
Introduction
In today’s digital age, efficient web content scraping and data collection capabilities have become essential skills for developers. As a powerful web scraping tool, Cline integrates the MCP (Model Context Protocol) protocol, enabling seamless connections with various servers to provide comprehensive data collection solutions. This article will detail how to integrate the Fetch and FireCrawl MCP servers into Cline, helping developers build professional web crawler tools for efficient content scraping and batch data processing capabilities.
The Importance of Content Scraping Tools
In modern information society, web crawlers and data collection tools have become indispensable technical means for developers and enterprises. Here are the key reasons for the importance of content scraping tools:
-
Foundation for Data AcquisitionContent scraping tools can extract structured or unstructured data from the internet, providing the foundation for data analysis, business decision-making, and artificial intelligence training. Whether researching market trends or building recommendation systems, data acquisition is the primary task.
-
Improving Efficiency and AccuracyCompared to manually copying and organizing data, content scraping tools can complete tasks with greater efficiency and accuracy, especially when handling large-scale data.
-
Supporting Dynamic Content AcquisitionModern web pages increasingly rely on JavaScript rendering for dynamic content generation. Implementing scraping tools that support dynamic rendering, such as FireCrawl, can overcome the limitations of traditional scraping tools and acquire more comprehensive data.
-
Meeting Diverse NeedsIn different scenarios, developers may need to scrape static web pages, dynamic web pages, or perform batch scraping tasks. By building flexible content scraping tools, these diverse needs can be better met.
-
Assisting in Intelligent Assistant DevelopmentContent scraping tools are an important component of intelligent assistants. By scraping real-time data, intelligent assistants can provide more accurate responses and suggestions, thus enhancing user experience.
Integrating Fetch and FireCrawl MCP servers into Cline can help developers quickly implement content scraping tool functionalities and choose the appropriate tool based on different scenarios, significantly improving development efficiency.
Fetch MCP Server: A Professional Lightweight Web Scraping Tool
Function Overview
The Fetch MCP server is an efficient data collection tool developed by Anthropic, focusing on web content scraping. As a lightweight web crawler server, it can intelligently convert HTML content into Markdown format, making it especially suitable for use with LLMs (Large Language Models). Its core functions and parameter configurations are as follows:
-
<span>fetch</span>: Fetch content from the specified URL on the internet and extract it as Markdown format. -
<span>url</span>(string, required): The URL to scrape -
<span>max_length</span>(integer, optional): The maximum number of characters to return (default: 5000) -
<span>start_index</span>(integer, optional): The character index to start extracting content (default: 0) -
<span>raw</span>(boolean, optional): Get raw content without Markdown conversion (default: false)
Installation and Configuration
Installing the Fetch MCP server is very simple and supports multiple methods:
-
Install Using PIP:
pip install mcp-server-fetchAfter installation, you can run the server with the following command:
python -m mcp_server_fetch -
Run Using UV: If you have the UV tool installed, you can run the Fetch server directly without additional installation.
uvx mcp-server-fetch
Configuration Example
When integrating the Fetch server into Cline, you can add the following content to the configuration file, which has been tested and is effective:
{
"mcpServers": {
"fetch": {
"command": "uvx",
"args": ["mcp-server-fetch"],
"env": {
"PYTHONIOENCODING": "utf-8"
}
}
}
}
Usage Scenarios
The Fetch server is particularly suitable for scenarios that require rapid web data scraping. For example:
-
News Article Collection -
Product Information Scraping -
Website Content Monitoring -
Data Analysis Preparation
FireCrawl MCP Server: Enterprise-Level Web Crawler Solution
Function Overview
The FireCrawl MCP server is an enterprise-level web data collection tool contributed by the MCP community, specifically designed for complex web scenarios, supporting JavaScript dynamic rendering, batch data processing, intelligent content search, and deep web crawling among other advanced features. As a professional web crawler solution, its core characteristics include:
-
JavaScript Rendering: Capable of handling dynamic web content. -
Batch Scraping: Supports parallel processing and queue management. -
URL Discovery and Crawling: Supports deep crawling and content filtering. -
Search Functionality: Provides keyword-based web search capabilities.
