“ This article introduces the application of a Generative Adversarial Network in the recommendation field, namely CFGAN, along with its principles, potential issues, and solutions, and provides a code implementation and examples of running on public datasets.”
Author Introduction: Zhang Xuxin, a master’s student at Huazhong University of Science and Technology, mainly researches data attack and defense as well as recommendation systems, and is a member of the ARASC community. Contact email: [email protected].
Introduction
The use of Generative Adversarial Networks for recommendations has been increasing in recent years. A recent review paper titled “Adversarial Machine Learning in Recommender Systems: State of the Art and Challenges” provides a detailed overview of adversarial machine learning in the field of recommendation systems and is worth reading! Here is the link to the paper: https://arxiv.org/pdf/2005.10322.pdf
CFGAN is an article published in CIKM2018 titled “CFGAN: A Generic Collaborative Filtering Framework based on Generative Adversarial Networks” (https://dl.acm.org/doi/pdf/10.1145/3269206.3271743)
Prior to this, the applications of GAN in recommendations mainly included IRGAN and GraphGAN. Below is a brief introduction to the main idea of IRGAN.
Main Idea of IRGAN
Consider that we have some sequential queries (when IRGAN is applied in recommendation systems, the query represents user profiles), and documents are some items related to the query (in recommendation systems, documents are information items). The relevance between the query and document is represented by r. We use conditional probability distributions to express the potential probability distributions between the true sequences and documents, given the conditional probability distributions observed from the training data, thus designing two models included in IRGAN:
- Generative Retrieval Model: The goal of this model is to learn how to generate or select relevant documents d from a given sequence q, making its distribution close to the true one.
- Discriminative Retrieval Model: The goal of this model is to learn fΦ(q,d), attempting to identify well-matched (q,d) from mismatched query-document pairs (q,d).
Next, referring to the idea of GAN, we combine these two models to perform a min-max game, where the generator tries to generate documents that are highly related to the sequence and similar to the true distribution to “fool” the discriminator; while the discriminator’s task is to accurately distinguish between real documents and those generated by the generator, iterating the model through continuous games to ultimately achieve the training goal. 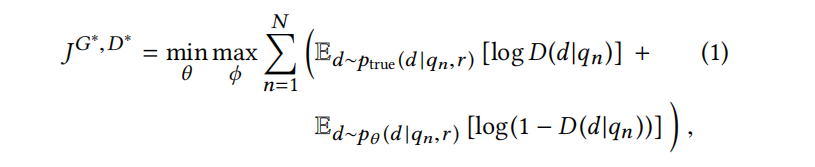 For the specific training process of IRGAN, please refer to the original paper.
For the specific training process of IRGAN, please refer to the original paper.
Issues with Discrete Item Index Generation
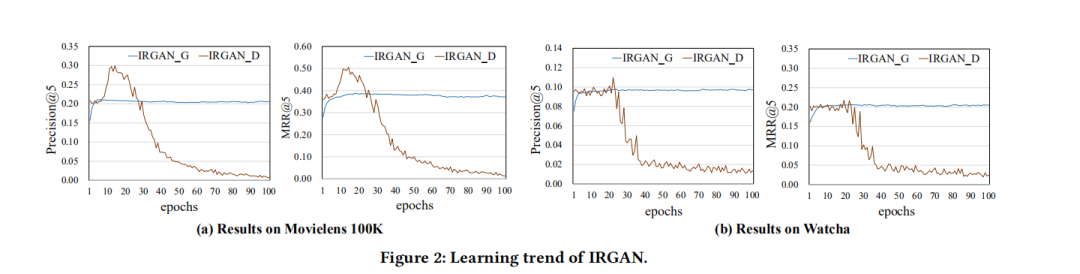
The problem with IRGAN is that during the training process, the generator gradually learns the true probability distribution (the process shown in the figure from a to b), thus generating item IDs that are the same as the real situation, but this confuses the discriminator. For example, in the figure below, i3 appears in both “real” and is labeled as real data, and also appears in “fake” and is labeled as generated data.  This conflicting judgment will cause problems in the iteration of the discriminator, leading to a decline in its performance. The CFGAN paper demonstrates this issue through experiments:
This conflicting judgment will cause problems in the iteration of the discriminator, leading to a decline in its performance. The CFGAN paper demonstrates this issue through experiments:  From the experimental results, it can be seen that the performance of the discriminator increases initially but then continuously declines to a poor result. The poor performance of the discriminator leads to a lack of “supervision” for the generator, thus the performance of the generator also fails to improve.
