MLNLP ( Machine Learning Algorithms and Natural Language Processing ) community is a well-known natural language processing community both domestically and internationally, covering NLP graduate students, university teachers, and researchers in enterprises.
The vision of the community is to promote communication between the academic and industrial sectors of natural language processing and machine learning, as well as among enthusiasts, especially for beginners.
This article is reprinted from | NLP Workstation
Author | Liu Cong NLP
Hello everyone, I am Liu Cong NLP.
Recently, I have been working on content related to prompts. I have always felt that the prompt mechanism does not translate well into sequence labeling tasks. Therefore, a long time ago, when the team leader asked me, I boasted, saying: “Who uses prompts for NER?” However, after researching, I found that the experts really have their own tricks, and I was shortsighted. Thus, I decided to summarize and share with everyone.
Some papers have already been experimented on my data, and the last part will provide a brief overview and analyze the pros and cons of each method.
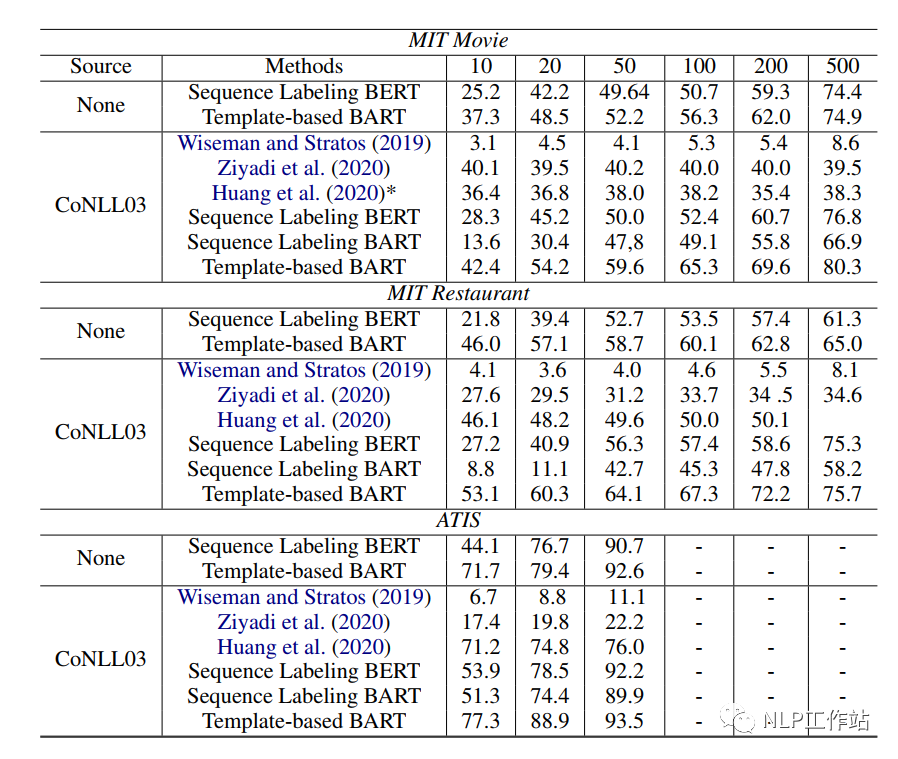
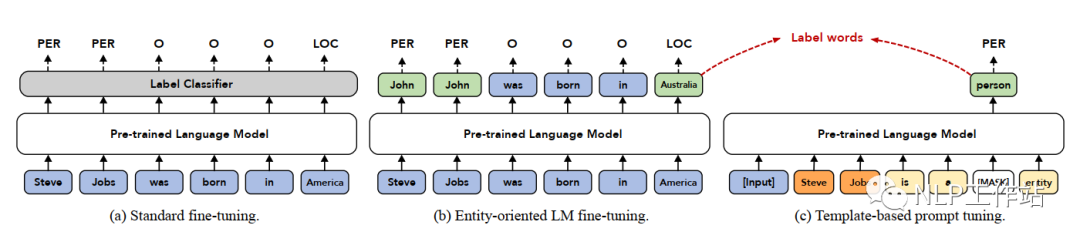
TemplateNER, original paper “Template-Based Named Entity Recognition Using BART”, is the first paper to apply the prompt method to sequence labeling tasks. The core idea is to construct candidate entities through the N-Gram method, then concatenate them with all manually created templates, and use the BART model to score them, thus predicting the final entity categories. It is a prompt paper that uses “manual templates and no answer space mapping”.
paper: https://arxiv.org/abs/2106.01760
github: https://github.com/Nealcly/templateNER
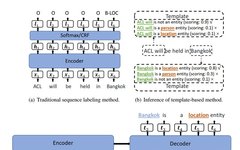
The model training phase is shown in the diagram (c), and the prediction phase is shown in the diagram (b). Below is a detailed introduction.
