
Machine Heart reports
Researchers from the University of Rochester and Adobe Research have proposed a new generative network CM-GAN, which synthesizes overall structure and local details very well, significantly outperforming existing SOTA methods such as CoModGAN and LaMa in both quantitative and qualitative evaluations.
Image inpainting refers to the process of filling in missing areas of an image and is one of the fundamental tasks in computer vision. This area has many practical applications, such as object removal, image re-targeting, and image synthesis.
Early inpainting methods relied on image patch synthesis or color diffusion to fill in missing parts of images. To handle more complex image structures, researchers have begun to turn to data-driven approaches, utilizing deep generative networks to predict visual content and appearance. By training on a large number of images and leveraging reconstruction and adversarial losses, generative inpainting models have been shown to produce visually appealing results across various types of input data, including natural images and faces.
However, existing works have only demonstrated good results in completing simple image structures, and generating image content with complex overall structures and high-fidelity details remains a significant challenge, especially when the image holes are large.
Essentially, image inpainting faces two key issues: one is how to accurately propagate global context to the incomplete areas, and the other is to synthesize realistic local details consistent with global cues. To address the global context propagation issue, existing networks utilize encoder-decoder architectures, dilated convolutions, contextual attention, or Fourier convolutions to integrate long-range feature dependencies and expand the effective receptive field. Additionally, two-stage methods and iterative dilated filling rely on predicting coarse results to enhance global structure. However, these models lack a mechanism to capture high-level semantics from unmasked regions and effectively propagate them into the holes to synthesize a coherent global structure.
Based on this, researchers from the University of Rochester and Adobe Research proposed a new generative network: CM-GAN (cascaded modulation GAN), which can better synthesize overall structure and local details. CM-GAN includes an encoder with Fourier convolution blocks to extract multi-scale feature representations from input images with holes. CM-GAN also features a dual-stream decoder that sets a novel cascaded global spatial modulation block at each scale layer.
In each decoder block, the researchers first apply global modulation to perform coarse and semantically aware structural synthesis, followed by spatial modulation to further adjust feature maps in a spatially adaptive manner. Furthermore, the study designed an object-aware training scheme to prevent artifacts from occurring within the holes, thereby meeting the requirements of object removal tasks in real-world scenarios. Extensive experiments show that CM-GAN significantly outperforms existing methods in both quantitative and qualitative evaluations.

-
Paper link: https://arxiv.org/pdf/2203.11947.pdf
-
Project link: https://github.com/htzheng/CM-GAN-Inpainting
Let’s first look at the image inpainting results; compared to other methods, CM-GAN can reconstruct better textures:

CM-GAN can synthesize better global structures:

CM-GAN has better object boundaries:

Next, let’s take a look at the methods and experimental results of this study.
Method
Cascaded Modulation GAN
To better model the global context of image completion, this study proposes a new mechanism that cascades global code modulation with spatial code modulation. This mechanism helps to deal with partially invalid features while better injecting global context into the spatial domain. The new architecture CM-GAN can effectively integrate overall structure and local details, as shown in Figure 1 below.

As shown in Figure 2 (left), CM-GAN generates visual outputs based on an encoder branch and two parallel cascaded decoder branches. The encoder takes partial images and masks as input to generate multi-scale feature maps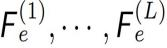 .
.
Unlike most encoder-decoder methods, to achieve overall structure, this study extracts global style codes s from the highest-level features of the fully connected layer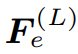 and then performs
and then performs normalization. Additionally, an MLP-based mapping network generates style codes w from noise to simulate the randomness of image generation. The code w is combined with s to produce a global code g = [s; w], which is used for subsequent decoding steps.
normalization. Additionally, an MLP-based mapping network generates style codes w from noise to simulate the randomness of image generation. The code w is combined with s to produce a global code g = [s; w], which is used for subsequent decoding steps.
Global spatial cascaded modulation. To better connect global context during the decoding phase, this study introduces global spatial cascaded modulation (CM). As shown in Figure 2 (right), the decoding phase is based on two branches: global modulation blocks (GB) and spatial modulation blocks (SB), which upsample global features F_g and local features F_s in parallel.
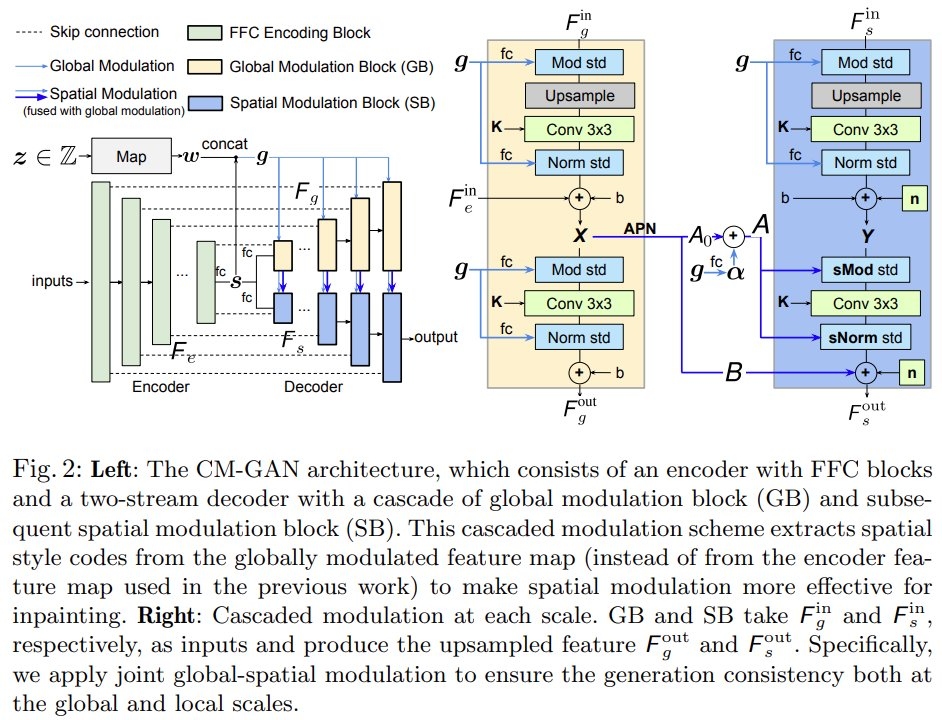
Unlike existing methods, CM-GAN introduces a new method to inject global context into the hole regions. Conceptually, it consists of cascaded global and spatial modulation between features at each scale and naturally integrates three compensation mechanisms for global context modeling: 1) feature upsampling; 2) global modulation; 3) spatial modulation.

