In this tutorial, we will delve into how to build an intelligent Q&A system with conditional branching using the langgraph framework. We will analyze the code step by step, understand the functionality of each part, and explain the principles behind it. The ultimate goal is to enable you to create an AI assistant that can extract information from web documents and decide whether to use the extracted information to answer user questions.
1. Import Required Libraries
First, we need to import some necessary libraries and modules. These libraries will help us handle web data, perform text splitting, embedding, and retrieval operations.
import bs4
from langchain import hub
from langchain_community.document_loaders import WebBaseLoader
from langchain_core.documents import Document
from langchain_text_splitters import RecursiveCharacterTextSplitter
from typing_extensions import List, TypedDict
from langchain_openai import ChatOpenAI
from langchain_openai import OpenAIEmbeddings
from langchain_core.vectorstores import InMemoryVectorStore
from langgraph.graph import MessagesState, StateGraph
from langchain_core.tools import tool
from langchain_core.messages import SystemMessage
from langgraph.graph import END
from langgraph.prebuilt import ToolNode, tools_condition
from langgraph.checkpoint.memory import MemorySaver2. Initialize Language Model
Next, we will initialize a chat model, here we are using OpenAI’s GPT-4o model.<span>temperature=0</span>: Setting the temperature to 0 means the model will generate more deterministic answers rather than random ones.
# Large model
llm = ChatOpenAI(model="gpt-4o", temperature=0)3. Load Web Document
We use <span>WebBaseLoader</span> to load documents from a specified URL and only parse list items (<span>li</span> tags).
# Document loading
loader = WebBaseLoader(
web_paths=("https://github.com/jobbole/awesome-python-cn/blob/master/README.md",),
bs_kwargs=dict(
parse_only=bs4.SoupStrainer("li")
),
)
docs = loader.load()4. Document Splitting
After loading the document, we need to split it into smaller parts for processing and embedding.
# Document splitting
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
all_splits = text_splitter.split_documents(docs)5. Document Embedding Storage
Next, we will generate embeddings for the split documents and store them in the in-memory vector store.
# Document embedding storage
embeddings = OpenAIEmbeddings(model="text-embedding-3-large")
vector_store = InMemoryVectorStore(embeddings)
_ = vector_store.add_documents(documents=all_splits)6. Create Retrieval Tool
We will create a tool to retrieve similar documents based on user queries.
@tool(response_format="content_and_artifact")
def retrieve(query: str):
"""
Transform the retrieval step into a tool
"""
retrieved_docs = vector_store.similarity_search(query, k=2)
serialized = "\n\n".join(
(f"Source: {doc.metadata}\n" f"Content: {doc.page_content}")
for doc in retrieved_docs
)
return serialized, retrieved_docs
tools = ToolNode([retrieve])-
• <span>retrieve</span>function: Receives a query and returns similar documents. -
• <span>similarity_search</span>: Searches for the most similar documents in the vector store based on the query.
7. Handle User Queries
We define a function to handle user queries and generate responses.
# Generate AIMessage that may contain tool calls
def query_or_respond(state: MessagesState):
llm_with_tools = llm.bind_tools([retrieve])
response = llm_with_tools.invoke(state["messages"])
return {"messages": [response]}-
• <span>query_or_respond</span>: The language model binds the retrieval tool, allowing it to decide whether to use the retrieval tool as needed. The response may contain two types of content: a regular text response or a tool call request, which serves as the basis for subsequent conditional branching decisions.
8. Generate Final Response
Next, we will generate the final answer.
# Generate reply using retrieved content
def generate(state: MessagesState):
"""Generate an answer"""
recent_tool_messages = []
for message in reversed(state["messages"]):
if message.type == "tool":
recent_tool_messages.append(message)
else:
break
tool_messages = recent_tool_messages[::-1]
docs_content = "\n\n".join(doc.content for doc in tool_messages)
system_message_content = (
"You are an assistant for question-answering tasks. "
"Use the following pieces of retrieved context to answer "
"the question. If you don't know the answer, say that you "
"don't know. Use three sentences maximum and keep the "
"answer concise."