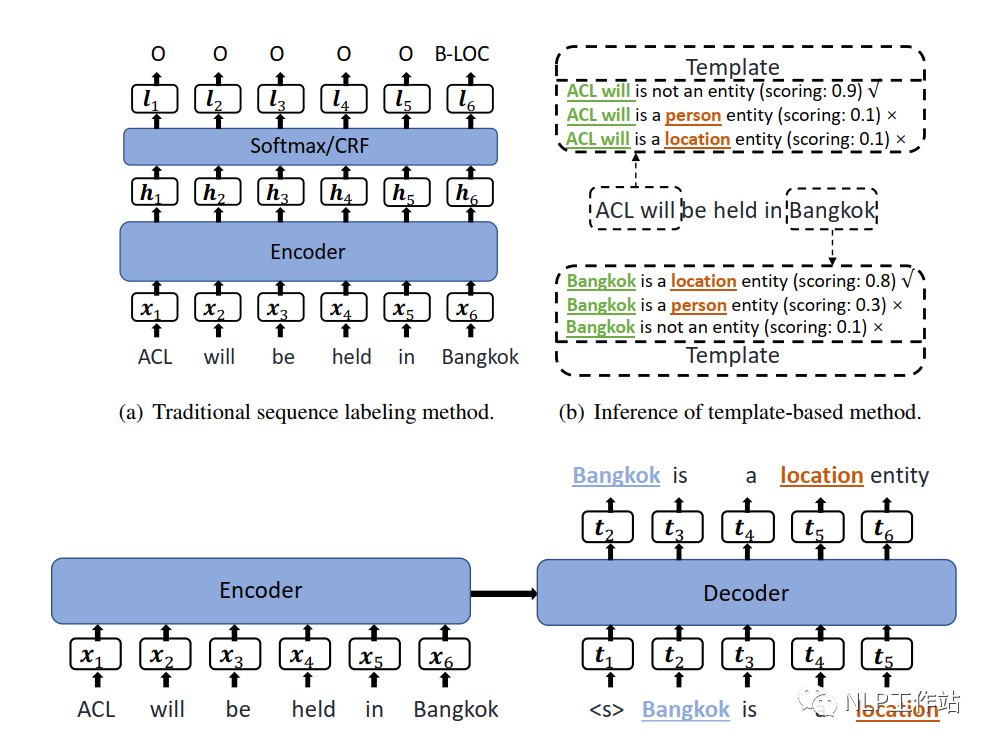
Task Construction
Transform the sequence labeling task into a generation task, where the input on the Encoder side is the original text, and the input on the Decoder side is a template text with blanks filled in. The output is the template text with blanks filled in. The content to be filled in consists of candidate entity segments and entity categories. Candidate entity segments are constructed using an N-Gram sliding window from the original text, and to prevent too many candidate entity segments, the paper limits it to a maximum of 8-gram.
Template Construction
The templates are manually created and mainly consist of positive templates and negative templates, where the positive template indicates that a text segment is of a certain entity type, while the negative template indicates that a text segment is not an entity. The specific templates are shown in the table below, and we can also see that the final model’s performance is closely related to the manually created templates.

Training Phase
In the training phase, positive samples consist of entity + entity type + positive template, while negative samples consist of non-entity segments + negative template. Due to the excessive number of negative samples, random negative sampling is performed to maintain a ratio of 1.5:1 with positive samples. The learning objective is:
Prediction Phase
In the prediction phase, all candidate entity segments with an 8-gram sliding window are combined with templates, and then the trained model is used for prediction to obtain the score for each candidate entity segment and template combination (which can be understood as semantic fluency PPL, but the calculation formula is different). The score calculation is as follows:
Where, x_{i:j} represents the entity segment, y_k represents the k-th entity category, and T_{y_{k},x_{i:j}} represents the text of the entity segment and template.
