
For beginners in machine learning, the most daunting aspects are the various formulas, concepts, and derivations.
Faced with heavy textbooks and complex concepts, one often doesn’t know where to start. I used to struggle with the “Watermelon Book,” and when I saw examples like using watermelon vines to pick watermelons or judging the weather based on air humidity, my progress would always stall at
“Hmm, tomorrow will definitely be a nice day”… …

Now that intelligent agent technology can embed professional knowledge into an agent team, why not create a machine learning assistant?
First, let’s design the composition of this private mentor team made up of AI experts:
📚 Machine Learning Researcher: Proficient in various machine learning concepts, able to accurately pinpoint the knowledge points you need
🔍 Technical Expert: Translates complex concepts into clear explanations, providing practical code examples
✅ Validation Expert: Ensures all advice is rigorously validated and aligns with industry best practices
📝 Documentation Expert: Converts professional knowledge into easy-to-understand learning materials
In the design, I considered that this mentor team must be professional and provide precise answers to machine learning questions: based on authoritative materials like Andrew Ng’s “Machine Learning Yearning”.

Secondly, machine learning places great importance on practical application, so it must be a team that can guide users through systematic learning. From concept understanding to code implementation, it needs to cover all aspects.
Therefore, this is a practical-oriented team, not just theoretical, but more focused on practical applications.
Of course, technology changes rapidly, and they must continuously update their knowledge through online searches to maintain relevance.
First, let’s take a look at the results:
input:
Error analysis on the training set #训练集误差分析
This is the guidance provided to me by the expert team:
- 1. Technical explanation of machine learning concepts
- **Training Set Error Analysis (Error Analysis on the Training Set)** is a crucial step in the development of machine learning models, especially when model performance is poor.
- The main purpose of training set error analysis is to identify performance issues of the model on the training data, particularly high bias issues.
- High bias usually means that the model cannot fit the training data well, leading to high training error. By analyzing the error samples in the training set, one can identify specific categories or scenarios where the model performs poorly. For example, in a speech recognition system, it may be found that the model performs poorly when processing audio with significant background noise. Through this analysis, targeted improvements can be made to the model, such as enhancing its ability to handle background noise.
- 2. Practical implementation guidance
- Step 1: Collect and analyze error samples Randomly select 100-200 poorly performing samples from the training set. Conduct manual analysis of these samples to identify the main error categories. For instance, in speech recognition, error categories may include “background noise,” “user speech unclear,” etc.
- Step 2: Count error categories Conduct statistics on each error category to calculate its proportion in the total errors. Based on the statistical results, determine which error categories have the most significant impact on model performance.
- Step 3: Targeted improvements to the model Based on the error analysis results, adjust the model structure or training strategy. For example, if background noise is a primary issue, data augmentation techniques can be added to simulate more background noise scenarios. Retrain the model and conduct error analysis again until the model’s performance on the training set meets expectations.
- 3. Related code examples Below is a simple Python code example demonstrating how to conduct training set error analysis:
- import numpy as np from sklearn.metrics import accuracy_score, classification_report, confusion_matrix # Assuming we have a model and training data model = … # Your model X_train = … # Training data features y_train = … # Training data labels # Predict training set y_pred = model.predict(X_train) # Calculate training set error train_error = 1 – accuracy_score(y_train, y_pred) print(f”Training Error: {train_error:.4f}”) # Identify incorrectly predicted samples error_indices = np.where(y_pred != y_train)[0] error_samples = X_train[error_indices] error_labels = y_train[error_indices] # Analyze error samples for i, sample in enumerate(error_samples[:100]): # Analyze the first 100 error samples print(f”Sample {i}: Predicted {y_pred[error_indices[i]]}, Actual {error_labels[i]}”) # Here, further analysis of sample features can be conducted, such as audio features in speech recognition # Use confusion matrix and classification report for detailed analysis conf_matrix = confusion_matrix(y_train, y_pred) print(“Confusion Matrix:”) print(conf_matrix) class_report = classification_report(y_train, y_pred) print(“Classification Report:”) print(class_report)
- 4. Framework-specific considerations TensorFlow/Keras When using Keras for training, the training set error can be directly calculated using the model.evaluate() method. Additionally, Keras provides callback functions that can monitor training errors in real-time during training. # Keras Example train_loss, train_acc = model.evaluate(X_train, y_train, verbose=0) print(f”Training Accuracy: {train_acc:.4f}”) PyTorch In PyTorch, the training set error can be calculated through a custom training loop. The torch.no_grad() context manager can be used to avoid updating model parameters while calculating the error. # PyTorch Example model.eval() with torch.no_grad(): outputs = model(X_train) _, predicted = torch.max(outputs, 1) train_acc = (predicted == y_train).sum().item() / y_train.size(0) print(f”Training Accuracy: {train_acc:.4f}”) Scikit-learn Scikit-learn provides various evaluation metrics (such as accuracy_score, confusion_matrix etc.), making error analysis convenient.
