A deep comparison of agent orchestration using three different frameworks to build the same Agentic Finance App.

Contents We Will Cover
- What is an Agent? A deep dive into how we define agents and how they differ from AI pipelines and standalone LLMs.
- Practical Examples Using Three Popular Agent Frameworks: LangGraph, CrewAI, and OpenAI Swarm (full code).
- Our Recommendations on When to Use Which Framework.
- What’s Next: A preview of the second part, where we will explore the debuggability and observability of these frameworks.
Introduction
LLM-driven autonomous agents have seen ups and downs. From the viral demos of AutoGPT and BabyAGI in 2023 to the more refined frameworks of today, the concept of agents (LLMs capable of autonomously executing end-to-end tasks) has captured both imagination and skepticism.
Why has interest been rekindled? In the past 9 months, LLMs have seen significant upgrades: longer context windows, structured outputs, better reasoning, and simpler tool integrations. These advancements have made building reliable agent applications more feasible than ever.
In this blog, we will explore three popular frameworks for building agent applications: LangGraph, CrewAI, and OpenAI Swarm. By using the Agentic Finance Assistant, we will highlight the strengths, weaknesses, and practical use cases of each framework.
What is an Agent?
An agent is an advanced system powered by large language models (LLMs) that can interact independently with the environment and make decisions in real-time. Unlike traditional LLM applications, which are constructed as rigid predefined pipelines (e.g., A → B → C), agent workflows introduce a dynamic and adaptive approach. Agents leverage tools (functions or APIs that allow interaction with the environment) to determine the next action based on context and goals. This flexibility enables agents to deviate from fixed sequences, allowing for more autonomous and efficient workflows tailored to complex and evolving tasks.
However, this flexibility also brings a host of challenges:
- Managing state and memory across tasks.
- Coordinating multiple sub-agents and their communication patterns.
- Ensuring reliable tool calls and handling complex error cases that arise.
- Scaling reasoning and decision-making.
Why We Need Agent Frameworks
Building agents from scratch is not an easy task. Frameworks like LangGraph, CrewAI, and OpenAI Swarm simplify this process, allowing developers to focus on their application logic without having to reinvent the wheel for state management, orchestration, and tool integration.
At their core, agent frameworks provide
- A simple way to define agents and tools.
- Orchestration mechanisms.
- State management.
- Additional tools to support more complex applications, such as: persistence layer (memory), interruptions, etc.
We will introduce these in the following sections.
Introducing Agent Frameworks

We have chosen LangGraph, CrewAI, and OpenAI Swarm, because they represent the latest schools of thought in the field of agent development. Here’s a brief overview:
- LangGraph: As the name suggests, LangGraph views graph architecture as the best way to define and orchestrate agent workflows. Unlike earlier versions of LangChain, LangGraph is a well-designed framework with many powerful and customizable features built for production. However, it can sometimes be more complex than necessary for certain use cases and can incur additional overhead.
- CrewAI: In contrast, getting started with CrewAI is much simpler. It has an intuitive abstraction that helps you focus on task design rather than writing complex orchestration and state management logic. However, its downside is that it is a highly subjective framework and can be harder to customize later on.
- OpenAI Swarm: OpenAI describes it as a lightweight, minimalist framework that is “educational” rather than “production-ready.” OpenAI Swarm almost represents an “anti-framework”—leaving many functionalities to developers to implement or to powerful LLMs themselves to solve. We believe it could be a perfect choice for those with currently simple use cases or those looking to integrate flexible agent workflows into existing LLM pipelines.

Other Notable Frameworks
- LlamaIndex Workflow: An event-driven framework that conceptually fits many agent workflows. However, as it stands, we find it still requires developers to write a lot of boilerplate code to make it work. The LlamaIndex team is actively improving the Workflow framework, and we hope they can create more advanced abstractions soon.
- AutoGen: AutoGen is a framework developed by Microsoft for multi-agent dialogue orchestration, which has been used for various agent use cases. The AutoGen team has learned from early versions’ mistakes and feedback and is completely rewriting it (from v0.2 to v0.4) to make it an event-driven orchestration framework.
Building the Agentic Finance Assistant
To benchmark these frameworks, we built the same Agentic Finance Assistant. The full code for the constructed application can be found here: Relari Agent Example.
We want the agent to handle complex queries such as:
- How is Spirit Airlines’ financial situation compared to its competitors?
- What is Apple’s best-performing product line from a financial perspective? What are they marketing on their website?