For each entity segment, select the template with the highest score to determine whether it is an entity and what type of entity it is.
DemonstrationNER, original paper “Good Examples Make A Faster Learner: Simple Demonstration-based Learning for Low-resource NER”, has the core idea of concatenating example template information with the original text to improve the performance of the original sequence labeling model. It is a prompt paper that uses “example templates and no answer space mapping”.
paper: https://arxiv.org/abs/2110.08454
github: https://github.com/INK-USC/fewNER
The model is shown in the diagram (b) below, and a detailed introduction follows.
Task Construction
It is still a sequence labeling model, only with the example template concatenated after the original text, where the role of the example template is to provide additional information (what types of entities belong to what categories, which entities belong to which categories in similar texts, etc.) to help the model better identify the entities in the original text.
Example Template Construction
Examples are divided into entity-oriented examples and sentence-oriented examples, as shown in the diagram below.
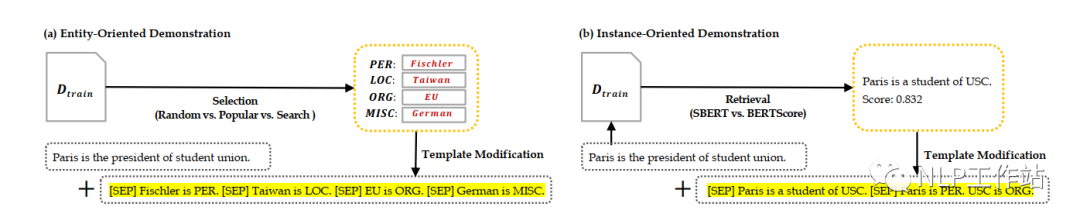
The construction methods for entity-oriented examples include:
-
Random method, that is, randomly select several entities from the training set’s entity list as examples.
-
Statistical method, that is, select entities that appear most frequently in the training set as examples.
-
Grid search method, that is, conduct a grid search on all entities to determine which entities yield the best performance on the validation set when chosen as examples.
The construction methods for sentence-oriented examples include:
-
SBERT method, that is, use the cosine similarity between [CLS] vectors as the sentence similarity score, selecting the sentence most similar to the original sentence as an example.
-
BERTScore method, that is, use the sum of the similarities of each token in the sentence as the sentence similarity score, selecting the sentence most similar to the original sentence as an example.
The template forms mainly include three types: context-free templates, context-aware templates, and dictionary templates, as shown in the diagram below.
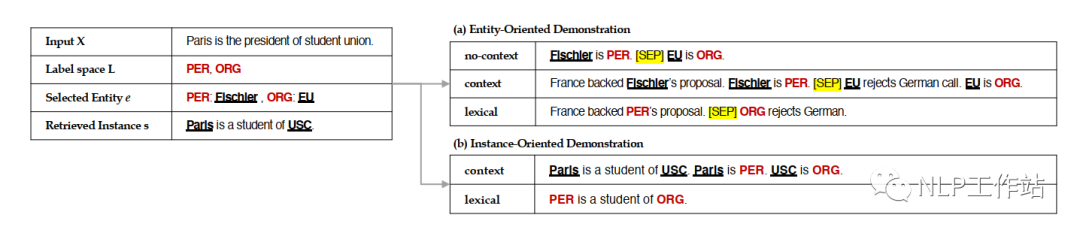
The final experimental results show that the entity-grid search method with context-aware templates yields the best performance. The poor performance at the sentence level may be due to the low similarity between sentences in the data space.
Training & Prediction
The example templates are concatenated to the original template and entered into the model together, only the original text is used for label prediction and loss calculation, as shown below:
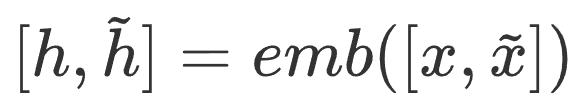
Where, x represents the original text, x~ represents the example template, h represents the sequence vector of the original text after passing through the model, and h~ represents the sequence vector of the example template after passing through the model. The loss is as follows:
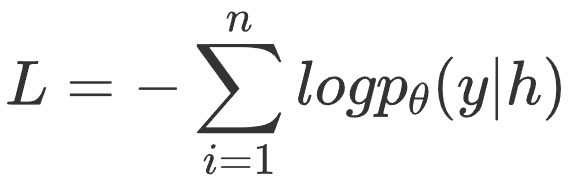
Only the original text part is considered. When domain transfer is needed, the parameters of the original model are assigned to the new model, and only the parameters for training label mapping (linear or CRF) need to be adjusted.