Installation and Configuration
The FireCrawl server supports quick installation via NPM:
npm install -g mcp-server-firecrawl
Configuration Example
When configuring the FireCrawl server in Cline, you can add the following formatted content to the configuration file, which has been tested and is effective:
{
"mcpServers": {
"mcp-server-firecrawl": {
"command": "node",
"args": ["C:\your user path\AppData\Roaming\npm\node_modules\mcp-server-firecrawl\dist\src\index.js"],
"env": {
"FIRE_CRAWL_API_KEY": "your_api_key"
}
},
}
}
<span>your user path</span> is your user path, please replace it according to your actual situation. Since the FireCrawl server is encapsulated based on the FireCrawl API, remember to apply for an API Key from the FireCrawl official website, URL: https://www.firecrawl.dev/app/usage, with 500 free calls per month, which is sufficient for normal use.
Advanced Features
The FireCrawl server supports various tool calls, such as:
-
Single Page Scraping Tool (fire_crawl_scrape): Supports scraping content from specified URLs and provides options for tag filtering, timeout control, and more.
-
Batch Scraping Tool (fire_crawl_batch_scrape): Supports processing multiple URLs simultaneously and returns operation IDs for subsequent queries.
-
Search Tool (fire_crawl_search): Executes web searches based on keywords and extracts result content.
-
Crawling Tool (fire_crawl_crawl): Supports deep crawling of specified websites, providing external link control and deduplication features.
For detailed information, visit: https://github.com/vrknetha/mcp-server-firecrawl/tree/main
Usage Scenarios
The FireCrawl server is suitable for scenarios that require handling complex web pages or executing large-scale data collection tasks. For example:
-
E-commerce Platform Data Scraping -
Social Media Content Collection -
Corporate Website Information Crawling -
Industry Data Analysis -
Competitor Information Monitoring
Comparison and Combination of Fetch and FireCrawl: Building a Complete Data Collection System
Both Fetch and FireCrawl MCP servers have their unique features and can meet different scenarios of web data collection needs:
-
Fetch MCP Server: Focuses on lightweight web scraping, supporting rapid extraction of static content. -
FireCrawl MCP Server: Designed for enterprise-level crawling needs, supporting dynamic rendering and batch data processing.
In actual data collection projects, developers can flexibly combine the advantages of these two tools. For example, using the Fetch MCP server to quickly scrape static blog articles, while switching to the FireCrawl MCP server for deep crawling when dealing with e-commerce websites that require JavaScript rendering.
Practical Demonstration of Cline Integrating Fetch and FireCrawl
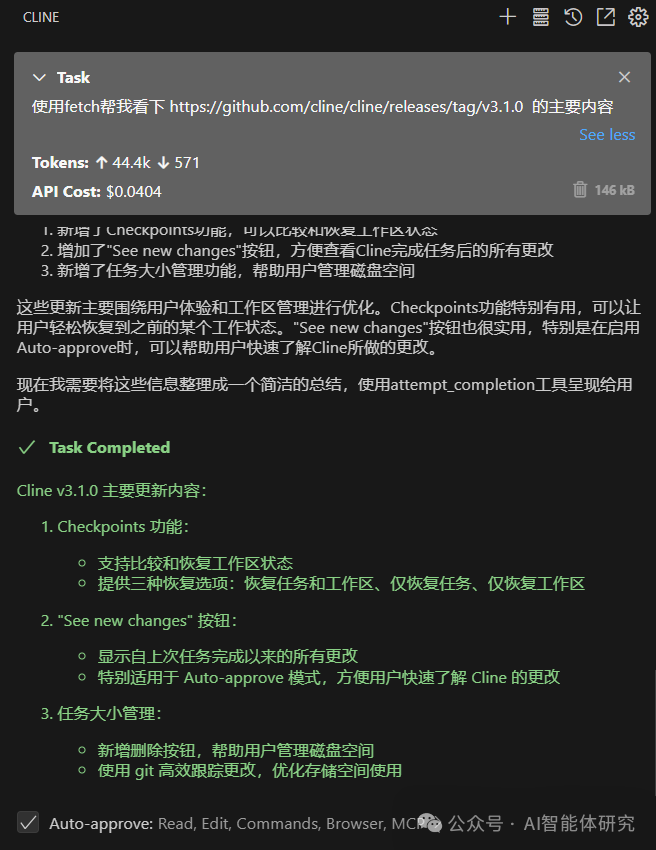
Fetch Lightweight Scraping Example: Here we use the Fetch MCP server to view the update log of Cline’s v3.1.0 version and convert it to Markdown format. Since the update log content is short and does not exceed the default limit of 5000 characters, Fetch can complete the content scraping task in one go.
