
Hello everyone, I am Xiao G.
As we all know, with the deepening of smart finance in the business processes of financial services, the digital construction of the financial industry is not only aimed at external customer services and sales but also involves upgrading internal supportive systems.Intelligent compliance and intelligent operations are widely applied in internal financial management systems, reimbursement systems, accounting systems, and auditing systems, promoting data accumulation, accelerating process efficiency, and achieving a closed loop in digital construction.
In various scenarios covered by intelligent operations, artificial intelligence technologies such as computer vision, natural language processing, and traditional machine learning algorithms are fully utilized.Among them, text recognition technology (OCR) is one of the main directions of computer vision, and its recognition targets include scanned contracts, seals, ID cards, forms, and structured information from bills, playing an important role in business processing, risk control, internal database construction, and information support.
 Image: OCR Application in Intelligent Operations
Image: OCR Application in Intelligent OperationsScenario Challenges
In these scenarios, image data is obtained through scanning paper documents and bills on one hand, and through photographing certificates on the other hand.There are both scenario challenges and technical difficulties:
-
Text occlusion, blurriness, and high curvature in seal recognition scenarios, with various types of seals;
-
Text-dense scanned documents, where detection misses and recognition accuracy greatly affect subsequent key information extraction systems;
-
Perspective transformation, overexposure, underexposure, and colored shadows when photographing ID cards;
-
Diverse types of forms with significant differences, lack of open-source data, and no labeling tools;
-
Challenges in table recognition based on image processing and rules, with poor generalization;
-
Precision issues with end-to-end algorithms for curved text and speed issues with two-stage algorithms need to be balanced.
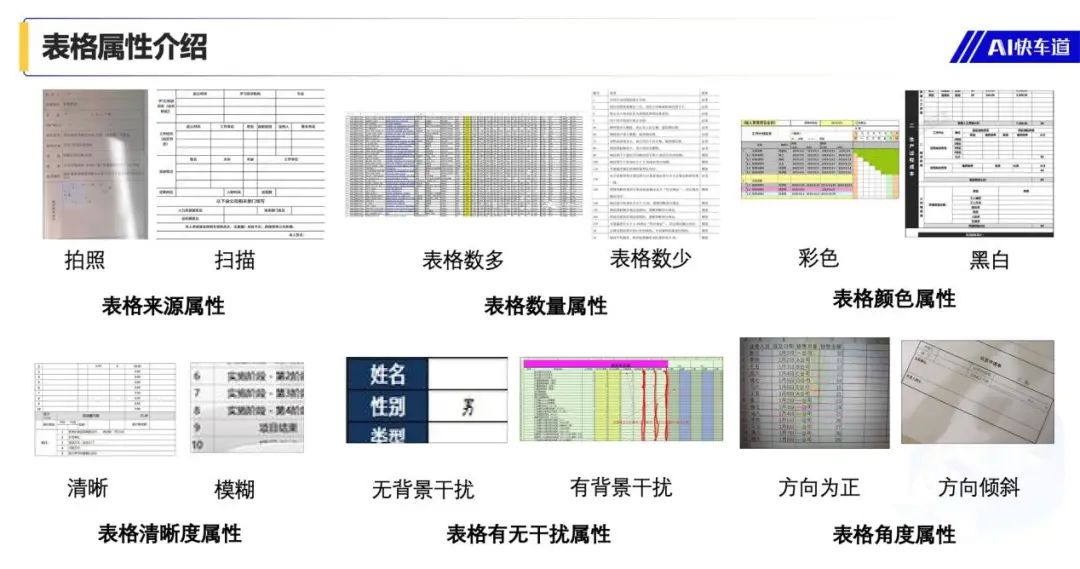
Image: Diversity of Data Types in Table Recognition
Solutions
A good algorithm model is the primary factor in solving the above problems, which requires that the algorithm model not only meets the business needs for recognition accuracy of a certain type of object but also possesses good generalization ability.
The PaddleOCR text recognition development kit provides an industry-level ultra-lightweight general OCR system PP-OCRv3 for OCR tasks in natural scenes. Trained on massive data, it achieves industry-level SOTA and has been widely validated in industries such as manufacturing and transportation.
For document scenarios, it provides an intelligent document analysis system PP-Structurev2, achieving table recognition, key information extraction, layout analysis, and recovery tasks.