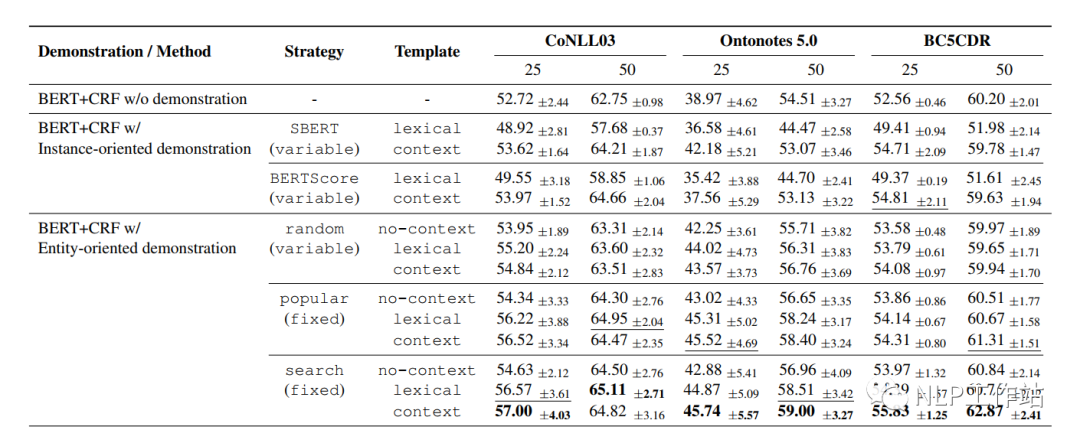
LightNER, original paper “LightNER: A Lightweight Generative Framework with Prompt-guided Attention for Low-resource NER”, has the core idea of transforming the original sequence labeling task into a Seq2Seq generation task by incorporating prompt information into the attention mechanism of the transformer, achieving good results with a small number of parameters trained. It is a prompt paper that uses “soft templates and has answer space mapping”.
paper: https://arxiv.org/abs/2109.00720
github: https://github.com/zjunlp/DeepKE/blob/main/example/ner/few-shot/README_CN.md
The model is shown in the diagram below, and a detailed introduction follows.
Task Construction
Transform the sequence labeling task into a generation task, where the input on the Encoder side is the original text, and the Decoder side generates entities and entity types character by character. The template information is integrated into the attention mechanism of both the Encoder and Decoder models, with the template being a soft prompt, which is a learnable automatic template.
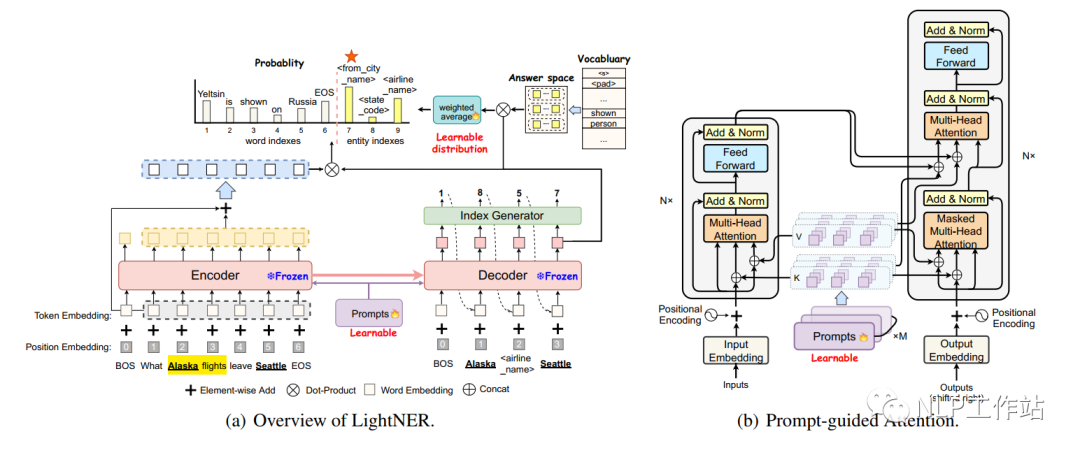
Prompt-guided Attention
As shown in the diagram (b), trainable parameters are added to both the Encoder and Decoder.