"\n\n"
f"{docs_content}"
)
conversation_messages = [
message
for message in state["messages"]
if message.type in ("human", "system")
or (message.type == "ai" and not message.tool_calls)
]
prompt = [SystemMessage(system_message_content)] + conversation_messages
response = llm.invoke(prompt)
return {"messages": [response]}-
• <span>generate</span>function: The main task of this function is to generate answers from the retrieved documents. It first retrieves the most recent tool messages and formats them into a prompt suitable for the language model. -
• Retrieve Tool Messages: By traversing <span>state["messages"]</span>in reverse order, we can find the most recent tool messages, which contain contextual information related to the user query. The retrieved tool messages are then reversed to ensure they are processed in the correct order. -
• Concatenate Document Content: Using <span>docs_content</span>, we concatenate the content of all tool messages to form a complete context for the language model to use. -
• Build System Message: <span>system_message_content</span>instructs the model on its role and how to answer questions, emphasizing conciseness and accuracy while incorporating the retrieved document content. -
• Extract Conversation Messages: <span>conversation_messages</span>extracts human and system messages from the message state for use in generating the final response. -
• Generate Prompt: The final prompt <span>prompt</span>combines the system message and conversation messages as input to the language model. -
• Generate Response: Calls the language model to generate a response, which is ultimately returned to the caller.
9. Build State Graph
We use <span>StateGraph</span> to manage the state of the entire process.
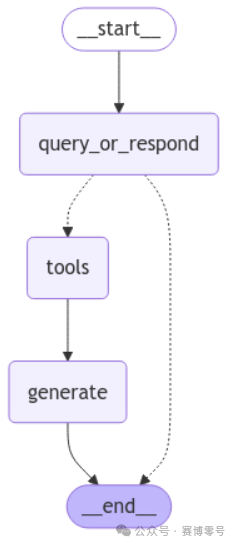
# Graph definition
graph_builder = StateGraph(MessagesState)
graph_builder.add_node(query_or_respond)
graph_builder.add_node(tools)
graph_builder.add_node(generate)
graph_builder.set_entry_point("query_or_respond")
graph_builder.add_conditional_edges(
"query_or_respond",
tools_condition,
{END: END, "tools": "tools"},
)
graph_builder.add_edge("tools", "generate")
graph_builder.add_edge("generate", END)
memory = MemorySaver()
graph = graph_builder.compile(checkpointer=memory)-
• <span>StateGraph</span>: This is a structure used to define and manage state transitions. It allows us to organize different processing steps into a graphical structure, enabling flexible state transitions during user input processing. -
• Add Nodes: Using the <span>add_node</span>method, we can add different processing steps (such as<span>query_or_respond</span>,<span>tools</span>, and<span>generate</span>) to the state graph. These nodes represent different stages in the system’s processing of user requests. -
• Set Entry Point: The <span>set_entry_point</span>method is used to specify the starting node of the state graph. Here, we set the entry point to<span>query_or_respond</span>, meaning the system will start by processing user queries. -
• Add Conditional Edges: The <span>add_conditional_edges</span>method defines state transitions under specific conditions. In this case, we decide whether to continue to the<span>tools</span>node or end the process based on the results of tool calls. -
• Add Edges: Using the <span>add_edge</span>method, we can define the connection relationships between nodes, ensuring a smooth transition from one step to the next during the processing flow. -
• Memory Saving: <span>MemorySaver</span>is used to save the current state in the state graph for recovery when needed. This is crucial for long-running conversations or multi-turn interactions. -
• Compile Graph: Finally, through the <span>compile</span>method, we compile the state graph into an executable form for use in subsequent user interactions.
10. Stream User Input
Finally, we can stream user input and generate responses.