From the experimental results, it can be seen that the performance of the discriminator increases initially but then continuously declines to a poor result. The poor performance of the discriminator leads to a lack of “supervision” for the generator, thus the performance of the generator also fails to improve.
Essentially, the problem with IRGAN is that it generates discrete items. After considering this issue, CFGAN adjusts the generation of the G network to be a user’s rating vector, with values ranging from 0 to 1. For discrete items, overlaps are likely to occur, but for continuous rating vectors, the probability of overlap can be negligible (especially when the rating vector has a high dimension).
CFGAN
Let’s take a look at the structure of CFGAN: 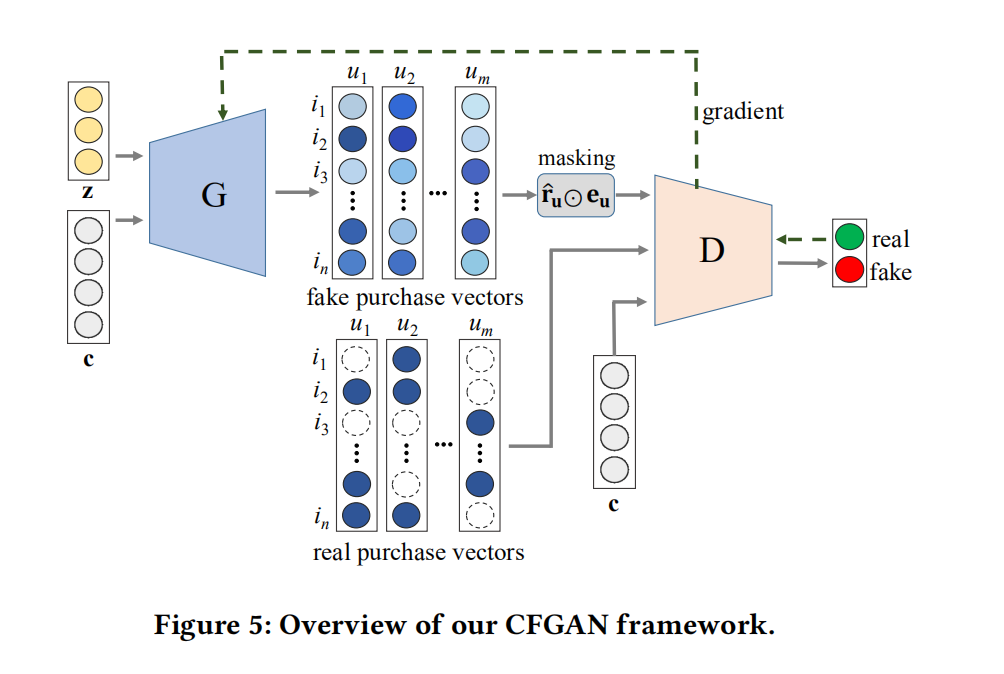
Generator G Network Structure
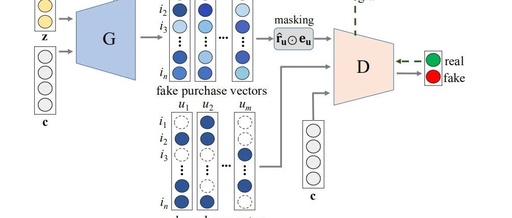
First, we focus on the design of the generator network: the original text mentions that the input of the generator G includes c, which describes user information, such as age, etc., but the original text uses a user’s purchase vector as the descriptive information c: _In our methods, we use a user’s (or, an item’s) purchase vector to specify a user (or, an item). [1]_ z in traditional GAN networks should represent noise, but the original text mentions that it follows the practices of IRGAN and GraphGAN, using the user’s purchase vector as z. _In addition, as in the other GAN-based CFs, we do not use the random noise variable z since our goal is to generate a single, most plausible recommendation result to a target user rather than multiple outcomes. [1]_ After passing through the generator network, c and z output the generated user purchase vector, where the values represent the probability of the user purchasing items. It is worth mentioning that the generated purchase vector undergoes a masking operation before being input into the generator network. The original explanation is to ensure that the generated vector has the same sparsity as the real vector, and through this operation, the network during training will only consider the generated values on the real purchased items.