- 5. Performance and optimization recommendations Data augmentation If the model performs poorly in certain specific scenarios, data augmentation techniques can be employed to generate more relevant training data. For example, in image classification tasks, data can be augmented through rotation, scaling, adding noise, etc. Model complexity adjustment If the model performs poorly on the training set, it may indicate insufficient model complexity. Consider increasing the number of layers or neurons in the model to enhance its fitting ability. Regularization If the model performs well on the training set but poorly on the development set, it may indicate overfitting. Consider adding regularization terms (such as L2 regularization) to reduce overfitting. Learning rate adjustment An excessively high or low learning rate can affect the model’s training effectiveness. Learning rate schedulers can be used to dynamically adjust the learning rate to improve the convergence speed and performance of the model.
- 6. Common issues and solutions Issue 1: Model performs poorly on the training set Solution: Increase model complexity, adjust learning rate, or use data augmentation techniques. Issue 2: Model performs well on the training set but poorly on the development set Solution: Add regularization terms or use cross-validation to evaluate model performance. Issue 3: Error sample analysis is time-consuming Solution: Use batch processing and parallel computing to speed up error sample analysis.
- 7. References for official documentation and research papers Scikit-learn official documentation: [https://scikitlearn.com.cn/]
How is this achieved?
This must mention the complete structure of a RAG system.
It includes several independent working modules: Knowledge Base (Document Vectorization), Retrieval System, and Large Model Q&A System.
Below is a component relationship diagram.
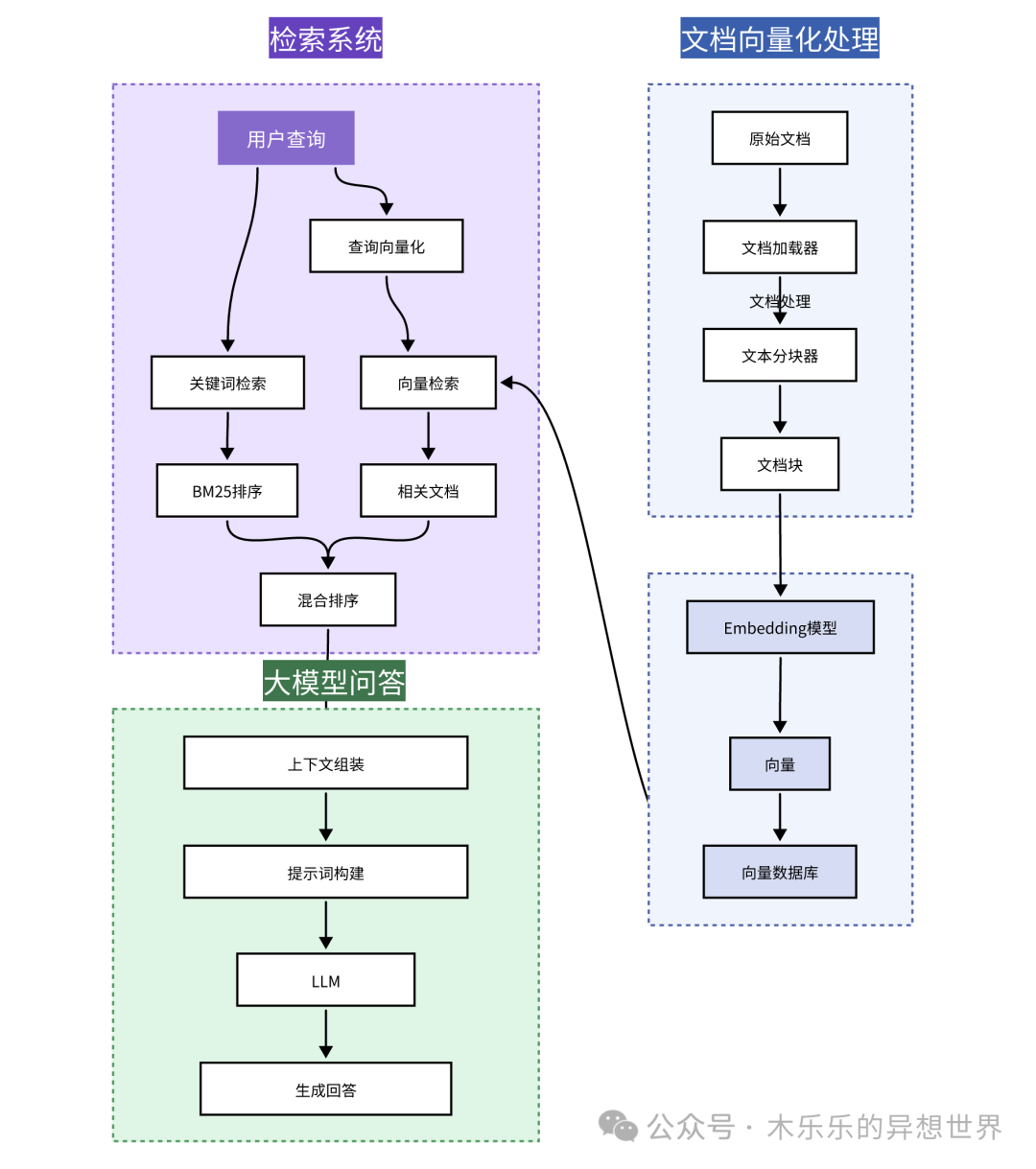