Object-Aware Training
Training algorithms for generating masks are crucial. Essentially, the sampled masks should resemble the masks drawn in real use cases, and the masks should avoid covering entire objects or most of any new objects. Over-simplified masking schemes may lead to artifacts.
To better support real object removal use cases while preventing the model from synthesizing new objects within the holes, this study proposed an object-aware training scheme that generates more realistic masks during training, as shown in Figure 4 below.

Specifically, the study first passes the training images to the Panoptic Segmentation Network PanopticFCN to generate highly accurate instance-level segmentation annotations, then samples a mix of free holes and object holes as initial masks, and finally calculates the overlap rate between the holes and each instance in the image. If the overlap rate exceeds a threshold, the method excludes foreground instances from the holes; otherwise, the holes remain unchanged and simulate object completion, with the threshold set to 0.5. The study randomly expands and translates object masks to avoid overfitting. Additionally, the study also expands holes on the instance segmentation boundaries to avoid leaking background pixels near the holes into the repaired area.
Training Objectives and Masked-R_1 Regularization
The model is trained by combining adversarial loss and segmentation-based perceptual loss. Experiments show that the method can achieve good results even when only using adversarial loss, but adding perceptual loss can further enhance performance.
Moreover, the study also proposed a masked-R_1 regularization specifically for stabilizing repair tasks, which uses the mask m to avoid calculating gradient penalties outside the mask.
Experiments
The study conducted image inpainting experiments on the Places2 dataset at a resolution of 512 × 512 and provided quantitative and qualitative evaluation results for the model.
Quantitative evaluation: Table 1 compares CM-GAN with other masking methods. The results show that CM-GAN significantly outperforms other methods in terms of FID, LPIPS, U-IDS, and P-IDS. With the help of perceptual loss, LaMa and CM-GAN achieved significantly better LPIPS scores than CoModGAN and other methods, thanks to the additional semantic guidance provided by the pre-trained perceptual model. Compared to LaMa/CoModGAN, CM-GAN reduced FID from 3.864/3.724 to 1.628.
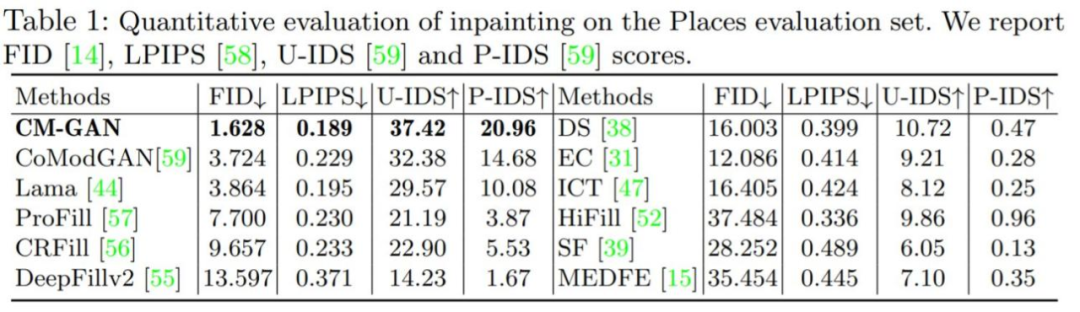
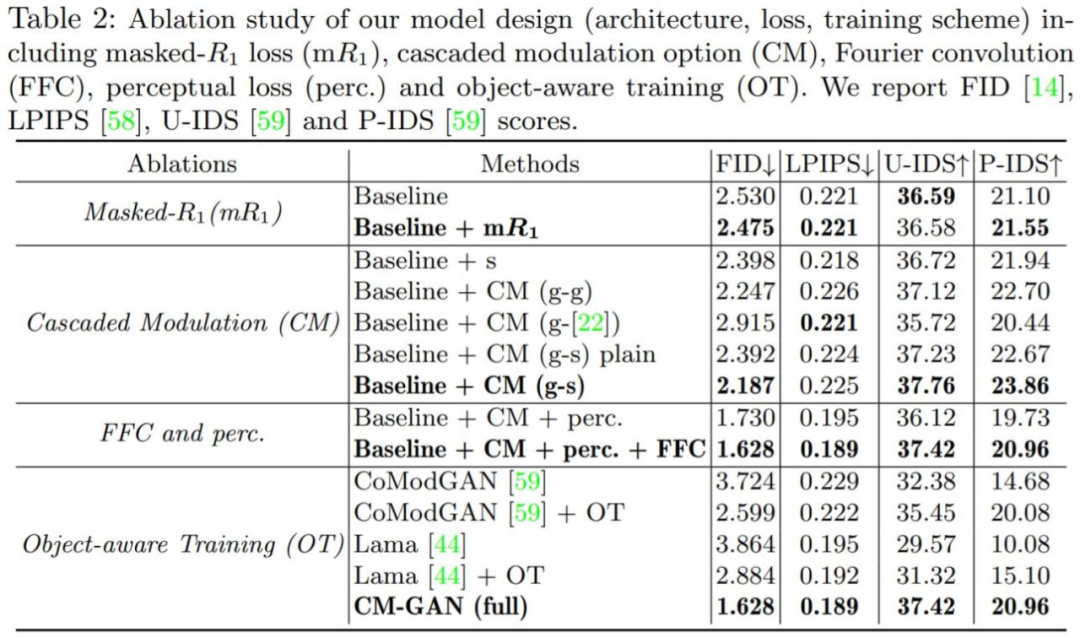
As shown in Table 3, with and without fine-tuning, CM-GAN achieved significant performance gains over LaMa and CoModGAN masks, indicating that the model has generalization capabilities. Notably, CM-GAN trained on CoModGAN masks and object-aware masks still outperformed CoModGAN masks, confirming that CM-GAN has better generative capabilities.
Qualitative evaluation: Figures 5, 6, and 8 show visual comparison results of CM-GAN with SOTA methods in synthesized masks. ProFill can generate incoherent global structures, CoModGAN produces structural artifacts and color spots, and LaMa tends to produce large image blurs in natural scenes. In contrast, the CM-GAN method generates more coherent semantic structures and clearer textures, making it applicable to different scenes.



