
Authors |
Wang Yanbo, Gui Xiaoke, Yang Xuan – China Minsheng Bank
Du Xinkai – ZTE Corporation
Lu Jiahui – Wuhan University
Influenced by multiple factors such as the current interest rate marketization, rapid development of internet finance, and the economic development entering a new era, the traditional operating model of domestic banks is facing a new transformation. How to provide customers with more convenient, higher quality, and safer service experiences based on refined management has become the focus of competition among commercial banks.
In recent years, the rapid development of FinTech technologies such as cloud computing, big data, the Internet of Things, and artificial intelligence has promoted a significant improvement in the accuracy of voice recognition. This provides important technical resources for commercial banks to introduce intelligent services. Voice recognition technology will initiate a transformation of service models in commercial banks and add new elements to intelligent services. This article organizes the development of this technology from the perspective of commercial banks and proposes a “4I” application framework for voice recognition in commercial banks, aiming to further enhance the comprehensive intelligent service capabilities of banks in the FinTech era.
1. Overview of Voice Recognition Technology
Voice recognition utilizes methods and technologies from linguistics, computer science, electronic engineering, pattern recognition, probability theory, information theory, and artificial intelligence to enable computer devices to accurately recognize and translate voice information. It is also known as Automatic Speech Recognition (ASR) or Speech-to-Text (STT) and has been widely applied in industries such as finance, telecommunications, e-commerce, healthcare, and manufacturing.
1. Development of Voice Recognition Technology
Voice recognition technology can be divided into three stages based on its development and application: early experimental research stage, practical stage, and modern voice recognition system development application stage.
(1) Early Experimental Research Stage
In the 1950s, the world’s first experimental system capable of recognizing 10 English digits was born at Bell Labs. In the 1960s, the Dynamic Time Warping (DTW) algorithm appeared, along with techniques for segmenting speech signals into frames, achieving effective speech feature extraction. In the 1980s, recognition algorithms shifted from template-based methods to statistical model-based methods, resulting in acoustic models based on Gaussian Mixture Hidden Markov Models (GMM-HMM) and language models based on N-grams, enabling the recognition of large vocabularies, non-specific speakers, and continuous speech.
(2) Practical Stage
Entering the 1990s, the framework of voice recognition systems became stable. With the rapid enhancement of computer processing power and the maturity of voice recognition in system adaptation and parameter tuning, voice recognition technology gradually found successful commercial applications, entering the practical stage.
(3) Modern Voice Recognition System Development Stage
In recent years, with the development of big data and deep learning technologies, deep learning methods have been gradually introduced into voice recognition systems, significantly improving recognition performance compared to traditional voice recognition technologies. Currently, most voice recognition systems on the market are modeled based on deep neural network models, greatly enhancing the accuracy and reliability of voice recognition across various application scenarios, marking a new phase of application for voice recognition technology.
2. Classification of Voice Recognition
Voice recognition technology is classified into two categories based on the speaker: one is speaker-dependent voice recognition, which is used to recognize the speech content of specific individuals and applies voiceprint identification technology based on the speaker’s voiceprint information for voice-based identity recognition; the other is speaker-independent voice recognition, which trains models using a large amount of voice data to achieve recognition for any speaker, making it more practical, although it is generally more challenging than speaker-dependent tasks.
Based on the different types of vocabulary objects being recognized, voice recognition tasks are divided into three categories: isolated word recognition, which can recognize pre-known words such as “deposit” and “withdrawal” and can be applied in automatic control fields; continuous speech recognition, which can recognize natural conversational continuous speech, such as a sentence or a paragraph, and can be applied in speech input systems; and keyword recognition, which detects the positions of specific keywords from continuous speech without the need to recognize the entire sentence, applicable in speech monitoring tasks.
Based on the implementation methods of recognition services, voice recognition is divided into two categories: cloud-based, which relies on the network and powerful backend models for more accurate recognition, with several cloud-based voice assistant tools already available; and offline, which does not rely on the network, making application scenarios more flexible, but the accuracy of recognition is limited by computational resources. Offline recognition generally combines dedicated chips to control the computational load at a reasonable level by compressing the model size.
3. Principles of Voice Recognition Technology
The basic process of traditional voice recognition technology is illustrated in Figure 1 and mainly includes the following content.