Among them, the most important is: Document Vectorization part.
Why is this the most important? It ultimately affects whether the content in the knowledge base can be accurately queried. Because the subsequent accuracy of the large model’s Q&A depends on whether the knowledge is included in the retrieval results.
There are two very important roles: Embedding Model and Vector Database.
The explanation and application of the Embedding Model can refer to this article:https://mp.weixin.qq.com/s/-l0IWSP_FvLfOmYQgX6bCA
Meanwhile, the Vector Database plays an important role in modern AI applications, especially in scenarios that require processing and retrieving large amounts of text data.
It provides strong infrastructure support for intelligent Q&A systems, search engines, and knowledge bases.
Let’s take a brief look at the vectorization process:
Documents first undergo chunk processing, and after chunking is complete, they will be vectorized using the embedding model, and the processed data will be stored in the vector database.
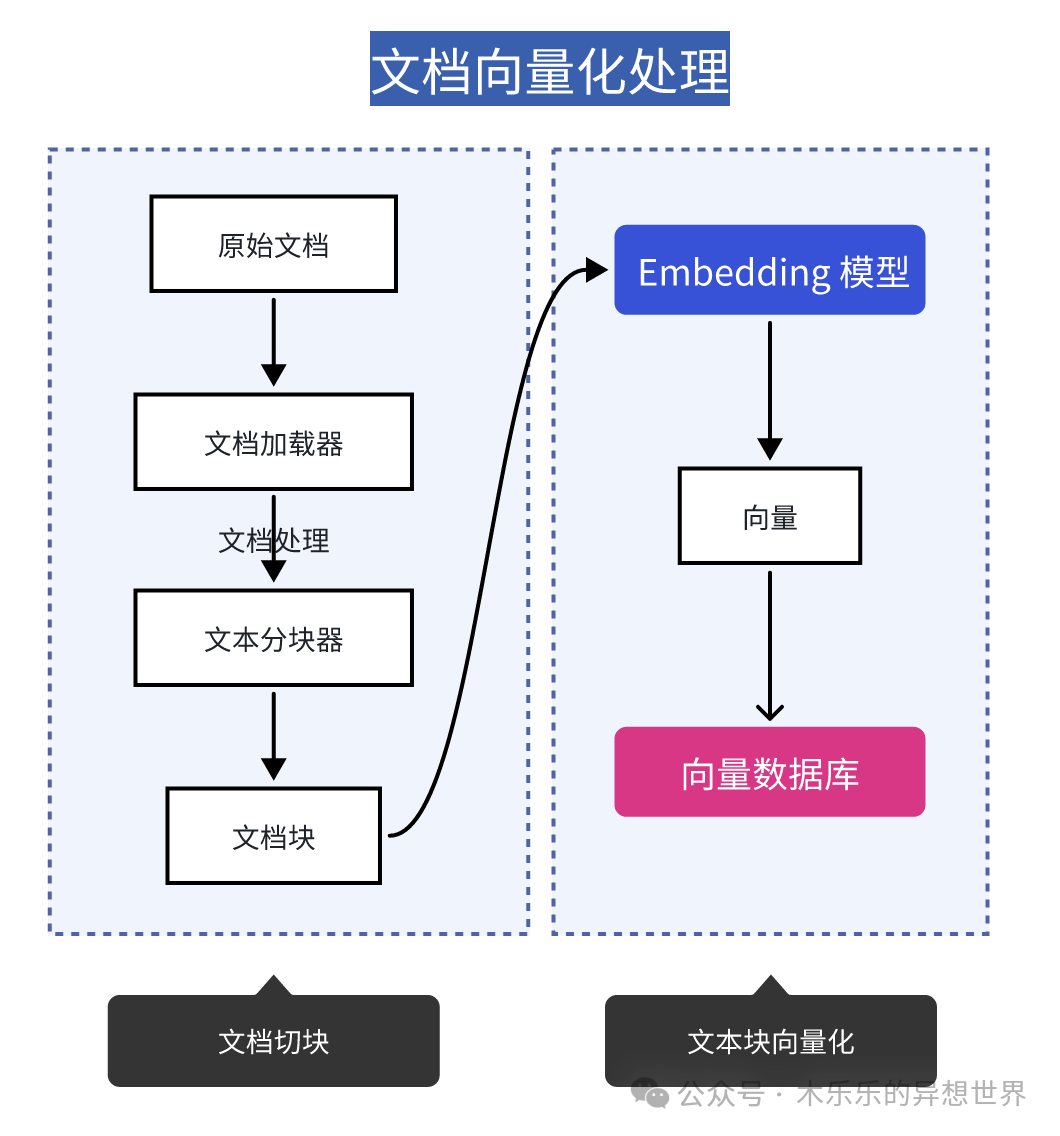
Once vectorization is mentioned, we can’t avoid discussing vector dimensions.
What are vector dimensions?
Vector dimensions are a way to represent text features with numbers. Just like describing an object using different numbers of features:
A 2D object, such as a rectangle, is described using length and width.
A 3D object, such as a cuboid, is described using length, width, and height.
The more dimensions, the more adequately the object is described. For text, 2D and 3D are clearly insufficient.
Embedding Model Dimensions
Currently, different embedding models use varying numbers of features to understand text.
The vector dimensions of text have two mainstream modes: one is 768 dimensions, and the other is 1536 dimensions.
768 dimensions: Commonly found in HuggingFace’s embedding models (like BERT), 1536 dimensions: Used by OpenAI’s embedding models.
Vector Database Dimensions