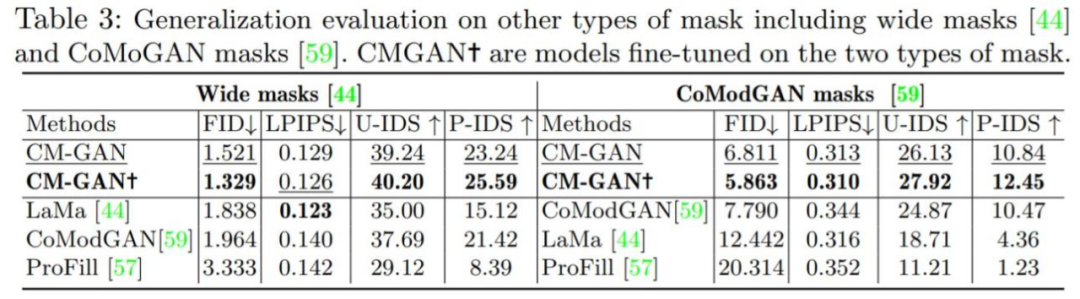
To verify the importance of each component in the model, the study conducted a series of ablation experiments, with all models trained and evaluated on the Places2 dataset. The results of the ablation experiments are shown in Table 2 and Figure 7 below.

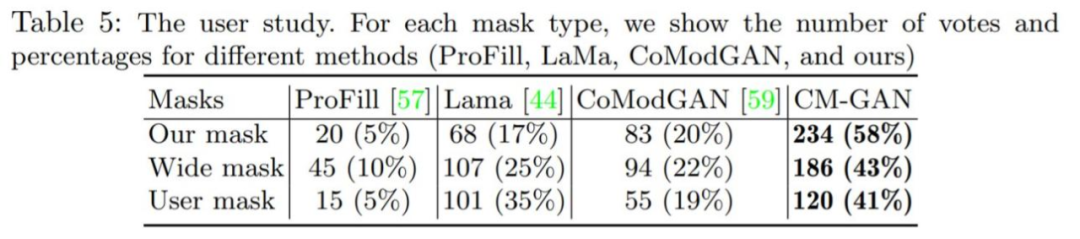
The study also conducted user studies to better assess the visual generation quality of the CM-GAN method, with results shown in Table 5 below. Additionally, the appendix provides more visual comparisons and experimental analyses for readers’ reference.
© THE END
For reprints, please contact this public account for authorization
Submission or reporting inquiries: [email protected]