Image: Application Effect of PP-OCRv3
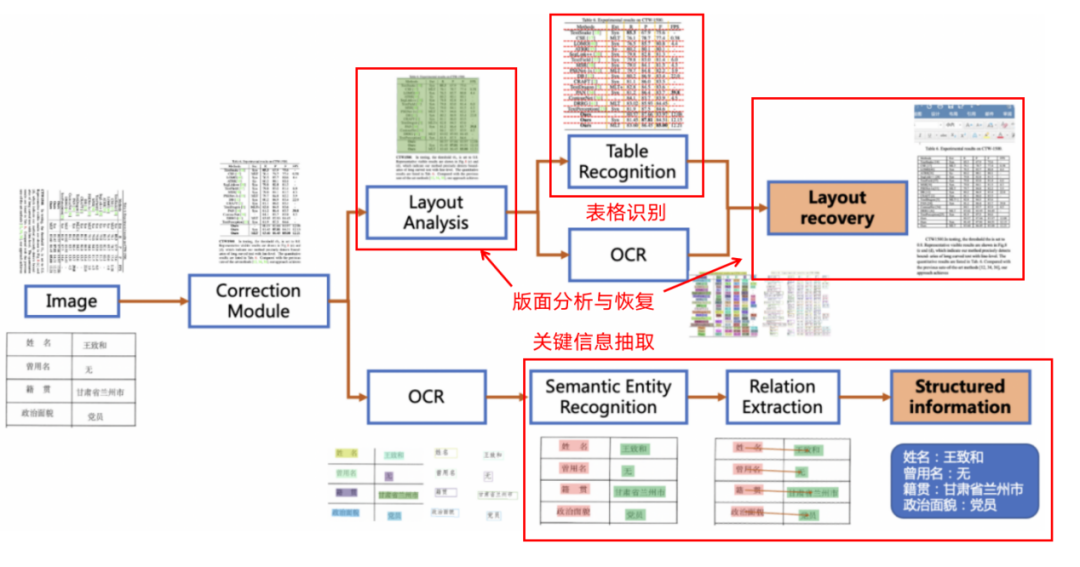
Image: PP-Structurev2 Document Analysis Flowchart
Scenario Applications
Scenario 1: Curved Text Detection and Recognition of Seals
Seal detection and recognition is the task of locating the position of seals in contract documents and common bills, extracting and recognizing the content of the seals. It can be used to detect whether there are seals in contract documents and bills, compare the seal contents, and verify business risks. In actual business, the method of manual review and comparison is costly and inefficient.
In order to reduce costs and increase efficiency,based on the PaddleDetection and PaddleOCR development kits, seal detection and seal text recognition tasks are implemented, replacing manual recognition, reducing costs, assisting in seal comparison and verification business, improving verification efficiency, and reducing business risks in the process of fiscal taxation and contract signing.
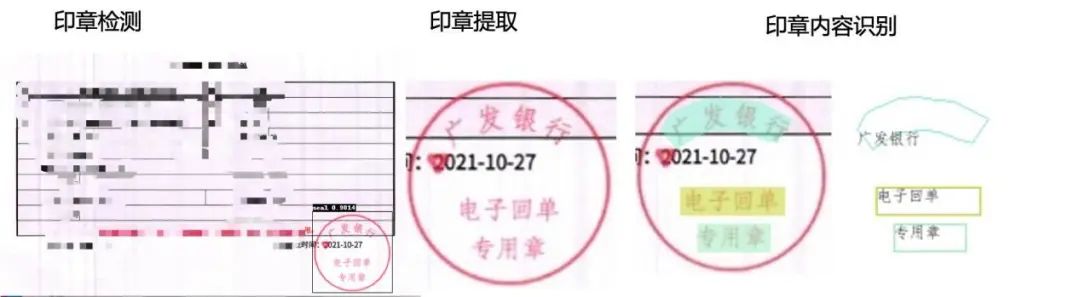
Image: Seal Text Detection and Recognition
Scenario 2: Key Information Extraction from Scanned Contracts
Contract review is widely applied in large and medium-sized enterprises, listed companies, securities, and fund companies, and is an important task to avoid risks. In actual business, manual review of paper contracts is costly and labor-intensive.
For the above scenarios, PaddleOCR + PaddleNLP can quickly extract text content,and with minimal data fine-tuning, accurately extract key information, efficiently complete contract content comparison, compliance checks, and risk point identification tasks, improving efficiency and reducing risks.