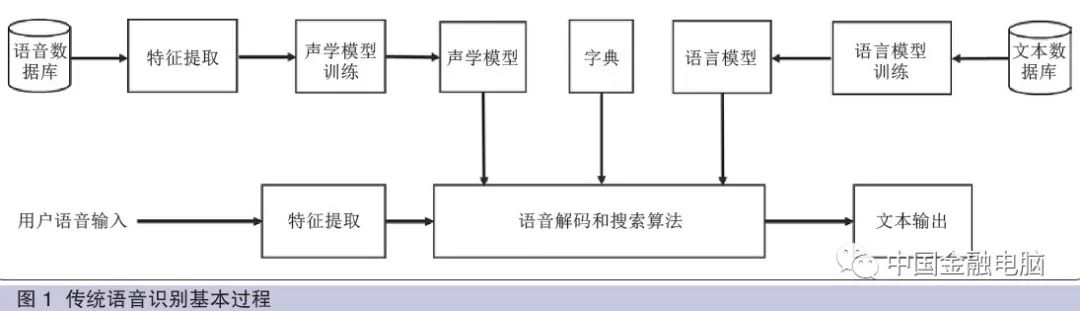
(1) Preprocessing
This process mainly includes sampling the input raw speech signal, removing background noise caused by individual pronunciation differences and environmental factors, segmenting the speech signal into short segments through framing, and using endpoint detection technology to determine the start and end points of speech.
(2) Feature Extraction
This process mainly involves extracting feature parameters that reflect the essence of the speech from the preprocessed speech signal to form a sequence of feature vectors. Typically, frequency cepstral coefficients (MFCC) are derived from the spectrum, using frames of 10ms to segment the speech waveform, and extracting feature vectors from each frame.
(3) Acoustic Model Training
Training is conducted based on a speech database, calculating the similarity between speech features and pronunciation templates to establish model parameters for each acoustic unit. During recognition, the speech feature parameters to be recognized are matched with the trained acoustic models to obtain recognition results. Most traditional voice recognition systems use GMM-HMM for acoustic model modeling.
(4) Language Model Training
Based on the grammatical rules of the language, grammatical and semantic analysis is performed on the training text database to establish a probability distribution that describes the occurrence of a given word sequence in the language, allowing the determination of the most likely next word given a set of words, narrowing the search range, thereby improving voice recognition performance and accuracy.
(5) Voice Decoding
Voice decoding refers to the recognition process in voice technology. For the input raw speech signal, after preprocessing and feature extraction, a recognition network is established by combining the trained acoustic model, language model, and pronunciation dictionary, using search algorithms to find the best path, thereby obtaining the optimal word string corresponding to the speech signal.
4. Deep Learning and Voice Recognition Technology
Deep learning, also known as “deep structured learning,” is a machine learning method based on learning data representations. By constructing multi-hidden layer neural networks, it combines low-level features to form more abstract high-level representation features, thereby improving classification or prediction accuracy.
Voice signals are a type of non-stationary random signal, and the process of human perception of them is a complex signal processing process. Deep learning can process voice signals in a hierarchical manner by mimicking how the human brain processes them, making it more suitable for voice signal processing than traditional models. By optimizing and improving relevant aspects of traditional voice recognition technology with deep learning techniques, new technologies such as Tandem System, Hybrid System, and End-to-End Model systems have emerged, described as follows:
(1) Tandem System
Using Deep Neural Networks (DNN) for feature extraction, it outperforms traditional feature-trained GMM-HMM recognition systems by jointly forming long-term feature vectors with contextual information and possessing deep non-linear transformation capabilities to extract more information from limited data.
(2) Hybrid System
Based on the GMM-HMM acoustic model, DNN replaces the Gaussian Mixture Model (GMM) to compute the output probability density function, where the DNN can be substituted with other deep learning architectures such as Recurrent Neural Networks (RNN) or Convolutional Neural Networks (CNN). This method is the most commonly used and convenient, requiring no redesign of the entire traditional acoustic model system.
(3) End-to-End Model System
Completing the entire process from input feature vector to output result based on deep neural networks, the acoustic model and language model are integrated through back-end decoding. Compared to traditional recognition processes, it does not require framing or frame-level labeling operations. The implementation methods of end-to-end models are divided into two types: one uses Continuous Temporal Classification (CTC) combined with Long Short-Term Memory (LSTM) networks to model the phoneme sequence of speech and the corresponding feature sequence at the sequence level; the other is based on Encoder-Decoder models and Attention models to directly realize the output from speech acoustic feature sequences to the final word sequences.
II. Application of Intelligent Voice Recognition Technology in Commercial Banks
With the continuous integration of voice recognition technology with text mining, natural language processing, and other technologies, voice recognition technology shows tremendous application value potential in the financial sector, represented by commercial banks. This article organizes and classifies the application scenarios of voice recognition from the perspective of commercial banks, proposing a “4I” application framework, namely “Input (Information Input) – Inspection (Real-time Monitoring) – Interaction (Communication Interaction) – Identification (Identity Verification)” to provide reference and guidance for the implementation of intelligent voice recognition technology in commercial banks.
1. Input (Information Input): “Hear It”
One major application of voice recognition is to automatically convert voice data into text data, achieving automatic information input. In this application, the primary function of voice recognition technology is to transform audio data into text data and accumulate a large amount of text information corpus for further intelligent text mining and natural language processing. In the operational environment of commercial banks, this function can primarily be applied to simplify the business operation processes of counter staff and to draft reports after customer visits by customer managers.
