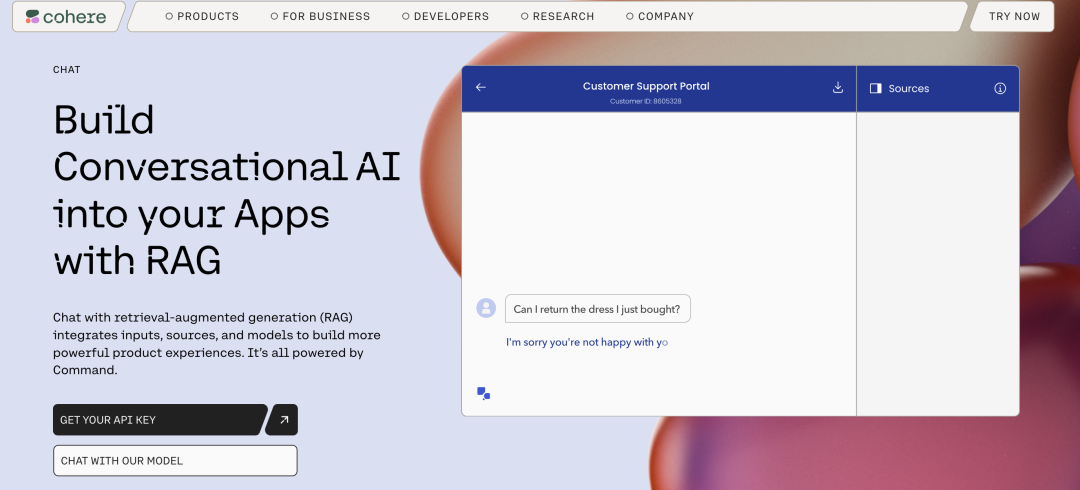
-
API Service Sales: Cohere provides API services that allow enterprises to easily integrate their natural language processing technology into their applications. -
Customized Solutions for Enterprises: In addition to general API services, Cohere also offers customized solutions for enterprises. By deeply understanding customers’ needs and business scenarios. -
Training and Consulting Services: Cohere also provides training and consulting services to help enterprises utilize its technology for model customization and optimization. These services include model tuning, data labeling, and performance evaluation.
Cohere API Features
-
Generate: Use scalable and cost-effective generative AI tools to write product descriptions, blog posts, press releases, and marketing copy. -
Summarize: Extract concise and accurate summaries of articles, emails, and documents. -
Neural Search: Build accurate, high-performance semantic text search in English or over 100 languages, suitable for any document type. -
Classify: For text classification tasks such as customer support routing, intent recognition, and sentiment analysis. -
Embed: Access a managed embedding model that outperforms open-source software, usable in English and over 100 languages, to develop your own functionalities.
API Examples
Chat
Generates a text response to a user message.
import cohere
co = cohere.Client('<<apikey>>')
response = co.chat(
chat_history=[
{"role": "USER", "message": "Who discovered gravity?"},
{"role": "CHATBOT", "message": "The man who is widely credited with discovering gravity is Sir Isaac Newton"}
],
message="What year was he born?",
# perform web search before answering the question. You can also use your own custom connector.
connectors=[{"id": "web-search"}]
)
</apikey>Embed
Embeddings can be used to create text classifiers as well as empower semantic search.
When using the model, please ensure to specify the appropriate input type and the desired embedding type based on your specific use case and requirements.
-
Available Models:
-
embed-english-v3.0: Embedding dimension is 1024. -
embed-multilingual-v3.0: Embedding dimension is 1024. -
input_type: Specify the input type passed to the model. This is required for embedding models v3 and above.
-
“search_document”: For embeddings used in search use cases stored in a vector database. -
“search_query”: For embeddings used to run search queries against a vector database to find relevant documents. -
“classification”: For embeddings passed through a text classifier. -
“clustering”: For embeddings run through clustering algorithms. -
embedding_types: Specify the types of embeddings you wish to obtain.
import cohere
co = cohere.Client('<<apikey>>')
response = co.embed(
texts=['hello', 'goodbye'],
model='embed-english-v3.0',
input_type='classification'
)
print(response)
</apikey>Rerank
Takes in a query and a list of texts and produces an ordered array with each text assigned a relevance score.
import cohere
co = cohere.Client('<<apikey>>')
docs = ['Carson City is the capital city of the American state of Nevada.',
'The Commonwealth of the Northern Mariana Islands is a group of islands in the Pacific Ocean. Its capital is Saipan.',
'Washington, D.C. (also known as simply Washington or D.C., and officially as the District of Columbia) is the capital of the United States. It is a federal district.',
'Capital punishment (the death penalty) has existed in the United States since before the United States was a country. As of 2017, capital punishment is legal in 30 of the 50 states.']
response = co.rerank(
model = 'rerank-english-v2.0',
query = 'What is the capital of the United States?',
</apikey>Classify
Prediction about which label fits the specified text inputs best. To make a prediction.
import cohere
from cohere import ClassifyExample
co = cohere.Client('<<apikey>>')
examples=[
ClassifyExample(text="Dermatologists don't like her!", label="Spam"),
ClassifyExample(text="'Hello, open to this?'", label="Spam"),
ClassifyExample(text="I need help please wire me $1000 right now", label="Spam"),
ClassifyExample(text="Nice to know you ;)", label="Spam"),
ClassifyExample(text="Please help me?", label="Spam"),
ClassifyExample(text="Your parcel will be delivered today", label="Not spam"),
ClassifyExample(text="Review changes to our Terms and Conditions", label="Not spam"),
ClassifyExample(text="Weekly sync notes", label="Not spam"),
ClassifyExample(text="'Re: Follow up from today's meeting'", label="Not spam"),
ClassifyExample(text="Pre-read for tomorrow", label="Not spam"),
]
inputs=[
"Confirm your email address",
"hey i need u to send some $",
]
response = co.classify(
inputs=inputs,
examples=examples,
)
print(response)
</apikey>Tokenize
Splits input text into smaller units called tokens using byte-pair encoding (BPE).
import cohere
co = cohere.Client('<<apikey>>')
response = co.tokenize(
text='tokenize me! :D',
model='command' # optional
)
print(response)
</apikey># Learn Large Models & Discuss Kaggle #
Daily large model, algorithm competition, dry goods information