- Help me find consumer stocks with a market cap under $5 billion and year-over-year revenue growth over 20%
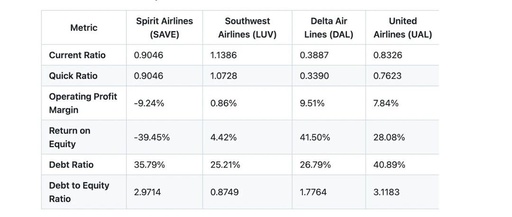
Here’s an example snippet of a comprehensive response we hope to see from the assistant:
To achieve this, we provided the agent system with access to the financial database via the FMP API and internet access to research online content.
One of the primary choices we need to consider when building agent-based AI applications is the architecture. There are various architectures, each with its pros and cons. The following diagram summarizes some popular architectures as outlined by LangGraph (you can read more about architecture choices here: Multi-Agent Architectures).
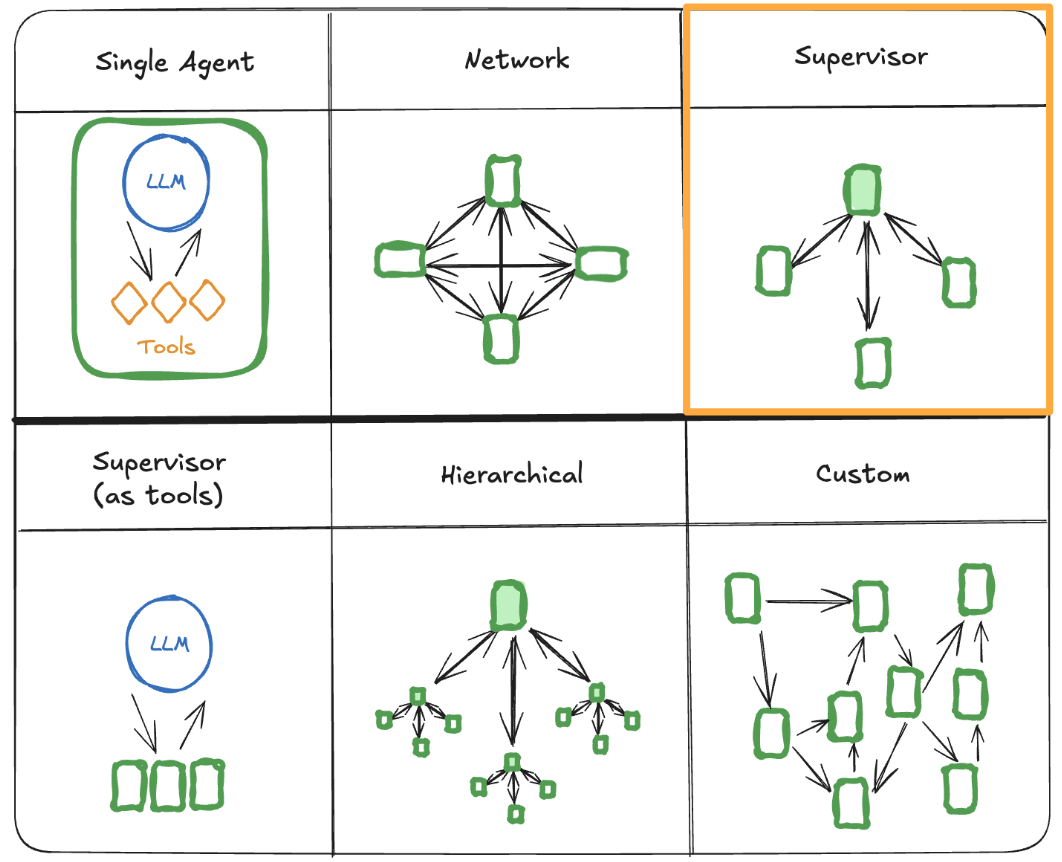
For educational purposes, we chose the Supervisor architecture for this application. Thus, we will create a Supervisor Agent whose task is to decide which sub-agent to delegate tasks to, along with three sub-agents with tool access: a financial data agent, a web research agent, and an output summarizing agent.

Let’s explore how each framework handles agent creation, tool integration, orchestration, memory, and human interaction.
1. Defining Agents and Tools
We first look at how to define general agents like the financial data agent, web research agent, and output summarizing agent, and declare their relevant tools in each framework. The supervisor agent is a special agent that plays the orchestration role, so we will introduce it in the orchestration section.
