
This article mainly shares an open-source library for Python: Streamlit. Streamlit is a web application framework that allows us to visualize data and analyze results more efficiently and flexibly without needing to learn front-end and back-end development or set up Django. It helps data scientists and scholars quickly develop machine learning (ML) visualization dashboards in a short time. With just a few lines of code, we can build and deploy powerful data applications. Let’s get started.
1. Getting Started with Streamlit
1.1 Installation and Basic Usage of Streamlit
Prerequisite: python3.6+
pip install streamlitCreate a Python file (streamlit_hello.py) and import the Streamlit module.
import streamlit as st
st.set_page_config(page_title='Test', layout='wide')
st.write('hello')Then run the command in the terminal:
streamlit run streamlit_hello.pyOn the first run, you will be prompted to enter your email for binding, but you won’t need to do this afterward.
The command line will show:

This will automatically open the browser and webpage. If the link is blue, you can click it yourself. The webpage looks like this:
Now let’s do a simple practical example by implementing my web scraping code.
2. Initial Practice with Streamlit
Requirement: The webpage should include an introduction, PubMed literature scraping, and other functions accessible through sidebar selections.
Preparation: Python web scraping code and Streamlit-related libraries.
First, install the Streamlit menu component:
pip install streamlit_option_menuNow let’s start editing the webpage.
from PubmedArticle_s import article_spider as sp
import streamlit as st
from streamlit_option_menu import option_menu
import os
import time
# Define the webpage title
st.set_page_config(page_title='Achen Literature Scraping Website', layout='wide')
# Define sidebar navigation
with st.sidebar:
choose = option_menu('Achen's Website', ['Website Introduction', 'PubMed Literature Scraping', 'Other Website Scraping'], icons=['house', 'book-half', 'book-half'])You can access icons at: https://icons.bootcss.com/
Next, define the pages based on the different navigation options. First, define the introduction page.
if choose == 'Website Introduction':
# Define page title
st.title('Welcome to Achen's Scraping Website')
# Write text
st.write('This website is used to scrape related medical literature such as PubMed. Please use it strictly according to the instructions. If you have any questions, please contact Achen.')
st.write('All rights reserved by Achen's WeChat public account @Achen Blog')Now define the scraping webpage (showing only part of it):
elif choose == 'PubMed Literature Scraping':
# Define an input box
term1 = st.text_input('Please enter the search keyword:',)
# Instantiate the spider class
sp = sp()
# Ensure that the input box is not empty before executing the code, otherwise it will report an error
if len(term1) != 0:
term = sp.input_term(term1)
# Here we define a radio button, which defaults to the first option,
# The 'horizontal' parameter defaults to displaying options vertically; True means horizontal
year = st.radio(
'Please select the filtering year; if not selected, defaults to the last 5 years',
('None', '1 year', '5 years', '10 years'), horizontal=True
)
if year == '1 year' and len(term1) != 0:
year = '1'
term = sp.input_term(term1)
results1 = sp.send_request(term, year)[0]
soup = sp.send_request(term, year)[1]
total_page = int(sp.page_total(soup))
st.write(f'There are a total of {total_page} pages of query results.')
if total_page > 1:
want_page = int(st.text_input('Please enter the number of pages you want to scrape +1:'))
time.sleep(5)
cost = want_page / 5
st.write(f'The estimated time for this scraping is {cost} minutes.')
st.write('Scraping literature, please wait patiently...')
if total_page >= want_page - 1:
results2 = sp.next_page(term, want_page, year)
results = results1 + results2
results_list = sp.get_data(results)
st.write('Writing to file...')
sp.write_data(results_list)
st.write('Scraping successful, click the button to open the file.')
# Define a button to open the file
if st.button('Open File'):
# Use OS to call system commands, which is equivalent to entering commands in the terminal
os.system(r'D:/PythonProject/StreamlitArticle/article.csv')
else:
st.write('The entered page number is too large, please re-enter.')
else:
results = results1
results_list = sp.get_data(results)
st.write('Writing to file...')
sp.write_data(results_list)
st.write('Scraping successful, click the button to open the file.')
if st.button('Open File'):
os.system(r'D:/PythonProject/StreamlitArticle/article.csv')Next, let's take a look at the actual effect:
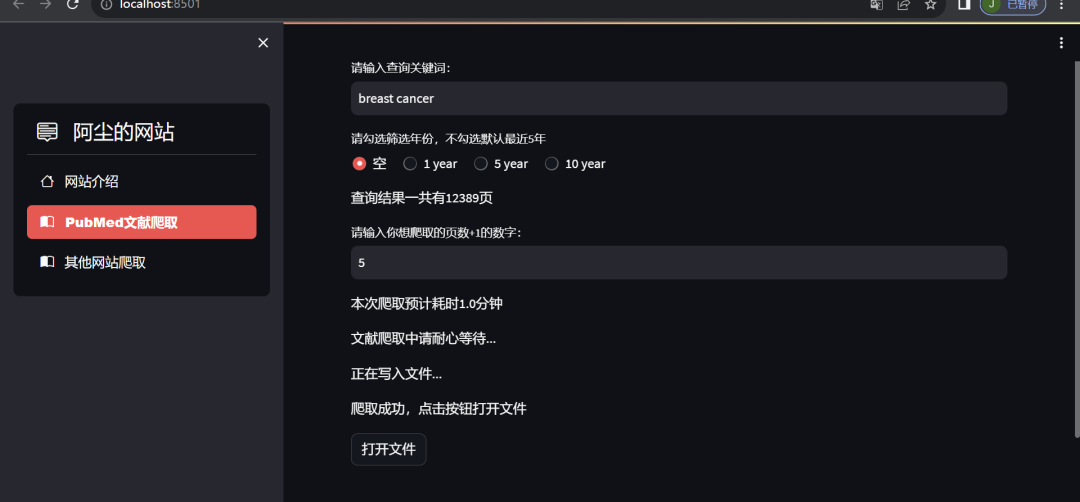
OK, isn’t it simple and cool? In fact, this only scratches the surface. The official website has many APIs that can display data analysis graphs and other functionalities, including font styles, input box restrictions, etc., which can be customized in detail. Overall, it’s simple, powerful, and easy to get started. Due to time constraints, I will stop sharing here. If you’re interested, feel free to explore the official documentation.
Official documentation address:
Chinese: http://cw.hubwiz.com/card/c/streamlit-manual/
English: https://docs.streamlit.io/
Scan the QR code to follow Achen Blog and learn together.