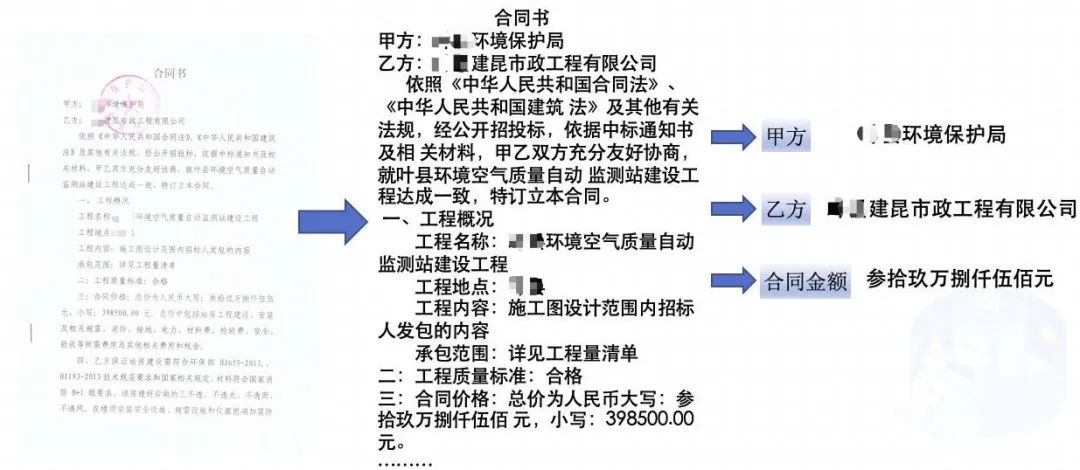
Image: Key Information Extraction from Scanned Contracts
Scenario 3: General Card and Certificate Structured Information Extraction
Card recognition applications are widespread in banks, insurance, securities, trusts, and various financial institutions, where it is necessary to recognize ID cards, bank cards, driver’s licenses, business licenses, etc., in business processing and information verification scenarios.Due to the diverse sources of data collection, various noise exists, such as interference from image orientation confusion, reflections, blurriness, and tilting issues, and structured output of card information is generally required.
For the above issues, based on PaddleClas and PaddleOCR, card orientation and type classification, multi-scheme card detection comparison and recognition are completed, with H-Means achieving over 93% accuracy.

Image: General Card and Certificate Structured Information Extraction
Scenario 4: Chinese Table Recognition and Attribute Analysis
Chinese table recognition is widely used in insurance claims, financial report analysis, and information entry scenarios. In actual business, manual entry is costly, and the lack of open-source Chinese table datasets also limits the development of Chinese table recognition models.
For the above situations,by adopting data labeling, data synthesis, and fine-tuning methods for scenario adaptation, while combining table attribute recognition, the Chinese table recognition tasks can be completed quickly.
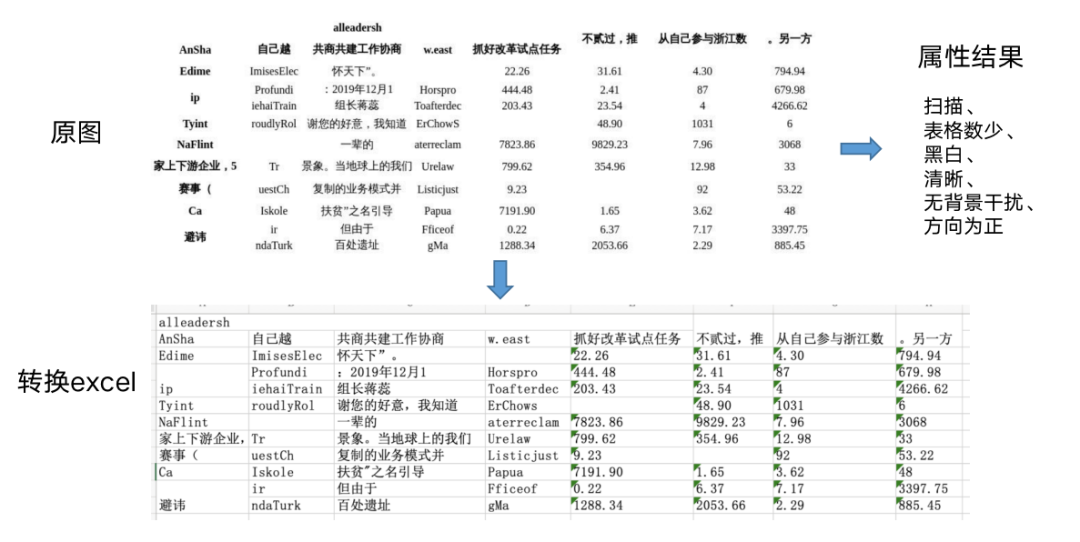
Image: Chinese Table Recognition and Attribute Analysis
More Content
In addition to providing industry-level feature models PP-OCR and PP-Structure, PaddleOCR connects the entire application process from data synthesis and labeling, model training to inference deployment. It offers 22 training and deployment methods, a semi-automatic labeling tool PPOCRLabel, the electronic book “Hands-On Learning OCR“, and rich scenario applications and cutting-edge algorithms, helping the industry quickly implement OCR applications through a full-process development experience.