LangGraph
The easiest way to create a simple tool-calling agent is to use the <span>create_react_agent</span> prebuilt function as shown below, where we can provide the tools and prompts we want the agent to use.
from langgraph.prebuilt import create_react_agent
from langchain_openai import ChatOpenAI
from langchain_core.tools import Tool
# Below is an example of tool definition
@tool
def get_stock_price ( symbol: str ) -> dict :
"""Get the current stock price for the given symbol.
Parameters:
symbol (str): The stock ticker (e.g., "AAPL" for Apple Inc.).
Returns:
dict: A dictionary containing the stock price or error message.
"""
base_url = "https://financialmodelingprep.com/api/v3/quote-short"
params = { "symbol" : symbol, "apikey" : os.getenv( "FMP_API_KEY" )}
response = request.get(base_url, params=params)
if response.status_code == 200 :
data = response.json()
if data:
return { "price" : data[ 0 ][ "price" ]}
return { "error" : "Unable to retrieve stock price." }
# Below is a simple React agent example
financial_data_agent = create_react_agent(
ChatOpenAI(model= "gpt-4o-mini" ),
tools=[get_stock_price, get_company_profile, ...],
state_modifier= "You are a financial data agent responsible for retrieving financial data using the provided API tools..." ,
)In LangGraph, everything is constructed in the form of a graph. The utility function <span>create_react_agent</span> creates a simple executable graph with agent nodes and tool nodes.
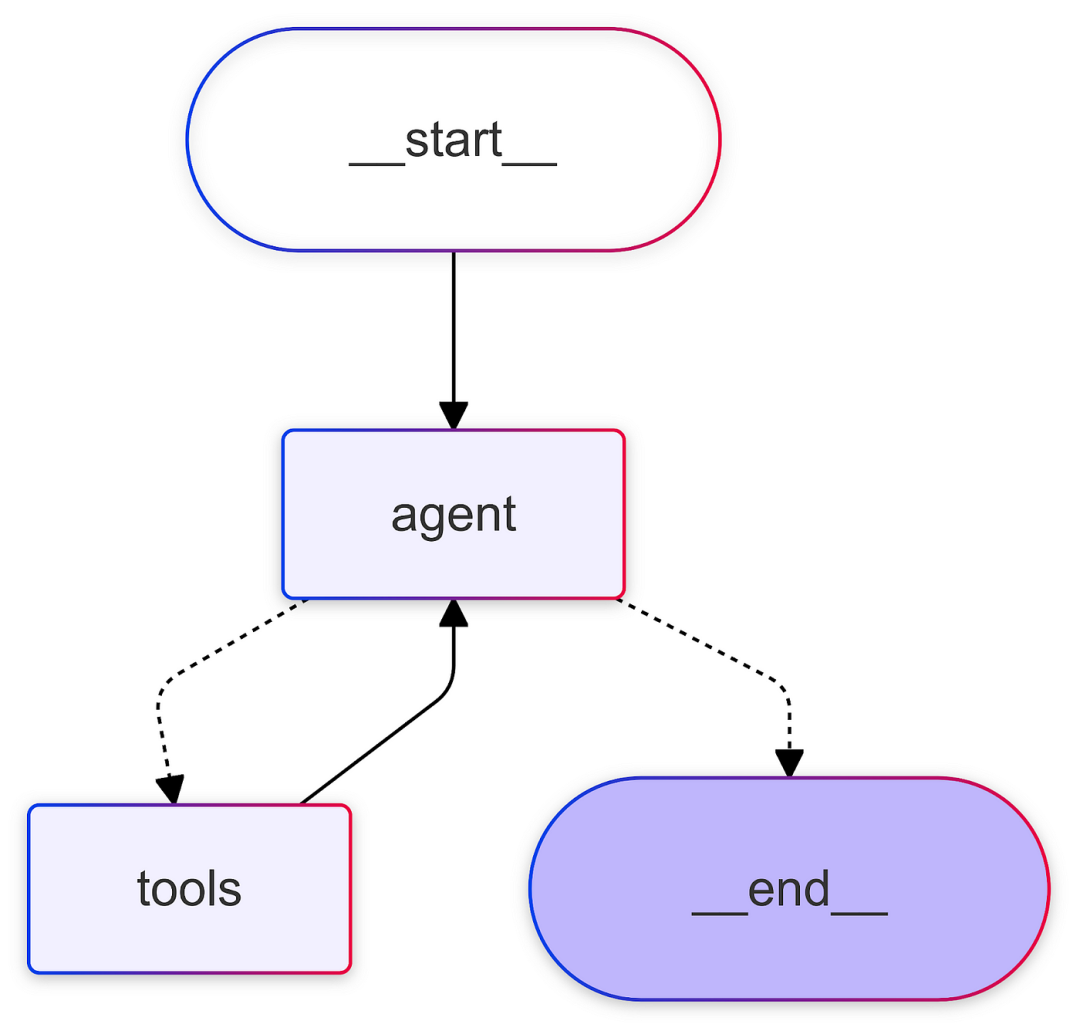
Agents act as decision-makers, dynamically determining which tools to call and assessing whether it has sufficient information to transition to the <span>__end__</span> state.