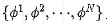
Where N is the number of transformer layers,
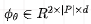
|P| is the length of the template, d is the hidden node dimension, and 2 indicates that it consists of key and value.
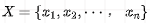
For each layer of the transformer, the original representation of X is as follows:
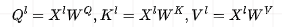
The transformed attention is as follows:
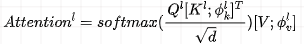
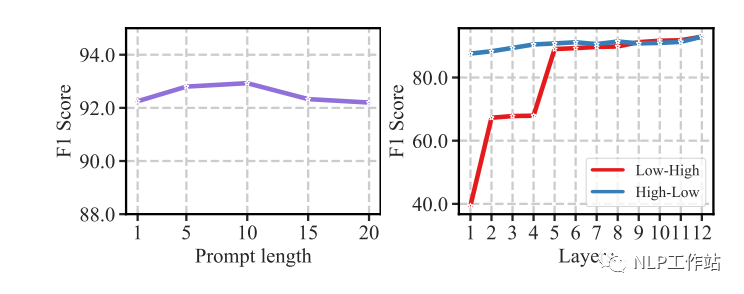
Prompt-guided Attention can readjust the attention mechanism based on the prompt content, allowing for fewer parameters to be adjusted. Moreover, experiments have shown that both the length of the template and the number of layers into which the prompt information is integrated affect the final results, with the best performance observed when the length is 10 and the number of layers is 12.
Training & Prediction
For the Encoder side, input text X, and obtain the representation:
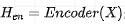 ;
;
For the Decoder side, the output y not only includes entity content but may also include entity categories, that is:
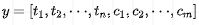
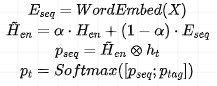
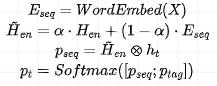
Where, p_tag is obtained through answer space mapping, specifically by “weighting the vectors of several words in the labels to obtain the answer space vector for the label”.
Ablation experiments have shown that both prompt-guided attention and answer space mapping have a significant impact on the results.
EntLM, original paper “Template-free Prompt Tuning for Few-shot NER”, has the core idea of transforming the sequence labeling task into a task consistent with the original pre-trained LM task, using only answer space mapping to achieve task transformation, eliminating the gap between downstream tasks and the original LM task, thereby improving model performance. It is a prompt paper that uses “no templates and has answer space mapping”.
paper: https://arxiv.org/abs/2109.13532
github: https://github.com/rtmaww/EntLM/
The model is shown in the diagram below, and a detailed introduction follows.
Task Construction
Transform the sequence labeling task into a task consistent with the pre-training phase, eliminating the gap between downstream tasks and pre-training tasks. Perform LM predictions on the input text, where when a token is not an entity, it is predicted as the same token as the input; when a token is an entity, it is predicted as a token under the entity category. The integration of tokens under each entity category is the construction of the answer space mapping.
Construction of Answer Space Mapping
In specific domains, it is often easy to obtain unannotated text and entity lists for each entity category, constructing pseudo-label data through vocabulary backtracking, where Y*_i represents the entity category and X_i represents the text data. Because pseudo-label data may contain a lot of noise data, four methods are used to filter candidate words in each entity category when constructing the answer space mapping.
-
Data distribution method, that is, filter out the most frequently occurring words in the corpus for each entity category.
-
Language model output method, that is, input the data into the language model, count the total probability of words in each category in the language model output, and select the top words with the highest probability.
-
Data distribution & language model output method, that is, combine the data distribution method and language model output method, scoring each word in an entity category by multiplying its frequency with its model output probability, and selecting the top words with the highest scores.
-
Virtual label method, that is, using vectors to replace words in the entity category, equivalent to category “prototypes”. The vector acquisition method is to input the high-frequency words obtained by one of the above methods into the language model to obtain the vector for each word, and then sum and average to obtain the category vector.