These dimensions will affect the final selection of the database for storing vector data. When the embedding model dimension used for vectorization does not match the vector database dimension, these two components cannot be compatible. It’s like trying to match data measured in meters with data measured in yards; the system cannot compare vectors of different dimensions, leading to failed information retrieval.
Matching Vector Dimensions
How to achieve vector dimension matching? It’s simple: during text vectorization and vector storage, choose the same embedding model.
For example, in the local deployment of the Ollama nomic-embed-text model and Chroma vector database that I am currently using, let’s take a look at how to achieve dimension adaptation step by step.
1- Initialize Ollama embeddings settings
import os
from crewai import Agent, Task, Crew, Process
from crewai.tools import tool
from langchain_chroma import Chroma
from langchain_openai import ChatOpenAI
from dotenv import load_dotenv # Add this line to import environment variables
from langchain_ollama import OllamaEmbeddings
from langchain_community.document_loaders import PyPDFLoader
from langchain_ollama import OllamaEmbeddings
from langchain.text_splitter import RecursiveCharacterTextSplitter
# 1. Initialize Ollama embeddings
embeddings = OllamaEmbeddings(
model="nomic-embed-text", # Use nomic-embed-text model
base_url="http://localhost:11434" # Ollama service address
)2- Create a new Chroma database
# 2. Create a new Chroma database
vectorstore = Chroma(
collection_name="test_collection", # Database named test_collection
embedding_function=embeddings, # Use nomic-embed-text model for vectorization
persist_directory="./chroma_db_test" # Store in folder chroma_db_test
)3- Add knowledge base documents
Here I am using Andrew Ng’s machine learning strategy, which is a practical guide for tuning machine learning algorithms and definitely worth reading word for word.