In the diagram, solid lines represent deterministic edges (the tool nodes must always return to the agent), while dashed lines represent conditional edges, where the LLM-driven agent is deciding where to go next.
Nodes and edges are the basic building blocks of a graph. We will see later in the orchestration section that this graph can represent nodes in a larger, more complex graph.
CrewAI
The agent definition in CrewAI revolves around the relationship between agents and tasks (the tasks that the agent is supposed to complete).
For each agent, we must define its <span>role</span>, <span>goal</span>, and <span>backstory</span>, and specify the tools it can access.
from crewai import Agent, Task
financial_data_agent = Agent(
role= "Financial Data Agent",
goal= "Retrieve comprehensive financial data using the FMP API to provide the data needed to answer user queries",
backstory= """You are an experienced financial data gatherer with a wealth of experience in collecting financial information. Known for your precision and ability to find the most relevant financial data points using the FMP API, which provides financial data on publicly traded companies in the U.S.""",
tools=[
StockPriceTool(),
CompanyProfileTool(),
...
]
)
Next, we must create the tasks that the agent needs to perform. Tasks must include a <span>description</span> and <span>expected_output</span>.
gather_financial_data = Task(
description=( "Conduct thorough financial research to gather relevant financial data to assist in answering user query: {query}. Use available financial tools to obtain accurate and up-to-date information. Focus on finding relevant stock prices, company profiles, financial ratios, and other relevant financial indicators to answer user query: {query}." ),
expected_output= "A set of comprehensive financial data points that directly address the query: {query}." ,
agent=financial_data_agent,
)
This structured approach to building LLM prompts provides a clear and consistent framework, ensuring that agent and task definitions are explicit. While this method helps maintain focus and coherence, it can sometimes feel rigid or repetitive, especially when repeatedly defining roles, goals, backstories, and task descriptions.
Tools can be integrated using the @tool decorator, similar to the method in LangGraph. It’s worth mentioning that we can also extend the BaseTool class, which will be a more powerful way to execute tool input patterns due to the use of Pydantic models (LangGraph supports this method as well).
class StockPriceInput ( BaseModel ):
"""Input schema for stock price queries."""
symbol: str = Field(..., description= "Stock ticker")
class StockPriceTool ( BaseTool ):
name: str = "Get Stock Price"
description: str = "Retrieve the current stock price for the given symbol"
args_schema: Type [BaseModel] = StockPriceInput
def _run ( self, symbol: str ) -> dict :
# Retrieve the stock price for the given symbol using the FMP API
OpenAI Swarm
Swarm takes a different approach: OpenAI does not explicitly define the reasoning flow in code but suggests building the flow in the system prompt as “routines” (in <span>instructions</span>), which are predefined steps or instruction sets that the agent follows to accomplish tasks. OpenAI’s approach makes sense as they prefer developers to rely more on the model’s ability to follow instructions rather than defining custom logic sets in the code. We find this approach simple and effective when using more powerful LLMs that can track routine reasoning.
For tools, we can directly bring them in as tools.
from swarm import Agent
financial_data_agent = Agent(
name= "Financial Data Agent" ,
instructions= """You are a financial data expert responsible for retrieving financial data using the provided API tools. Your tasks:
Step 1. Given the user query, use the appropriate tools to obtain relevant financial data
Step 2. Read the data and ensure they can answer the user query. If not, modify the tool input or use other tools to gather more information.
Step 3. Once sufficient information is collected, return only the raw data obtained from the tools. Do not add comments or explanations.""" ,
functions=[
get_stock_price,
get_company_profile,
...
]
)
2. Orchestration
Now let’s look at the core part of each framework, which is how they integrate multiple sub-agents together.
LangGraph
The core of LangGraph is graph-based orchestration. We first create a supervisor agent that acts as a router, whose sole task is to analyze the situation and decide which agent to call next. The executing agents themselves can only relay results back to the supervisor agent.