class generator(nn.Module):
def __init__(self,itemCount,info_shape):
self.itemCount = itemCount
super(generator,self).__init__()
self.gen=nn.Sequential(
nn.Linear(self.itemCount+info_shape, 256),
nn.ReLU(True),
nn.Linear(256, 512),
nn.ReLU(True),
nn.Linear(512,1024),
nn.ReLU(True),
nn.Linear(1024, itemCount),
nn.Sigmoid()
)
def forward(self,noise,useInfo):
G_input = torch.cat([noise, useInfo], 1)
result=self.gen(G_input)
return result
The objective function of the generator G is given as: 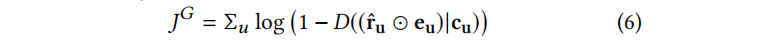 Next, let’s look at the design of the discriminator network: the input of the discriminator is the generated vector or the user’s real rating vector u after being masked with the real scored item vector (only 0/1), along with the user’s descriptive information vector c. The output is a probability value representing the likelihood that the input is a real rating vector.
Next, let’s look at the design of the discriminator network: the input of the discriminator is the generated vector or the user’s real rating vector u after being masked with the real scored item vector (only 0/1), along with the user’s descriptive information vector c. The output is a probability value representing the likelihood that the input is a real rating vector.
class discriminator(nn.Module):
def __init__(self,itemCount,info_shape):
super(discriminator,self).__init__()
self.dis=nn.Sequential(
nn.Linear(itemCount+info_shape,1024),
nn.ReLU(True),
nn.Linear(1024,128),
nn.ReLU(True),
nn.Linear(128,16),
nn.ReLU(True),
nn.Linear(16,1),
nn.Sigmoid()
)
def forward(self,data,condition):
data_c = torch.cat((data,condition),1)
result=self.dis( data_c )
return result
Discriminator D Network Structure
The objective function of the discriminator D is given as:
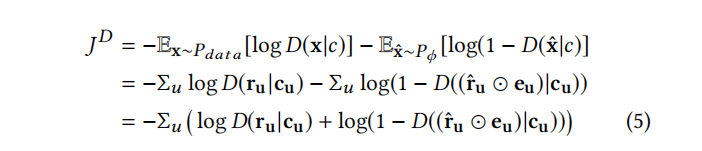
Potential Issues
Is there really no problem with the above network design? The answer is no. In fact, the generator can generate a vector of all 1s, and then through the masking operation, it will prevent the discriminator from making judgments because at this point, the generated vector represents the user interacting with these items with a probability of 1, which aligns with reality. Thus, the discriminator falls into a dilemma. Allowing the generator to produce a vector of all 1s is obviously meaningless. How can this issue be resolved? The original text provides the following steps.
In each iteration, a certain proportion of items that the user has not purchased are randomly selected, assuming they are negative sample items, meaning that the user does not want to purchase them, or has rated them but with a score of 0, rather than as missing values. Then, train the generator network G to ensure that the generated values on these negative sample items are close to 0. In this way, the generator is prevented from producing an output of all 1s.
Solutions
Based on this solution step, the paper presents three solutions: CFGAN_ZR, CFGAN_PM, and CFGAN_ZP. Among them, CFGAN_ZP is a combination of the first two solutions. Therefore, we will next explain the details of CFGAN_ZR and CFGAN_PM, and then provide the CFGAN_ZP solution.
-
CFGAN_ZR: This method obtains a certain proportion of negative sample items through negative sampling, and then adds a regularization term for these items, hoping that the predicted values on these negative samples are close to 0, thereby avoiding generating a vector of all 1s. At this point, the objective function of the generator G changes to the following form:
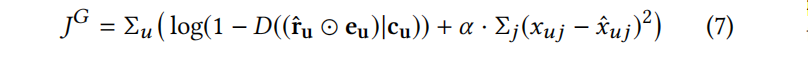 α is a parameter used to adjust the importance of negative sample items.