Since some high-frequency words may appear in multiple entity categories, causing label confusion, a threshold filtering method is used to remove conflicting words, specifically, the frequency of a word in a category divided by its frequency in all categories must exceed a specified threshold to be considered a label word for that entity category.
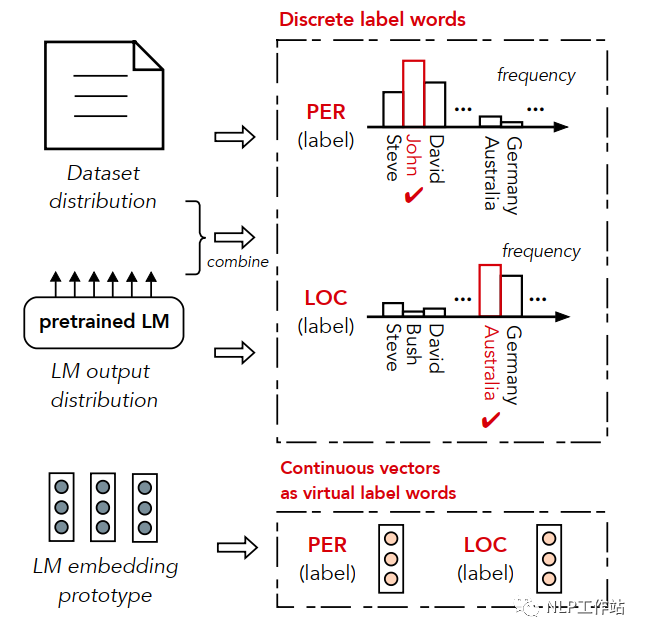
Experiments have shown that in most cases, using the data distribution & language model output method to obtain high-frequency words, followed by the virtual label method to obtain the category “prototypes”, yields the best results.
Training & Prediction
The model training phase uses the loss function of the LM task, as follows:
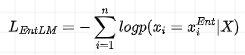
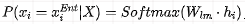
W_m represents the parameters of the LM layer during the pre-training process.

UIE, original paper “Unified Structure Generation for Universal Information Extraction”, has the core idea of transforming the sequence labeling task into a Seq2Seq generation task by combining manually created prompt templates with the original text to inform the model of the content to be extracted, and then decoding it character by character through a specific extraction format to improve model performance. It is a prompt paper that uses “manual templates and no answer space mapping”. However, UIE is applicable to all information extraction tasks, not limited to NER tasks, but will mainly use NER tasks as an example for explanation.
paper: https://arxiv.org/abs/2203.12277
github: https://github.com/universal-ie/UIE
The model is shown in the diagram below, and a detailed introduction follows.
It is worth noting that this paper on UIE is not the same as the UIE framework mentioned by Baidu Paddle (anyone who has seen the source code knows this, do not confuse them). The UIE framework mentioned by Baidu Paddle is essentially a prompt-based MRC model, using the prompt template as a query and the text as a document, extracting content segments corresponding to the prompts using Span extraction.
Task Construction
Transform the sequence labeling task into a generation task, where the input on the Encoder side is the prompt template + original text, and the Decoder side generates structured content character by character. Based on T5, pre-training techniques are employed to learn from text to structured generation.
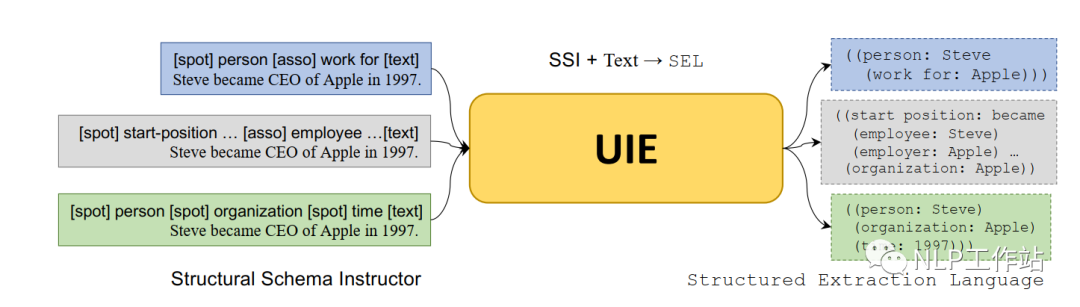
Manual Template
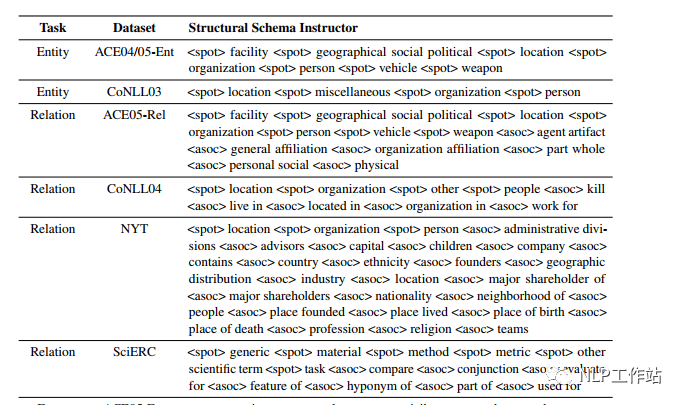
On the encoding side, construct the Prompt template through the schema to be extracted (entity categories, relationships, etc.), referred to as SSI, which controls the generated content. The template style is shown in the diagram below.