# 3. Add document example
loader = PyPDFLoader("./knowledge/Ng_MachineLearningYearning.pdf") # Load PDF document
documents = loader.load()
# 2. Document chunking
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000, # Size of each text chunk
chunk_overlap=200, # Overlap size
length_function=len, # Function to calculate text length
separators=["\n\n", "\n", " ", ""] # Text splitting delimiters
)
chunks = text_splitter.split_documents(documents)Let’s print out the chunk information to see the results:
# Optional: Print chunk information
print(f"The document has been split into {len(chunks)} chunks")
for i, chunk in enumerate(chunks[1:3]): # Print 1-2 chunks as examples
print(f"\nChunk {i+1} content preview:")
print(chunk.page_content[:200]) # Only show the first 200 characters
4- Store documents in the vector database
# 4. Add documents to the vector database
vectorstore.add_documents(documents=chunks)5- Create retriever and update retrieval tools
# Create retriever with search parameters
retriever = vectorstore.as_retriever(
search_type="similarity",
search_kwargs={
"k": 10 # Only use k parameter to return the top 10 most relevant documents.
}
)Let’s test if we can perform a normal query
# Query test
query = "How big should the Eyeball and Blackbox dev sets be"
results = retriever.get_relevant_documents(query)
print(results)OK, we have successfully retrieved results

Next, configure the Crew.ai tool
# Update retrieval tool
@tool("ChromaRetriever")
def chroma_retriever_tool(query: str):
"""Retrieves relevant documents from the Chroma vector store."""
try:
results = retriever.invoke(query)
return results
except Exception as e:
return f"Error retrieving documents: {str(e)}"
# Wrap the function as a tool
chroma_tool = chroma_retriever_toolBuild web retrieval tools
from langchain_community.tools import TavilySearchResults
from crewai.tools import BaseTool
from pydantic import Field
search = TavilySearchResults()
class SearchTool(BaseTool):
name: str = "Search"
description: str = "Useful for search-based queries. Use this to find current information about latest legal trends and news."
search: TavilySearchResults = Field(default_factory=TavilySearchResults)
def _run(self, query: str) -> str:
"""Execute the search query and return results"""
try:
return self.search.run(query)
except Exception as e:
return f"Error performing search: {str(e)}"
web_search_tool = SearchTool()Next, we are familiar with configuring intelligent agents and tasks in Crew.ai.
Agents Configuration:
retriever_agent = Agent(
role='ML Research Agent',
goal='Retrieve content related to "{query}" from the machine learning knowledge base.',
backstory=("You are a machine learning research expert, skilled at finding relevant machine learning concepts,"
" algorithms, and implementation details. You can understand complex machine learning topics and identify the most relevant information from academic papers and"
" technical documents."),
verbose=True,
memory=True,
tools=[chroma_tool],
llm=llm
)
technical_expert_agent = Agent(
role="ML Technical Expert",
goal="Generate detailed technical responses for {query} based on retrieved machine learning documents",
backstory=(
"You are an expert in machine learning with a deep understanding of algorithms, frameworks, and best practices."
" You excel at clearly explaining complex machine learning concepts and providing practical implementation guidance."
" If the retrieved document information is insufficient, you will use web search tools to find additional technical details from reliable sources"
" (such as arXiv, research papers, or official documentation)."
),
verbose=True,
memory=True,
allow_delegation=False,
tools=[web_search_tool],
llm=llm
)
validation_agent = Agent(
role="ML Validation Expert",
goal="Validate the technical accuracy and practical applicability of machine learning-related responses.",
backstory=(
"You are a validation expert specializing in machine learning."
" You are responsible for verifying the technical accuracy of machine learning concepts, checking whether code examples follow best practices,"
" and ensuring that recommendations are practical and align with the latest developments in machine learning."
" You have extensive experience in reviewing machine learning solutions and can identify potential issues or areas for improvement."
),
verbose=True,
memory=False,
allow_delegation=False,
tools=[web_search_tool],
llm=llm
)
documentation_agent = Agent(
role="ML Documentation Expert",
goal="Create clear, well-structured documentation for '{query}', including code examples and explanations.",
backstory=(
"You are a technical writer specializing in machine learning documentation."
" You excel at making complex machine learning concepts easy to understand, providing clear code examples,"
" and organizing information in an easily digestible manner. You ensure that all technical content is accurate and includes practical implementation details."
),
verbose=True,
memory=False,
llm=llm
)
Tasks Configuration:
retrieval_task = Task(
description="""
Retrieve documents related to '{query}' from the machine learning knowledge base.
Focus on:
- Core machine learning concepts and algorithms
- Implementation details and code examples
- Latest research papers and technical documents
- Best practices and common pitfalls
If necessary, reconstruct the query to better match technical terms.