α is a parameter used to adjust the importance of negative sample items. -
CFGAN_PM: The change in this solution occurs after the generator network generates the vector, where we not only consider the generated values on the real purchased items, but also consider the generated values on some randomly selected negative sample items. The objective functions of the generator and discriminator at this point are:
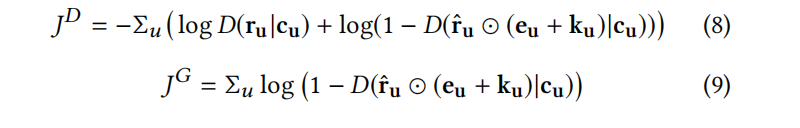 Comparing with the previous formulas, it is evident that a new n-dimensional indicator vector k has been added, where the corresponding values for negative sample items in k are 1, and others are 0.
Comparing with the previous formulas, it is evident that a new n-dimensional indicator vector k has been added, where the corresponding values for negative sample items in k are 1, and others are 0.
d_loss = -np.mean(np.log(realData_result.detach().numpy()+10e-5) +
np.log(1. - fakeData_result.detach().numpy()+10e-5))
- CFGAN_ZP: By integrating the above two solutions, the final objective function of the generator is as follows:
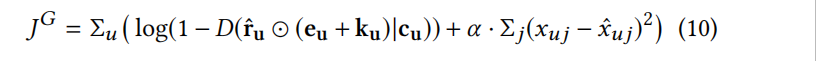
g_loss = np.mean(np.log(1.-fakeData_result.detach().numpy()+10e-5)) + alpha*regularization(fakeData_ZP,realData_zp)
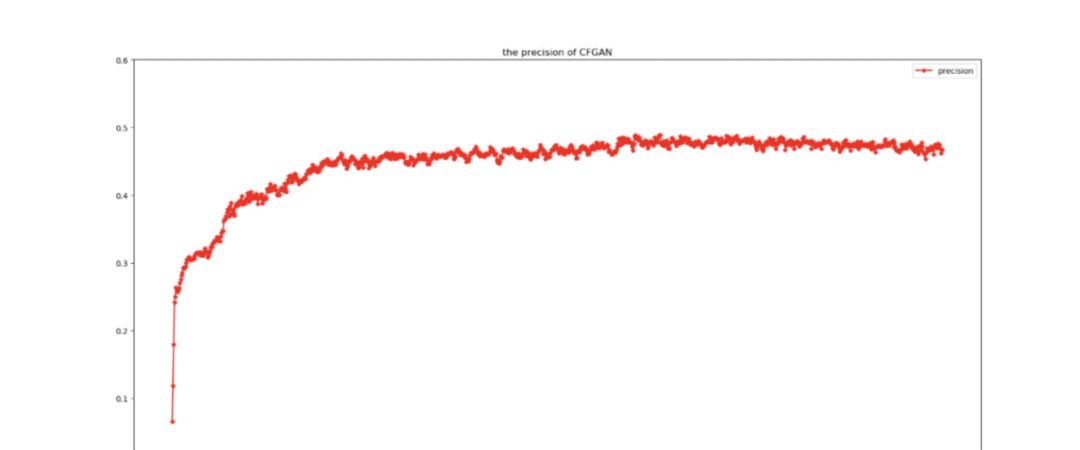
The objective function of the discriminator is consistent with that in the CFGAN_PM solution. The hyperparameters remain consistent with the original text, with a training duration of 1000, and the training dataset being Movielens 100K, with the final result P@5 reaching a maximum of 0.49. Screenshots of the run:
The results show:
- The complete code has been included in the ARASC community, https://github.com/ARASC/CFGAN, click on 【Read the original text】 at the end to access it.
- Reply with 【CFGAN】 in the public account to download the paper.
Recommended Reading
- Reproduction of SDM (Sequential Deep Matching Model)
- [Paper Notes] Alibaba DMR: A Deep Ranking Model Integrating Collaborative Filtering Ideas in Match
- [Stanford CS224W Graph and Machine Learning (1-2)]: Basic Introduction to Graph Models
- KDD19 DGL Tutorial: Recommender System with GNN
If you want to know more about recommendation systems, feel free to scan the QR code to follow our public accountQianmeng’s Learning Notes. Reply withJoin Group to join our exchange group and study together!

If you like it, please give it a thumbs up!👇