LangGraph requires explicitly defining states. The class <span>AgentState</span> helps define common state patterns across different agents.
class AgentState(TypedDict):
messages: Annotated [List[BaseMessage], operator.add]
next: str
For each agent, we interact with the state by wrapping it in a node that converts the agent’s output into a consistent message pattern.
async def financial_data_node(state):
result = await financial_data_agent.ainvoke(state)
return {
"messages": [
AIMessage(
content=result[ "messages" ][-1].content, name="Financial_Data_Agent"
)
]
}
We are now ready to define the agents themselves.
class RouteResponse(BaseModel):
next: Literal [OPTIONS]
def supervisor_agent(state):
prompt = ChatPromptTemplate.from_messages([
("system", ORCHESTRATOR_SYSTEM_PROMPT),
MessagesPlaceholder(variable_name="messages"),
("system", "Based on the above conversation, who should take action next? Or should we finish? Choose one of the following: {options} ",
),
]).partial(options=str(OPTIONS), members=",".join(MEMBERS))
supervisor_chain = prompt | LLM.with_structured_output(RouteResponse)
return supervisor_chain.invoke(state)
Once the supervisor agent is defined, we define the agent workflow as a graph, adding each agent as a node and all execution logic as edges.
When defining edges, we have two options: regular edges or conditional edges. Regular edges can be used when we want deterministic transitions. For example, the financial data agent should always return results to the Supervisor_Agent to decide the next step.
Conditional edges are used when we want the LLM to choose which path to take (for example, the supervisor agent deciding whether there is enough data to send to the output summarizing agent or return data and web agent for more information).
from langgraph.graph import END, START, StateGraph
def build_workflow() -> StateGraph:
"""Build a state graph for the workflow."""
workflow = StateGraph(AgentState)
workflow.add_node("Supervisor_Agent", supervisor_agent)
workflow.add_node("Financial_Data_Agent", financial_data_node)
workflow.add_node("Web_Research_Agent", web_research_node)
workflow.add_node("Output_Summarizing_Agent", output_summarizing_node)
workflow.add_edge("Financial_Data_Agent", "Supervisor_Agent")
workflow.add_edge("Web_Research_Agent", "Supervisor_Agent")
conditional_map = {
"Financial_Data_Agent": "Financial_Data_Agent",
"Web_Research_Agent": "Web_Research_Agent",
"Output_Summarizing_Agent": "Output_Summarizing_Agent",
"FINISH": "Output_Summarizing_Agent",
}
workflow.add_conditional_edges(
"Supervisor_Agent", lambda x: x[ "next" ], conditional_map
)
workflow.add_edge("Output_Summarizing_Agent", END)
workflow.add_edge(START, "Supervisor_Agent")
return workflow
The result is a graph.
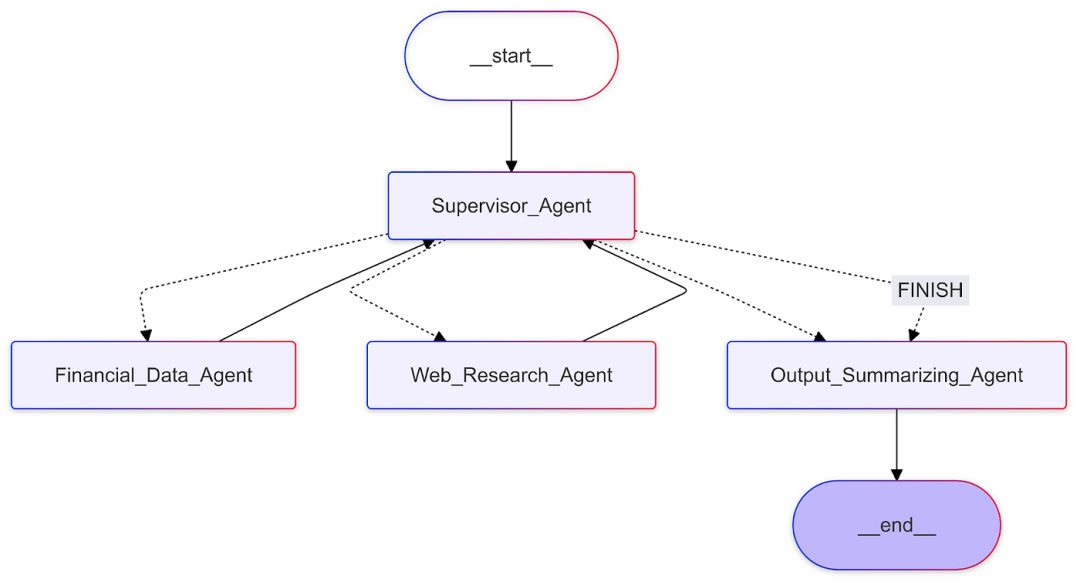
CrewAI
Compared to LangGraph, CrewAI abstracts away most orchestration tasks.