For example, in simplifying counter operations, current branches remain one of the crucial channels for banks to provide services. The quality of service by counter operators is a key factor determining customer experience. Feedback from customers regarding banks indicates that long waiting times have become a significant factor affecting customer satisfaction. By introducing a voice recognition system, customer needs can be directly converted into system-recognizable text content, allowing counter staff to merely verify the entered information, reducing the time customers spend filling out various documents and the time operators spend entering information, thereby minimizing customer waiting times and enhancing service efficiency. Furthermore, when frontline bank staff visit customers, the lack of dual recording devices often necessitates writing interview reports to record customer situations and conversation content. In this case, the application of voice recognition technology can directly convert the dictation of customer managers into written reports to improve work efficiency and further release bank productivity.
2. Inspection (Real-time Monitoring): “Understand It”
In addition to needing to “hear it,” many scenarios in commercial banking also require “understanding it,” meaning that during the communication process between bank service personnel and customers, it is necessary to identify customer needs and business risk points in real-time, supporting more accurate personalized service for customers while ensuring business compliance.
For example, by constructing indexing mechanisms based on voice recognition technology and introducing text mining and natural language processing technologies, real-time “listening” to the text can be searched in the “focus” word library. When customers conduct business at the counter, real-time monitoring of the conversations between customers and window personnel can timely identify the compliance of bank employees’ scripts. If business personnel engage in improper sales or illegal guidance, the system promptly alerts bank personnel with warning indicators, aiming to minimize damage to customer and bank interests. Additionally, banks can identify customer business needs in real-time and timely prompt window staff to recommend relevant products when customer needs match core keywords of the bank’s products and services, further enhancing sales success rates.
Moreover, this technology can analyze customer language texts to promptly detect whether customers exhibit negative emotions, assisting business personnel in reducing improper handling and timely regulating or resolving potential customer disputes during business processing.
3. Interaction (Communication Interaction): “Have Interaction”
In addition to the aforementioned “hear it” and “understand it,” voice recognition often requires “having interaction” with customers. With further technical support such as voice synthesis, directional sound positioning, semantic understanding, and machine translation, voice recognition technology can be applied in self-service machine operations, telephone banking auto-response, automatic callbacks from bank call centers, service interactions with lobby robots, and enhancing services for foreign customers. For example, in optimizing the self-service functionality of lobby devices, self-service machines have become an important means of diverting customers during lobby operations.
Currently, self-service device operations primarily rely on touch operations and manual input to assist customers in business processing, generally requiring dedicated personnel to guide customer operations. The introduction of intelligent voice recognition technology can further optimize self-service device functions, responding correctly to requests, commands, or inquiries recognized in speech, overcoming drawbacks such as slow manual input and errors, while also shortening system response times and making human-machine interactions more convenient.
Applying voice recognition technology to digital channels such as mobile banking and WeChat banking can further enhance customer experience in interactions with the system, completing basic business operations such as balance inquiries, account loss reporting, mobile number transfers, transfer fee inquiries, appointment withdrawals, bill inquiries, credit card repayments, points inquiries, and credit card loss reporting, reducing the amount of information customers need to input, increasing customer stickiness to the channels, and effectively enhancing customer experience while saving service costs.
Additionally, enhancing services for foreign customers is another promising application scenario for intelligent voice recognition technology. Using lobby or window service robots as a carrier, voice recognition technology can implement “simultaneous interpretation,” enabling banks to better serve foreign customers, enhancing customer satisfaction while providing technical support for banks to better layout international strategies and develop overseas businesses.
4. Identification (Identity Verification): “Recognize It”
Voice recognition technology can also achieve customer identity verification through voiceprint recognition. In biometric recognition applications, voice-based identity verification features non-contact, non-invasive, and strong usability, making it easily accepted by customers. Voiceprint recognition can directly identify customers through each person’s unique voice, eliminating the need for setting, remembering, and entering passwords, while offering greater convenience and friendliness compared to methods such as facial recognition, iris recognition, fingerprint recognition, and finger vein recognition, making the identity verification process quick and straightforward. Leading commercial banks abroad have begun exploring voice identity verification. In May 2013, Barclays Bank in the UK announced the use of voice recognition technology to verify customer identities within 30 seconds through ordinary conversation. Furthermore, by establishing a customer voiceprint database and identifying voiceprints in speech, banks can effectively recognize customers, query historical records, and conduct information retrieval and recommendations.
Undoubtedly, voice recognition technology provides new technical options for the operational and customer service models of commercial banks and can further enhance business efficiency and explore new business operation models. In recent years, voice recognition technology has developed rapidly, but its application in domestic commercial banks is still in its infancy. This is mainly due to the insufficient maturity of the domain-specific corpus in the banking sector, which hinders the realization of intelligent voice recognition in a true sense. As big data technology continues to develop and data accumulation becomes increasingly substantial, the corpus in the banking sector will gradually improve, and the application of voice recognition technology in commercial banks will gradually deepen.

Source: China Financial Computer, 2018 Issue 5
Taobao Official Website: https://shop160045533.taobao.com
¥25
Welcome to Subscribe