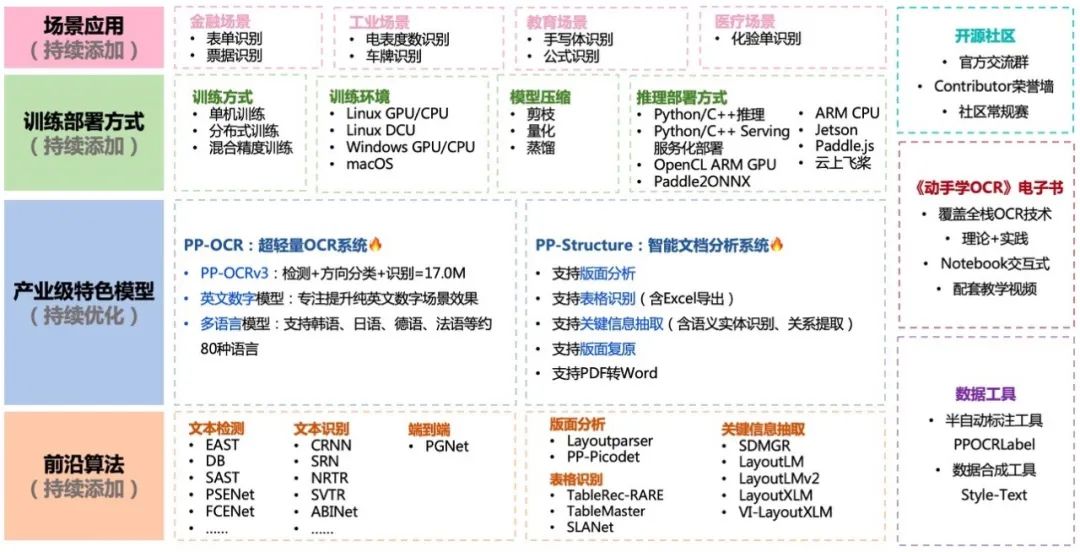
Image: PaddleOCR Overview
Course Preview and Group Benefits
To further accelerate the integration of artificial intelligence and innovation in the financial technology industry and its implementation, Baidu PaddlePaddle collaborates with Baidu Intelligent Cloud to hold a series of industry experience sharing courses themed “Riding the Wind, AI Empowers Smart Financial Innovation Development”, which includes 4 weeks of systematic courses, 4 mainstream scenarios, and 10+ fully open-source practical examples, inviting industry experts to discuss the future development of technology finance and share industry practices.
On September 15 (Thursday) and September 20 (Tuesday), Baidu R&D engineers and external partners will jointly share courses on intelligent operations in the financial industry. Limited slots are available, and interested friends can scan the code to reserve a course:
Scan to sign up for the live course and join the technical exchange group

More Exciting Content to See First

More content can be referenced at the following links:
PaddlePaddle Official Website:https://www.paddlepaddle.org.cn
PaddleOCR Project Address:
Github: https://github.com/PaddlePaddle/PaddleOCR
Gitee: https://gitee.com/PaddlePaddle/PaddleOCR
Appendix: “Riding the Wind, AI Empowers Smart Financial Innovation Development” series course poster (if you have already scanned the code to join the group, you have successfully registered, no need to repeat the operation)

Note: The above images are sourced from the internet