supervisor_agent = Agent(
role= "Financial Assistant Manager" ,
goal= "Leverage the skills of colleagues to answer user queries: {query}." ,
backstory= """You are a manager supervising the workflow of financial assistants, adept at overseeing complex employees with different skills and ensuring you can answer user queries with the help of colleagues. You always try to collect data first using the financial data agent and/or web scraping agent. After gathering the data, you must delegate to the output summarizing agent to create a comprehensive report instead of answering user queries directly.""" ,
verbose= True ,
llm=ChatOpenAI(model= "gpt-4o" ,temperature= 0.5 ),
allow_delegation= True ,
)
Similar to LangGraph, we first create a supervisor agent. Note that <span>allow_delegation</span> is a flag that allows the agent to pass tasks to other agents.
Next, we use Crew to integrate the agents together. Here, choosing to allow the supervisor agent to delegate tasks is very important. Behind the scenes, the supervisor agent receives user queries and translates them into tasks, then finds relevant agents to execute these tasks. If we want to create a more deterministic process where tasks are executed sequentially, another approach would be to not use a manager agent and execute directly.
finance_crew = Crew(
agents=[
financial_data_agent,
web_scraping_agent,
output_summarizing_agent
],
tasks=[
gather_financial_data,
gather_website_information,
summarize_findings
],
process=Process.hierarchical,
manager_agent=supervisor_agent,
)
OpenAI Swarm
Swarm orchestration uses a very simple strategy—switching. The core idea is to create a transfer function that uses another agent as a tool.
This is undoubtedly the most concise method. Relationships are implicit in the transfer function.
def transfer_to_summarizer():
return summarizing_agent
def transfer_to_web_researcher():
return web_researcher_agent
def transfer_to_financial_data_agent():
return financial_data_agent
supervisor_agent = Agent(
name= "Supervisor",
instructions= """You are a supervisor responsible for coordinating the financial data agent, web researcher agent, and output summarizing agent. Your tasks:
1. Given a user query, determine which agent to delegate the task to based on the user query
2. If the user query requires financial data, delegate to the financial data agent
3. If the user query requires web research, delegate to the web researcher agent
4. If enough information has been gathered to answer the user query, delegate to the output summarizing agent for the final output. Never summarize data yourself. Always delegate to the output summarizing agent for the final output. """,
functions=[ # agents as tools
transfer_to_financial_data_agent,
transfer_to_web_researcher,
transfer_to_summarizer
]
)
The downside of this method is that as applications grow, it becomes harder to track dependencies between agents.
3. Memory
Memory is an important component of stateful agent systems. We can distinguish two layers of memory:
- Short-term memory allows agents to maintain multi-turn/multi-step execution,
- Long-term memory allows agents to learn and remember preferences during a session.
This topic can be quite complex, but let’s look at the simplest memory orchestration in each framework.
LangGraph
LangGraph distinguishes between in-thread memory (memory within a single dialogue thread) and cross-thread memory (memory across dialogues).
To save in-thread memory, LangGraph provides the MemorySaver() class to save the state of the graph or dialogue history to a <span>checkpointer</span>.
from langgraph.checkpoint.memory import MemorySaver
def build_app():
"""Build and compile the workflow."""
memory = MemorySaver()
working = build_workflow()
return working.compile(checkpointer=memory)
To associate agent execution with memory threads, we pass a configuration with a <span>thread_id</span>. This tells the agent which thread’s memory checkpoint to use. For example:
config = { "configurable" : { "thread_id" : "1" }}
app = build_app()
await run(app, input, config)
To save cross-thread memory, LangGraph allows us to store memory in a JSON document store.
from langgraph.store.memory import InMemoryStore
store = InMemoryStore() # Can use DB-backed storage in production
user_id = "user_0"
store.put(
user_id,
"current_portfolio" ,
{
"portfolio" : [ "TSLA" , "AAPL" , "GOOG" ],
}
)
CrewAI
Not surprisingly, CrewAI takes a simpler but stricter approach. Developers simply set memory to true.
finance_crew = Crew(
agents=[financial_data_agent, web_researcher_agent, summarizing_agent],
tasks=[gather_financial_data, gather_website_information, summary_findings],
process=Process.hierarchical,
manager_agent=supervisor_agent,
memory=True , # Creates a memory database in the "CREWAI_STORAGE_DIR" folder
verbose=True , # Necessary for memory
)
It does very complex things behind the scenes as it creates several different memory stores:
- Short-term memory: It creates a ChromaDB vector store using OpenAI Embeddings to store agent execution history.