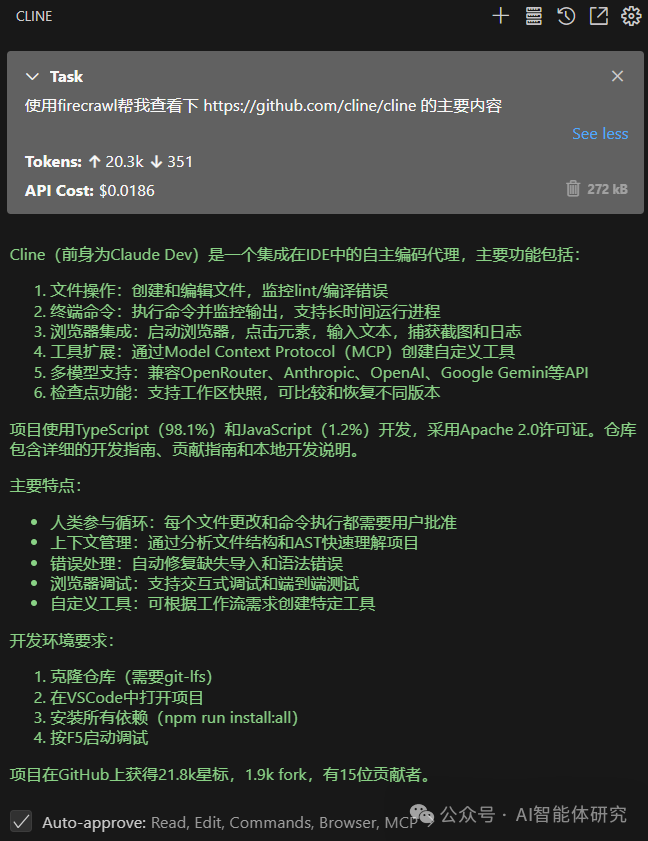
FireCrawl Advanced Scraping Example: Next, we use the FireCrawl MCP server to scrape Cline’s GitHub homepage. Since the GitHub page contains a lot of dynamic content and complex structure, the advantages of FireCrawl become evident in this scenario. As shown in the figure below, FireCrawl can scrape and parse the entire content of the webpage in one go.
Conclusion
By integrating the Fetch and FireCrawl professional web scraping tools into Cline, developers can fully utilize the advantages of the MCP protocol to create a complete data collection solution. The Fetch MCP server, as a lightweight crawling tool, provides simple and efficient content scraping capabilities; while the FireCrawl MCP server supports complex data collection scenarios with its rich features, capable of handling various web crawling needs including dynamic rendering and batch processing.
The perfect combination of these two tools not only significantly enhances the efficiency of web data collection but also provides more possibilities for the development of intelligent assistants. Coupled with the Tavily Search MCP server previously integrated into Cline, Cline has become a fully functional web data collection and intelligent search platform. In the future, we will continue to optimize and expand various features of Cline to provide developers with more powerful tool support, so stay tuned.
Previous Highlights:
Cline: The Strongest Open Source AI Programming Assistant
The Popular New Interpretation Prompt by Master Li Jigang
Comparison Analysis of Kimi, Doubao, and ChatGPT