# For messages that do not require additional retrieval steps, it will respond appropriately
input_message = "Hello"
for step in graph.stream(
{"messages": [{"role": "user", "content": input_message}]},
stream_mode="values",
config=config,
):
step["messages"][-1].pretty_print()
# When performing a search, we can stream steps to observe query generation, retrieval, and answer generation:
input_message = "What is Maya?"
for step in graph.stream(
{"messages": [{"role": "user", "content": input_message}]},
stream_mode="values",
config=config,
):
step["messages"][-1].pretty_print()Response Content:
================================ Human Message =================================
Hello
================================== Ai Message ==================================
Hi there! How can I assist you today?
================================ Human Message =================================
What is Maya?
================================== Ai Message ==================================
Tool Calls:
retrieve (chatcmpl-Jcknfda608GbybspWw9fe51T0VPGl)
Call ID: chatcmpl-Jcknfda608GbybspWw9fe51T0VPGl
Args:
query: What is Maya?
================================= Tool Message =================================
Name: retrieve
Source: {'source': 'https://github.com/jobbole/awesome-python-cn/blob/master/README.md'}
Content: Python itself. pyarmor: a tool for encrypting Python scripts that can also bind the encrypted scripts to firmware, or set an expiration date for the encrypted scripts. shiv: a command-line tool for building completely standalone zip applications (as described in PEP 441), including all dependencies. buildout: a build system for creating, assembling, and deploying applications from multiple components. BitBake: a make-like build tool for embedded Linux. fabricate: a build tool that automatically finds dependencies for any language. PlatformIO: a multi-platform command-line build tool. PyBuilder: a continuous build tool implemented in pure Python. SCons: a software build tool. IPython: a feature-rich tool that effectively uses interactive Python. bpython: an interface-rich Python interpreter. ptpython: an advanced interactive Python interpreter built on top of python-prompt-toolkit. Jupyter Notebook (IPython): a rich toolkit that allows you to use Python interactively to the fullest.
Source: {'source': 'https://github.com/jobbole/awesome-python-cn/blob/master/README.md'}
Content: Club: an unsupervised machine learning toolbox for graph-structured data. NIPY: a collection of neuroimaging tools. ObsPy: a Python toolbox for seismology. QuTiP: a Python version of the Quantum toolbox. SimPy: a process-based discrete-event simulation framework. matplotlib: a 2D plotting library for Python. bokeh: interactive web plotting with Python. ggplot: a Python version of the ggplot2 API for R. plotly: a web plotting library that works collaboratively with Python and matplotlib. pyecharts: a data visualization library based on Baidu Echarts. pygal: a Python SVG chart creation tool. pygraphviz: a Python interface for Graphviz. PyQtGraph: interactive real-time 2D/3D/image plotting and scientific/engineering components. SnakeViz: a browser-based tool for viewing Python's cProfile module output. vincent: a tool for converting Python into Vega syntax. VisPy: a high-performance scientific visualization tool based on OpenGL. Altair: a declarative statistical visualization library for Python. bqplot: an interactive plotting library for Jupyter Notebook. Cartopy: a Python library for cartographic projections with matplotlib support. Dash: built on Flask, React, and Plotly, designed for analytical web applications.
================================== Ai Message ==================================
Maya is a Python library that simplifies date and time handling, providing a simple interface for parsing, formatting, and manipulating date and time data. If you are interested in date and time operations in Python, Maya can be very helpful.11. Summary
In this tutorial, we detailed how to build an intelligent Q&A system using langgraph. We started with loading web documents, followed by text splitting, embedding storage, tool creation, user query processing, and finally generating responses. In this way, you can create an AI assistant that can extract information from web documents and decide whether to use the extracted information to answer user questions.