- Recent memory: SQLite3 db used to store recent task execution results.
- Long-term memory: SQLite3 db used to store task results, noting that task descriptions must match exactly (rather strict) to retrieve long-term memory.
- Entity memory: Extracts key entities and stores entity relationships in another ChromaDB vector store.
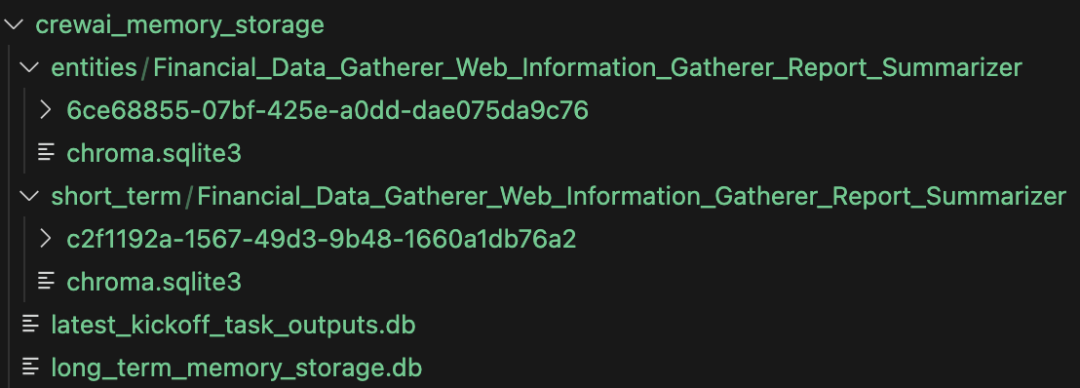
OpenAI Swarm
Swarm takes a simple stateless design with no built-in memory functions. A reference for how OpenAI views memory can be seen in its stateful Assistant API. Each conversation has a thread_id for short-term memory, and each assistant has an assistant_id that can be associated with long-term memory.
Third-party memory layer providers can also be integrated, such as mem0, or we can implement our own short-term and long-term memory.
4. Human-Machine Interaction
While we want agents to have autonomy, many agents are designed to interact with humans.
For example, customer support agents can ask users for information throughout the execution chain. Humans can also act as auditors or guides for a more seamless human-machine collaboration.
LangGraph
LangGraph allows us to set breakpoints in the graph, as shown below, if we want to add a human check before building the final output in the summarizer.
workflow.compile(checkpointer=checkpoint, interrupt_before=[ "Output_Summarizing_Agent" ])
Then the graph will execute until it reaches the breakpoint. We can then implement a step to get user input before continuing the graph.
# Run the graph until the first interrupt
for event in graph.stream(initial_input, thread, stream_mode="values"):
print(event)
try:
user_approval = input("Do you want to proceed to the output summarizer? (yes/no): ")
except:
user_approval = "yes"
if user_approval.lower() == "yes":
# If approved, continue the graph execution
for event in graph.stream(None, thread, stream_mode="values"):
print(event)
else:
print("User cancelled the operation.")
CrewAI
<span>human_input=True</span> CrewAI allows humans to provide feedback to the agent by setting the flag during agent initialization.

Then the agent will pause after execution and ask the user for natural language feedback about its actions and results (see below).
However, it does not support more customized human-machine interaction.
OpenAI Swarm
Swarm has no built-in human-machine interaction features. However, the simplest way to add human input during execution is to add humans as tools or agents to which the AI can transfer.
Summary of Feature Differences
To summarize our findings on building the same application across three frameworks.