On the decoding side, a specific extraction structure is designed, referred to as SEL, which can also be considered a type of template, allowing for uniform representation during decoding. The extraction structure style is shown in the diagram below.
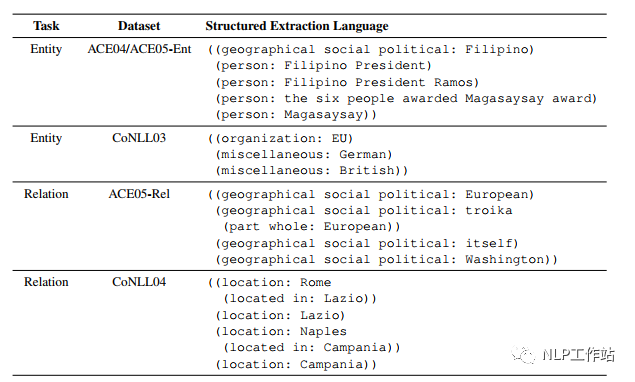
Only the Entity part needs to be focused on.
Training & Testing
For the Encoder side, input text
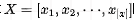
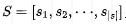
Obtain the representation:
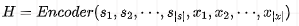
For the Decoder side, generate character by character, as follows:
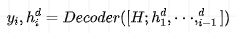
Since the format of the data to be generated in the training data follows the SEL format, the generated content will also adhere to this structure.
The model focuses on how to construct pre-training data. During the pre-training process, data comes from Wikidata, Wikipedia, and ConceptNet. The constructed data format includes three types: D_pair and D_record and D_test.D_pair is the text-to-struct parallel corpus constructed from Wikidata and Wikipedia.D_record is data that only contains structured forms.D_test is unstructured pure text data.
During the pre-training process, the three types of corpus correspond to different training losses, and the training network structure is also different. D_pair trains the entire Encoder-Decoder network structure, D_record only trains the Decoder network structure, and D_record trains the Encoder network structure. The final loss is the sum of the three.