12. Complete Code
import bs4
from langchain import hub
from langchain_community.document_loaders import WebBaseLoader
from langchain_core.documents import Document
from langchain_text_splitters import RecursiveCharacterTextSplitter
from typing_extensions import List, TypedDict
from langchain_openai import ChatOpenAI
from langchain_openai import OpenAIEmbeddings
from langchain_core.vectorstores import InMemoryVectorStore
from langgraph.graph import MessagesState, StateGraph
from langchain_core.tools import tool
from langchain_core.messages import SystemMessage
from langgraph.graph import END
from langgraph.prebuilt import ToolNode, tools_condition
from langgraph.checkpoint.memory import MemorySaver
# Large model
llm = ChatOpenAI(model="gpt-4o", temperature=0)
# Load web document
loader = WebBaseLoader(
web_paths=("https://github.com/jobbole/awesome-python-cn/blob/master/README.md",),
bs_kwargs=dict(
parse_only=bs4.SoupStrainer("li")
),
)
docs = loader.load()
# Document splitting
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
all_splits = text_splitter.split_documents(docs)
# Document embedding storage
embeddings = OpenAIEmbeddings(model="text-embedding-3-large")
vector_store = InMemoryVectorStore(embeddings)
_ = vector_store.add_documents(documents=all_splits)
# Transform the retrieval step into a tool
@tool(response_format="content_and_artifact")
def retrieve(query: str):
"""
Transform the retrieval step into a tool
"""
retrieved_docs = vector_store.similarity_search(query, k=2)
serialized = "\n\n".join(
(f"Source: {doc.metadata}\n" f"Content: {doc.page_content}")
for doc in retrieved_docs
)
return serialized, retrieved_docs
tools = ToolNode([retrieve])
# Generate AIMessage that may contain tool calls
def query_or_respond(state: MessagesState):
llm_with_tools = llm.bind_tools([retrieve])
response = llm_with_tools.invoke(state["messages"])
return {"messages": [response]}
# Generate reply using retrieved content
def generate(state: MessagesState):
"""Generate an answer"""
recent_tool_messages = []
for message in reversed(state["messages"]):
if message.type == "tool":
recent_tool_messages.append(message)
else:
break
tool_messages = recent_tool_messages[::-1]
docs_content = "\n\n".join(doc.content for doc in tool_messages)
system_message_content = (
"You are an assistant for question-answering tasks. "
"Use the following pieces of retrieved context to answer "
"the question. If you don't know the answer, say that you "
"don't know. Use three sentences maximum and keep the "
"answer concise."
"\n\n"
f"{docs_content}"
)
conversation_messages = [
message
for message in state["messages"]
if message.type in ("human", "system")
or (message.type == "ai" and not message.tool_calls)
]
prompt = [SystemMessage(system_message_content)] + conversation_messages
response = llm.invoke(prompt)
return {"messages": [response]}
# Graph definition
graph_builder = StateGraph(MessagesState)
graph_builder.add_node(query_or_respond)
graph_builder.add_node(tools)
graph_builder.add_node(generate)
graph_builder.set_entry_point("query_or_respond")
graph_builder.add_conditional_edges(
"query_or_respond",
tools_condition,
{END: END, "tools": "tools"},
)
graph_builder.add_edge("tools", "generate")
graph_builder.add_edge("generate", END)
memory = MemorySaver()
graph = graph_builder.compile(checkpointer=memory)
config = {"configurable": {"thread_id": "abc123"}}
# For messages that do not require additional retrieval steps, it will respond appropriately
input_message = "Hello"
for step in graph.stream(
{"messages": [{"role": "user", "content": input_message}]},
stream_mode="values",
config=config,
):
step["messages"][-1].pretty_print()
# When performing a search, we can stream steps to observe query generation, retrieval, and answer generation:
input_message = "What is Maya?"
for step in graph.stream(
{"messages": [{"role": "user", "content": input_message}]},
stream_mode="values",
config=config,
):
step["messages"][-1].pretty_print()
Recommended Reading
-
FastAPI Getting Started Series
-
Django Getting Started Series
-
Flask Tutorial Series
-
tkinter Tutorial Series
-
Flet Tutorial Series
Open in WeChat client