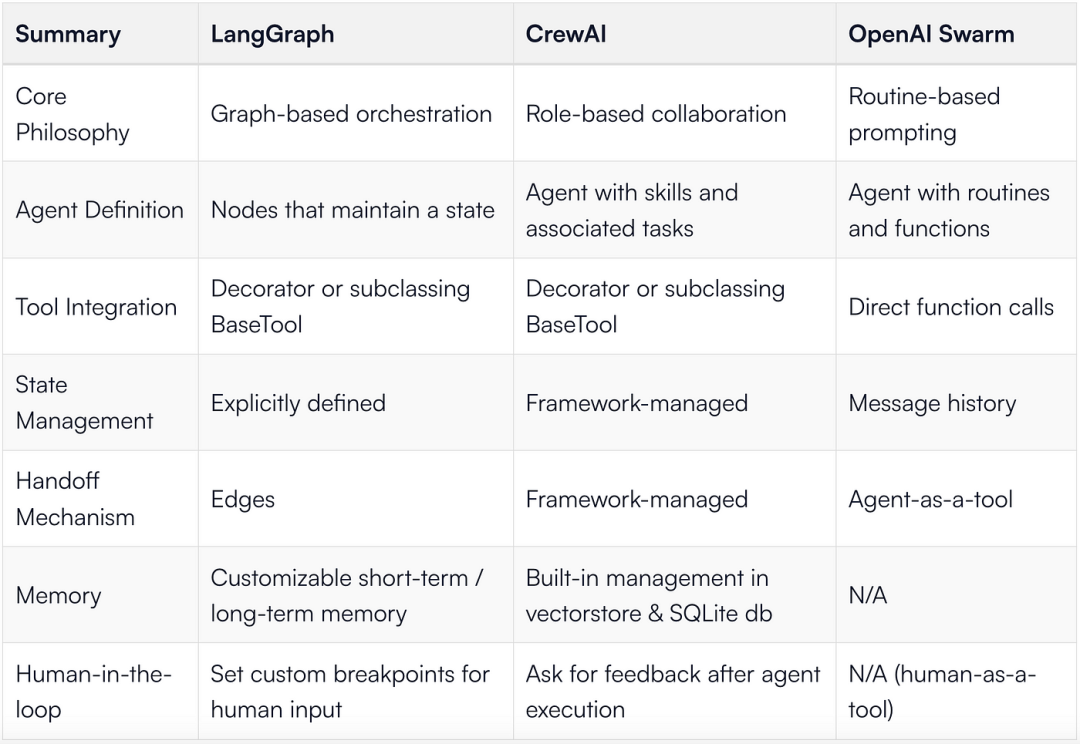
Our Recommendations
We summarize our recommendations in a flowchart to help you decide which framework to start with.
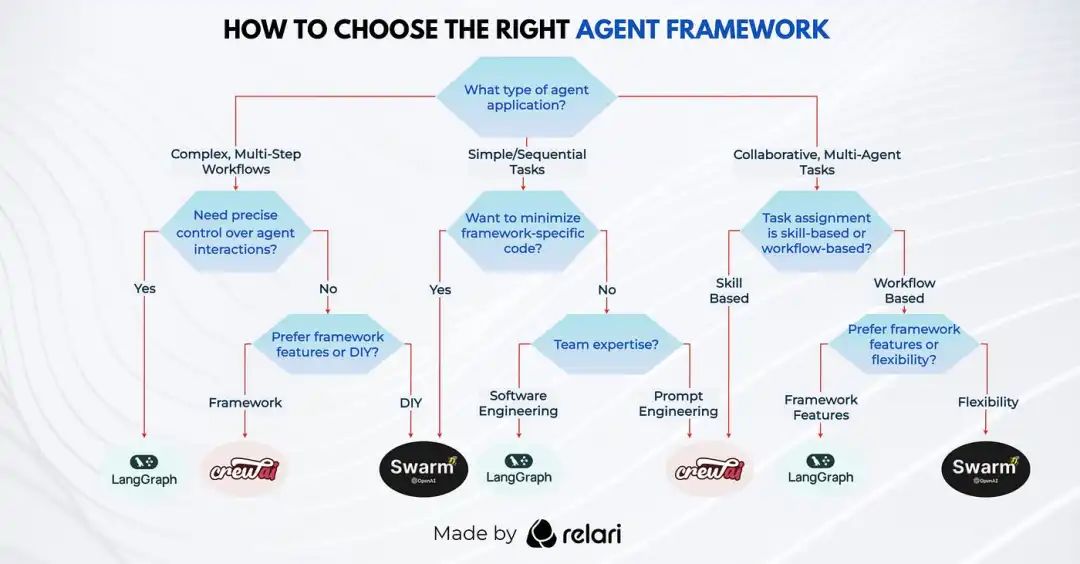
What’s Next?
This blog focuses on building the first version of agents. The performance and reliability of these agents are not very high.