""",
expected_output="A complete list of relevant machine learning documents, highlighting key technical details.",
agent=retriever_agent
)
technical_analysis_task = Task(
description="""
Analyze the retrieved machine learning documents about '{query}' and provide:
1. Technical explanation of machine learning concepts
2. Practical implementation guidance
3. Related code examples
4. Framework-specific considerations
5. Performance and optimization recommendations
Only use verified technical sources and official documentation.
""",
expected_output="Detailed technical analysis including code examples and implementation guidance.",
agent=technical_expert_agent,
context=[retrieval_task]
)
validation_task = Task(
description="""
Validate the technical response for '{query}' through the following aspects:
1. Verify algorithm correctness
2. Check if code examples conform to best practices
3. Confirm framework compatibility
4. Assess computational efficiency
5. Validate against current machine learning research
Provide accuracy scores and suggest improvements if necessary.
""",
expected_output="Validation report containing accuracy scores and technical suggestions.",
agent=validation_agent,
context=[technical_analysis_task]
)
documentation_task = Task(
description="""
Create clear technical documentation for '{query}', including:
1. Concise explanation of machine learning concepts (2-3 paragraphs)
2. Annotated runnable code examples
3. Implementation steps and requirements
4. Common questions and solutions
5. References to official documentation and research papers
Format the response for maximum readability and practicality.
""",
expected_output="Well-structured machine learning documentation containing code examples and practical guidance.",
agent=documentation_agent,
context=[technical_analysis_task, validation_task]
)Configure Crew
os.environ["CREW_DISABLE_TELEMETRY"] = "true"
ml_crew = Crew(
agents=[retriever_agent, technical_expert_agent, validation_agent, documentation_agent],
tasks=[retrieval_task, technical_analysis_task, validation_task, documentation_task],
process=Process.sequential
)Let’s take a look at the results.
user_query = "Error analysis on the training set"
results = ml_crew.kickoff(inputs={"query": user_query})
print(f"Raw Output: {results.raw}")Are there other vector databases to choose from?
Open-source vector databases in the industry include Milvus, Weaviate, Qdrant, etc. What are the advantages and disadvantages of each compared to Chroma, and what are their respective application scenarios? I have compiled a table comparing various features:
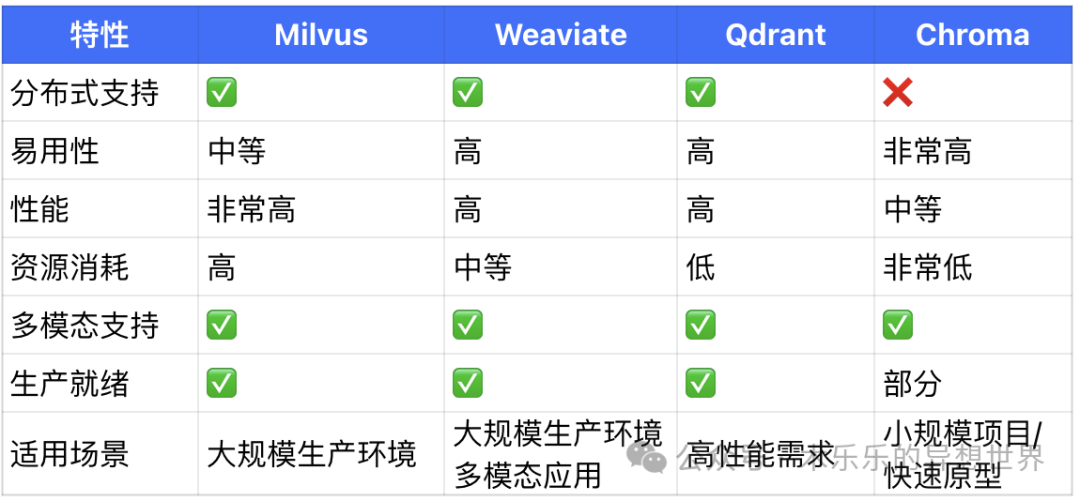
The selection of different vector databases varies. Based on the scenarios, there are these usage recommendations:
Beginners/Small Projects: Choose Chroma, quick to get started and easy to integrate.
Enterprise Applications: Consider Milvus or Weaviate, feature-rich and scalable.
Medium-sized Projects: Consider Qdrant, which balances ease of use and performance.
Multimodal Needs: Prioritize Weaviate.
Choosing the right vector database requires comprehensive consideration of specific project needs, scale, resource constraints, and other factors.
It is recommended to conduct thorough testing and evaluation before making a formal selection.