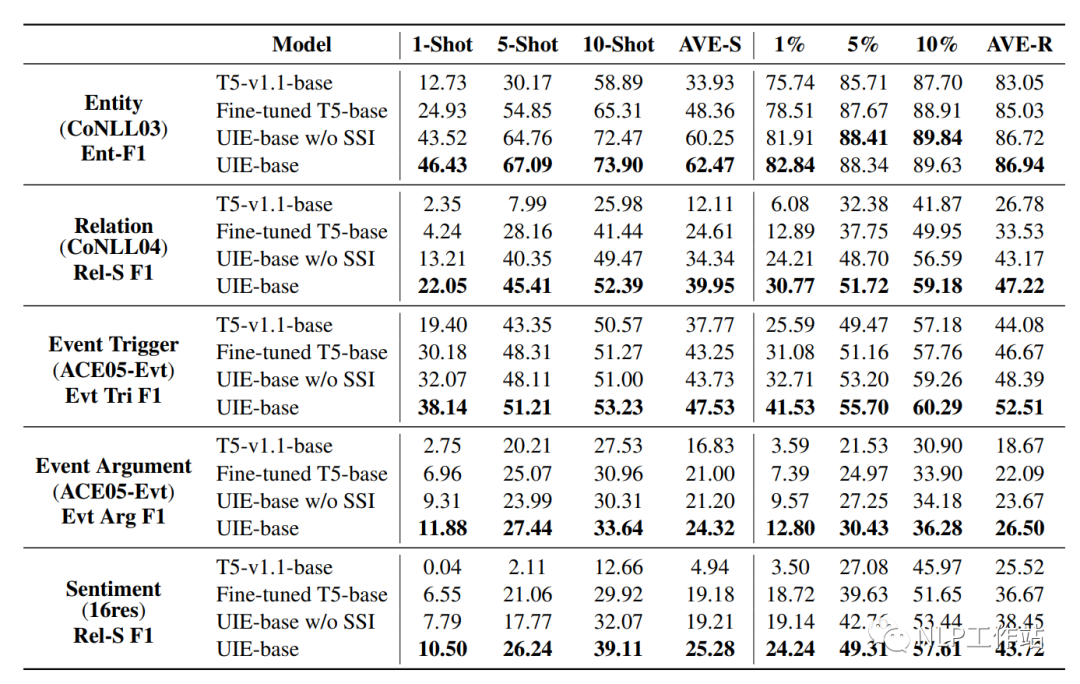
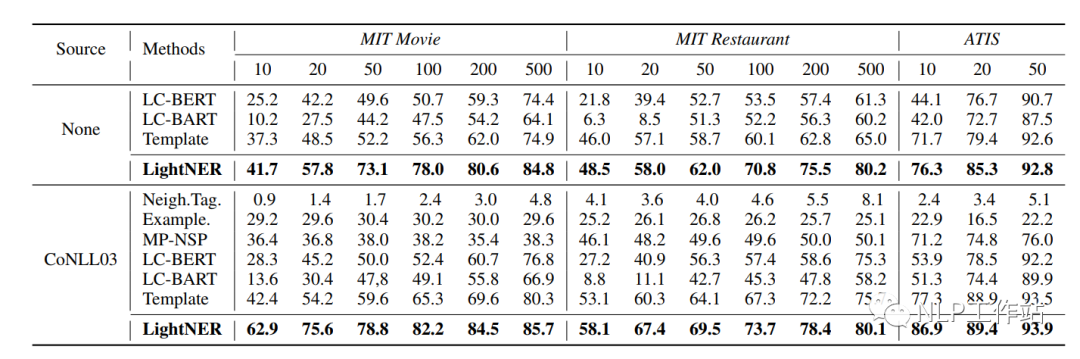
I tested the effects of TemplateNER, LightNER, and EntLM on my own Chinese dataset, and was surprised to find that when the data volume increased to 50-shot, the performance of “BERT-CRF” was the best (stop with the useless stuff, adding more data solves everything, which is also a frustrating point for me. Maybe, possibly, perhaps, it could be a problem with the dataset or code reproduction (code download error?). I am powerless to rage!!!).
At 5-shot and 10-shot, the performance of the EntLM method was better, but it is indeed strongly related to answer space mapping, and it is necessary to find good label words to achieve better results. The TemplateNER method took too long to test and cannot be implemented in industry.
Just like my previous evaluation of prompts, I never deny the value of prompts, just that it has not met my expectations. Is it that everyone else is drunk while I am sober, or that everyone is sober while I am drunk? The road still needs to be traveled, and tasks still need to be done, let’s keep going!!!
Technical Group Invitation

△ Long press to add the assistant
Scan the QR code to add the assistant WeChat
Please note: Name-School/Company-Research Direction
(e.g., Xiaozhang-Harbin Institute of Technology-Dialogue System)
to apply to join the Natural Language Processing/Pytorch and other technical groups
About Us
MLNLP Community ( Machine Learning Algorithms and Natural Language Processing ) is a grassroots academic community jointly constructed by domestic and foreign natural language processing scholars. It has now developed into a well-known natural language processing community, including well-known brands such as Ten Thousand Top Conference Group, AI Selection Exchange, AI Talent Exchange and AI Academic Exchange, aiming to promote progress among the academic and industrial sectors of machine learning and natural language processing, as well as among enthusiasts.
The community can provide an open communication platform for related practitioners’ further education, employment, and research. Everyone is welcome to follow and join us.